
My work involves mining information from text, mostly from scientific journal articles in the PubMed/MEDLINE collection of documents. PubMed/MEDLINE contains references to about 23 million articles in the domain of biomedical science, broadly construed. R is a programming language that is becoming very popular, and I love it. It’s not necessarily the first language that I would think of for text processing–nowhere near, in fact–but there are some “libraries” or “packages” that give it some nice abilities in that area. In a previous post, we had a little tutorial on the pubmed.mineR package. In this one, we’ll look at a package called rentrez. For more information about rentrez, see the documentation here.
The purposes of the two packages are quite different. Pubmed.mineR helps you process documents once you’ve gotten them–rentrez helps you get them in the first place. It is intended for querying National Library of Medicine databases in general. One of those databases is PubMed/MEDLINE, and we’ll concentrate on that functionality here.
The most basic rentrez function for our purposes is the one that lets us search an NCBI database. This function is entrez_search(). At a minimum, it takes two arguments: the name of the database that you want to search, and a set of search terms. The name of the database will go in a variable called db, and the set of terms will go into a variable called term. Let’s try it. Note that we can print the variable to which we assigned the results of the search, and it will give us useful information:

I’d like to have some indication of whether or not I can broadly have faith in the results, so let’s try an easy form of metamorphic testing–we’ll change something for which we can predict in a general way (a) whether or not there should be a change in the results, and (b) the trend of the results. I’m going to try a query that (a) should give me a different set of results, and (b) has the property that I expect it to give me a smaller set of results, specifically.

Indeed, the result set is (a) different, and (b) smaller, so I can move forward with some assurance that something sensible is going on behind the scenes.
All of this has been blazingly fast so far. However, rentrez is apparently only returning us 20 of those thousands of PMIDs. The retmax argument will let us change that–as the name suggests, it defines the maximum number of results that you want to get back.
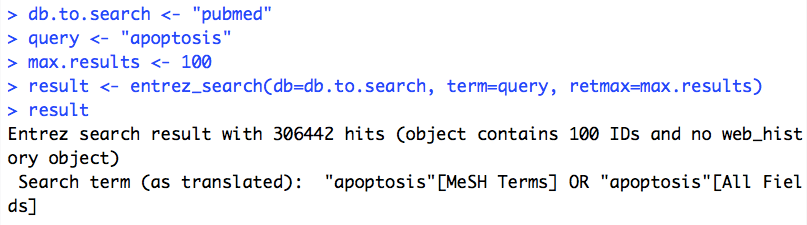
Still blazingly fast. However, when we try to turn the retmax up to a realistic value, things don’t go so well:

Let’s try a little experiment to see what an acceptable value for retmax is (or, more accurately, the smallest unacceptable value). Here’s a little experiment:

Here are the results:
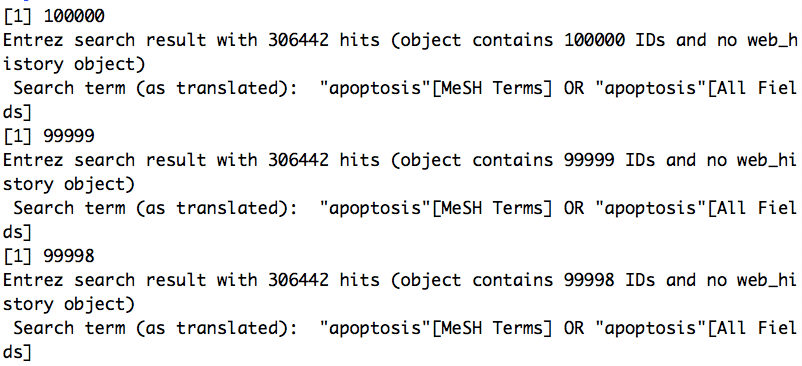
It looks fine! What the heck? I have no clue. [See below for a comment from one of the rentrez creators about this.]
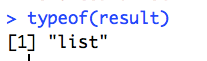
Let’s look at the results object in a bit more detail. It’s a type of R data structure called a list:
We can get the keys of the list with the summary() command:

Here’s what those actually are:
- $ids: a vector of the PubMed identifiers. (Explain what the rest are.)
- $count: how many PMIDs are returned by the search. Note that this has no necessary connection with the size of $ids. While $ids tells you how many PMIDs could be gotten in response to this query, $count tells you how many have actually been returned. If you don’t change the value for $retmax (see immediately below), it won’t be any more than 20.
- $retmax: what the retmax variable (see above–it controls how many PMIDs you get back) was set to.
- $QueryTranslation: the query with any modifications that PubMed/MEDLINE might have made to it, such as adding synonyms or MeSH terms.
- $file: from the documentation: “either an XMLInternalDocument xml file resulting from search, parsed with
xmlTreeParseor, ifretmodewas set to json a list resulting from the returned JSON file being parsed withfromJSON.”
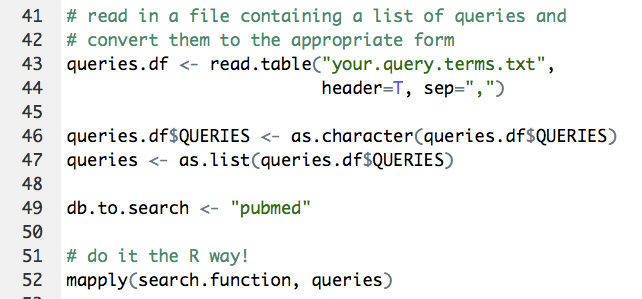
Don’t underestimate how much work rentrez saved us in identifying and retrieving those documents. I’d like to save you some work myself, so here’s a little script that I wrote to read in queries from a file and write the resulting PubMed IDs to their own files. (If you use it for a publication, please cite this blog post.) You’ll want a text file containing the queries, one per line, with the header QUERIES:

We set the whole thing up with a couple of function definitions:
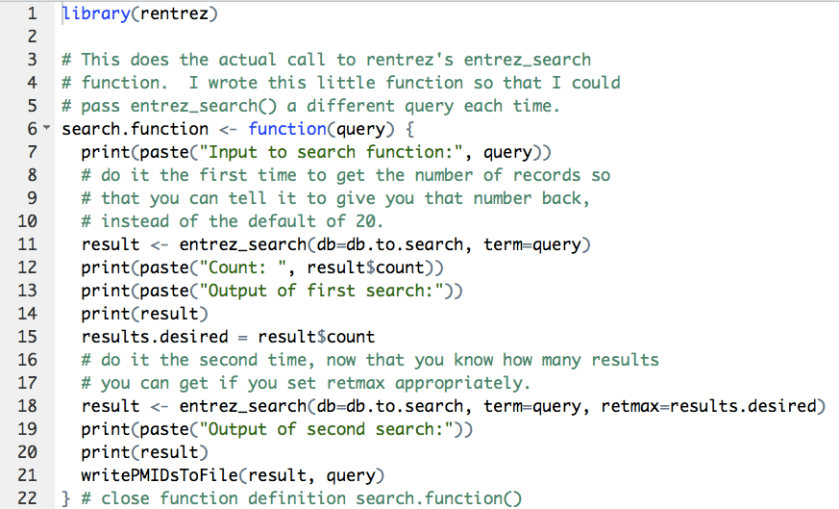
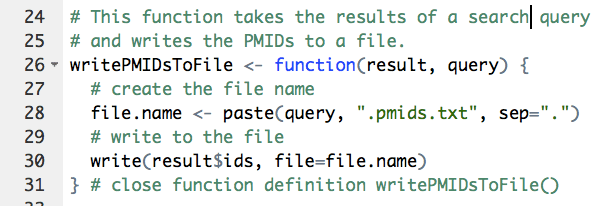
Now do the work:
[Note: I wrote to one of the creators of the package about the odd behavior when retmax is set to 100000, and got this response: “This behaviour with retmax is very odd. Diffing a little, I suspect the 100,000 is being represented as 1e5 when the API call is being built. I will test this and report it as a possible bug to the maintainer of the package that’s handling all of that internally.” He also had the following comment on large result sets: “For using very large queries, if you want to do anything other than download a list of IDs it’s probably a good idea to use the webhistory features (https://cran.r-project.org/web/packages/rentrez/vignettes/rentrez_tutorial.html#using-ncbis-web-history-features) these makes talking back and forth w/ NCBI much quicker.”]
