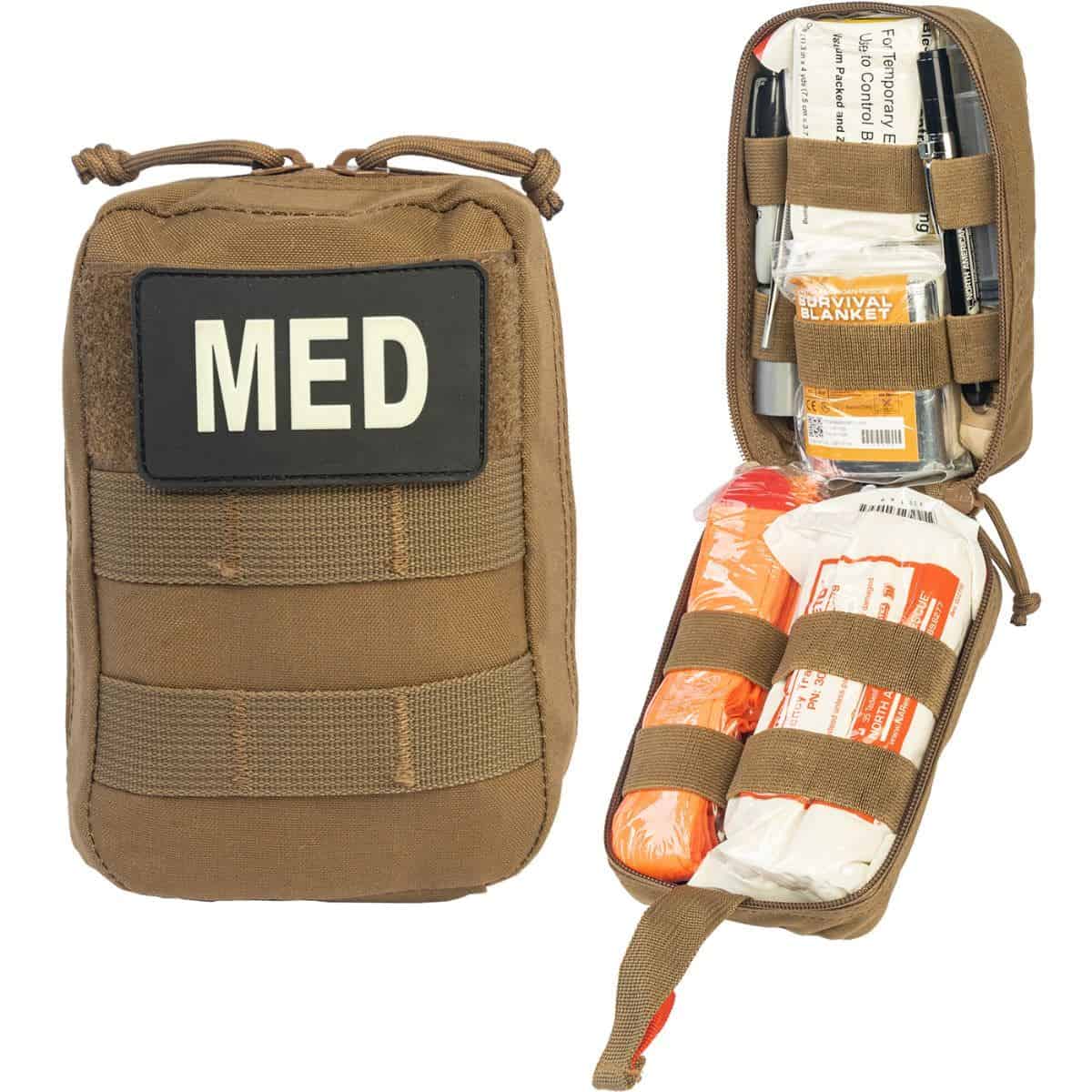
As I write this (not long after the ruzzian missile and drone attacks on Ukraine of Chrismas 2024 and New Year’s Day 2025), there are many brands and styles of tourniquets available on the market. I am a combat medic (військовий парамедик) in Ukraine, so donors often ask me which kind to buy. This letter to a friend and supporter in the United States is the answer. The executive summary: do buy the Dnipro Gen 2 or the CAT Gen 7. Don’t buy the SOF-T or the Sich. If you’re just looking to learn some new English vocabulary, you will find it in the English notes section at the end of the post. You will also find donation information there, if you would like to support our work.
Hello, my dear! You asked me what kind of tourniquets to buy for our boys and girls at the front. Thank you for asking. People like to buy tourniquets, and I get it– it is obvious, and I think obvious on a visceral level, that they are life-saving.
There are two good options for tourniquets, and one that isn’t terrible. I will tell you the two good options:
- The CAT (Combat Application Tourniquet) Gen 7, by North American Rescue. These typically sell for $30-35 retail, or $22 with a humanitarian discount from the manufacturer.
- The Dnipro Gen 2, by a Ukrainian manufacturer. These go for $22 retail, or $14 in bulk.
They are both excellent tourniquets. I carry the Dnipro Gen 2 for my own personal tourniquets. You might hear people complain about the first generation. The second generation is great–as I said, it’s what I carry for my own use. The retail prices are obviously hugely different, with the Dnipro Gen 2 being significantly less expensive. The Dnipro Gen 2 has an additional advantage: you don’t have to shlep them from the US.
The option that isn’t terrible is to buy the shittiest models that you can find. We call them “Chinese tourniquets,” which is probably unfair to China–I think the North American Rescue CATs are made in China, too. Amazon is currently selling a pack of eight of these things for $23. What you have to be aware of is that we only use them for training. For training, we really like them! The reason that we like them for training is that you can tell people that their quality is so poor that they should never, ever carry them until you’re blue in the face, but it mostly doesn’t get through. On the other hand, if they see a few of them break in a training course, they get it. So, on the medical logistics chat, you will see messages like this: “Anyone have Chinese tourniquets, the shittier the better? I need them for a training course.” So, it’s not a bad idea to bring a few of these. But, personally, I only bring them if I have a bit of space to fill in a duffle bag, and a bit of my weight allowance to spare.
Let me tell you about a couple of other kinds of tourniquets on the market. I most definitely do *not* recommend spending any money on them. They are variants on the same design, called a SOF-T (I think it stands for “Special Operations Forces Tourniquet”). Rather than using a pair of “wings” to hold the windlass (rod) in place, SOF-Ts have a metal clip at one end that you flip over the end of the windless, locking it in place at the tip of the clip. They will most certainly stop bleeding, and with that clip and a strip of duct tape, that windlass is never going to be dislodged. But, there are three problems with them, and the third is a really big one.
- They are really hard to put on with one hand. It is crucial to be able to put on a tourniquet with one hand–including with your non-dominant hand–if you have a serious wound in your own arm, and you have to put on your own tourniquet yourself. It’s possible to self-apply these, but it’s pretty tough to do so even when you’re not bleeding to death in the dark. In contrast, the CAT/Dnipro design does not have that problem.
- When put on over winter clothing, SOF-T-style tourniquets are more likely not to achieve adequate compression pressure than they are to achieve it, and they have a tendency to slip off of winter clothing. The CAT/Dnipro design is much less likely to do this. (Here’s a link to a paper on the topic of tourniquet use over winter clothing.)
- Most people are not trained to use them.
#3 is by far the biggest of these problems. There must be dozens of thousands of people in UA who have been trained to use the North American Rescue CAT/Dnipro Gen 2-style tourniquets. (One humanitarian group claims to have trained over 100,000 people themselves.) In the US, there is a popular course called Stop The Bleed, in which anyone and everyone can get trained to use the NAR/Dnipro-style tourniquet. (If you haven’t taken that course: it’s the minimum that ANYONE should have before coming to UA.) But, it would be rare for a training course to include using the SOF-T design–personally, I have never taken such a course, and I have never heard of anyone teaching one. To me, it seems like absolute foolishness to distribute a tourniquet that the statistical equivalent of no one knows how to use, when there are excellent tourniquets that many thousands of people have been trained to use.
The issue of the SOF-T style of tourniquet comes up here a lot because there is a competing Ukrainian-made product called the Sich tourniquet. It is of the SOF-T design, and it is aggressively marketed/advertised. As a medic, I ask you not to spend donated money on Sich tourniquets–see issues 1-3 above.
Finally, a few words on colors. Tourniquets are typically available in three colors: black, orange, and blue. They work identically, and are of identical quality–only the color differs. Black is meant for situations where you don’t want to be seen, so they are what we carry. In contrast, orange is meant for when you want to be seen. The orange tourniquets are intended for civilian use. In a civilian context, they’re great, because when you get a casualty to the hospital, it is easy to see that there’s a tourniquet in place, so even if the fact that the person has had a tourniquet placed gets lost in the communicative shuffle of turn-over to hospital personnel, the very visible color brings it to the staff’s attention. Finally, blue is for training. In this context, the purpose of the color is simply to remind you that it’s one of your training tourniquets, and no one should be carrying it. (Tourniquets are single-use items, so you need separate TQs for training and for actual use. I don’t have any blue ones, so I mark mine with a Sharpie as тренування (training)).
Regards, and thank you for all that you do to keep us alive and kicking during this war of ruzzian aggression,
Your friend Zipf
English notes
turnstile: this is a thing that is used to control access to an area. You will see them in subway stations, train stations, etc. You pay, a set of bars turns, and you can walk through the thing to get where you are going. I bring it up here because it is far and away the most common translation error that I see in Ukraine (Far and away explained in the English notes). To wit: the Ukrainian word турнікет, pronounced much like the English word tourniquet, is often translated as turnstile. So, you will often see requests like this in the medical logistics chat group: Need 10 turnstiles for a recon platoon. To an English speaker, this is uninterpretable.
There is a perfectly good reason for this common translation mistake: the Ukrainian word турнікет most properly means turnstile. There is a natively Ukrainian word for tourniquet: джгут (unpronounceable in English–it’s something like the English word jute, but with an h inserted after the j.) However, the word джгут is now used primarily to refer to the constricting band that a medic puts on your arm when drawing blood or starting an IV, while турнікет is used to refer to the tourniquets that we use to control massive hemorrhage. For the many readers of this blog who don’t speak French, I will point out that tourniquet means turnstile in French, too. Turnstile in Spanish is torniquete, in Czech it’s turniket–English is the oddball here.)
far and away: this means “by a large amount.” Merriam-Webster gives this definition for it: by a considerable margin. As far as I know, it functions as an adverb and appears with an adjectival phrase. Here are some examples of its use:
- A return of ruzzian troops to their own homes would be far and away the easiest way to end the war in Ukraine.
- putin’s assumption that Russian speakers identify as ruzzians and would welcome his invasion of Ukraine was far and away his greatest mistake. Instead, tens of thousands of them rushed to join the Armed Forces and protect Ukraine.
- ruzzia’s utter disregard for the lives of its own troops has always been, and remains today, far and away its most powerful weapon. In contrast, Ukrainians’ intelligence is far and away its most powerful weapon.
to wit: this phrase introduces a specification of something more general. Merriam-Webster defines it as that is to say or namely. Here is an example of it in use, with an analysis of the generality and the specification:
- A tug-of-war over Ukrainian identity (and history) has taken place in some fashion between Kyiv and Moscow since Ukraine’s independence in 1991 — and in earnest since Russia’s 2014 invasion. Nevertheless, this contest has intensified dramatically since the start of the Kremlin’s “special military operation.” To wit, Moscow has intentionally targeted Ukrainian schools, according to Ukrainian sources, in order to hit “soft targets” and disrupt education in Ukraine.(Paraphrased for clarity from an article by Ilan Berman.)
- The general statement: the fight over Ukrainian identity has intensified since the start of the full-scale invasion in February 2022. The specification: To wit, Moscow has intentionally targeted Ukrainian schools.
My name is Kevin Bretonnel Cohen. I am a combat medic (військовий парамедик) in Ukraine. If you would like to support the Ukrainian Humanitarian Resistance non-governmental organization (501(c)3, EIN 99-4530777), PayPal to kevin.cohen@gmail.com works fine, as does Zelle to 303-916-2417. If you use PayPal, please be sure to choose the friends and family option, so that your donation does not get deducted from my Social Security check. However you choose to help, please be sure to add a message with your contact information, so that I can thank you!
All views expressed in this post are my own.