One of the more interesting books that I’ve read over the course of the past couple years was Michael Erard’s Babel no more: The search for the world’s most extraordinary language learners. It is a book about polyglots and polyglossia–people who speak a lot of languages (as opposed to linguists, who are people who study language in general).
Erard is an actual linguist, and knows what he’s talking about. One of the points that he makes that I found interesting is that there’s no single recipe for learning a “second language”–in his travels amongst the polyglots, he found that people who are into this kind of thing figure out what works for them, and it’s not necessarily the same approach for everyone.
So: I’m going to show you how I prepare for my annual trip to Guatemala, where I volunteer with a wonderful group called Surgicorps. (We provide free specialty surgeries for people for whom the almost-free national health care system is still too expensive.) But, don’t feel like it’s a magic recipe (am I mixing metaphors here?) for success–just know that it has been working for me for the past few years, and there’s something that will work for you. (Which might be this!)
For context: Spanish is a “second language” for me–one that I can function in for my daily life, and professionally. But: because I spend at least half of my life in the French language and only speak Spanish when I go to Guatemala, it’s very difficult for me to not mix French into my Spanish incessantly. (As I believe Erard also points out: the difficulty is not learning a bunch of languages–the difficulty is keeping them apart.) Consequently, on July 1st of every year since I started spending As Much Time As Possible in France, I cut French out of my life completely. En contrepartie, on July 1st I start doing the same kinds of things in Spanish that I would normally do in French–listening to the news on the way to work, learning my daily vocabulary words, reading The Walking Dead comics, etc.
I also put together a schedule of everything that I need to work on between July 1st and July 30th. If you’re unfortunate enough to have been reading my blog for the past couple years, you saw me do this for the month before I took my French C1 test. The main difference is that for the CEFR exams, I need to include “written production” in the things that I work on–for my volunteer work in Guatemala, I don’t need that, because I almost never need to write anything in Spanish. So, for Guatemala preparation, I have four main categories of things to focus on:
- Vocabulary: technical (medicosurgical)
- Vocabulary: general
- Grammar
- Oral production
Why do I have an entire “section” for general vocabulary? Because as I’ve written about before, that’s the biggest challenge. Medical vocabulary is finite–there are only so many body parts, surgical procedures, etc. It’s the general vocabulary that gets you–remember that Zipf’s Law reflects the fact that languages are full of words that almost never occur, but, they do. When the guy comes to the hand surgeon with two mangled fingers hanging there uselessly, the first question that the surgeon asks him is going to be what happened, and the answer to that could be anything.
- A snake bit me
- I got a cactus spine stuck in my palm
- The fuel pump caught fire and exploded while I was in the passenger seat
- Two guys tried to steal my car and they went after me with a machete
…all of which I have run into.
So, I expand out my vocabulary study into these categories:
- Vocabulary: technical (medicosurgical)
- Areas of the hospital
- Surgical techniques and equipment
- anesthesia
- anatomy
- the hand (because I mostly work with a hand surgeon)
- gynecology (because I don’t interpret for the gynecologists very often, and therefore like to make sure that I give the terminology a once-over since I don’t have occasion to use it much)
- the face and head (because we always have multiple plastic surgeons with us)
- Vocabulary: general
- the Guatemalan regional dialect (lots of fun loan words, mostly from one or another of the 20+ Mayan languages spoken in the country)
- professions (see this post for why that gets a day of its own)
- farm work and other kinds of manual labor (because most of our patient population consists of children or manual laborers–see this post)
- animals and plants (see above about “anything can happen to your hands”)
I split grammar into three topics:
- Conjugation (because when in doubt, I’ll conjugate Spanish verbs as if they were French, and that does NOT work)
- Usted forms of verbs (they get a day of their own because it’s the form that I should be using with patients and their family members, but I almost never use it in my daily life)
- The subjunctive (much easier in Spanish than in French because it gets used far more often in Spanish, so you don’t have to think about it as much–my French problem is that I use the subjunctive too often)
Now, I know you’re wondering: why do I have oral production on my list, and why don’t I have oral comprehension? Oral comprehension is the hardest part of learning any language for most people, and oral production is what most anglophones find the easiest part of learning Spanish. The answer goes back to Michael Erard: the hard part is not learning more than one language–the hard part is keeping them separate.
This comes into play for me in two ways. One way will be familiar to anyone who has two foreign languages running around in their heads: when you don’t have a word that you need in one language, it’s hard not to substitute it with the word from the other.
The other way that French interference in Spanish works out for me is more subtle, and it’s purely a question of oral production: it’s very difficult for me to say sequences of sounds in Spanish that would not be possible in French.
A problem context that comes up quite often is possessive pronouns followed by vowel-initial nouns. For example (English followed by formal/informal French and then formal/informal Spanish):
| your eye |
votre œil |
ton œil |
su ojo |
tu ojo |
| my artery |
votre artère |
ton artère |
su arteria |
tu arteria |
Francophones will note that artère is feminine, but it has the masculine form of the possessive pronoun–mon. No huge surprise to students of French–any vowel-initial noun takes the masculine, consonant-final, form of words like possessive pronouns. Where the problem comes up: when I have to say one of those words before a vowel-initial noun in Spanish, my tongue stops. It’s like it runs into a wall–my mouth just stops moving. What the fuck??
From a linguist’s point of view: I’ve developed my own little foreign-language phonology. In languages other than my native one (American English), that little phonology really does not like sequences of vowels at the end of one word and the beginning of the next. So, I need to say tu abuelita, your grandma, but my phonology really, really wants it to be tun abuelita, or something of that ilk, which does not exist in Spanish… and my vocal apparatus just comes to a halt.
Solution: oral production drills. Focussed drills, not just making myself speak–that will happen in Guatemala, where I’ll show up a week before the rest of the team to get those Spanish-language juices flowing. I’ll put together exercises for myself that focus on the specific things that I know I have trouble getting out of my mouth, et voilà. For example: ¿le duele todavía su axila? (Does your armpit still hurt?) Ya hablamos con su abuela (we already spoke with your grandmother). Both of those are short sentences that force me into saying the vowel + vowel sequences–in these cases, su axila (your armpit) and su abuela (your grandmother) that are so hard for me.
 So, you take all of those individual things to work on, mix ’em up to give yourself a little variety in your daily study. Prioritize things in a way that makes sense for what you plan to be doing with the language–I have a day in there for learning the vocabulary of food and beverages, but that’s more so that I can translate the menu for my fellow volunteers than for the actual volunteer work, so it wouldn’t make sense to be working on that first, and I don’t. Mix in some review days–review is essential, and you don’t want to do it all at the end. Boum, as the French kids say–a month’s-worth of work. I’ll start it on July 1st, and I’ll finish it sitting in the plane on the way to Guatemala on the 30th. If I screw up and miss a day? Not the end of the world–I’ll make it up. If I just can’t stand anesthesia vocabulary on July 11th? No problem–I’ll just switch a couple days around. Is the list intimidating? No–the opposite. I know that if I prepare, everything will probably go fine, and I know that if I work my list, I’ll be prepared–so, it’s actually reassuring, not intimidating.
So, you take all of those individual things to work on, mix ’em up to give yourself a little variety in your daily study. Prioritize things in a way that makes sense for what you plan to be doing with the language–I have a day in there for learning the vocabulary of food and beverages, but that’s more so that I can translate the menu for my fellow volunteers than for the actual volunteer work, so it wouldn’t make sense to be working on that first, and I don’t. Mix in some review days–review is essential, and you don’t want to do it all at the end. Boum, as the French kids say–a month’s-worth of work. I’ll start it on July 1st, and I’ll finish it sitting in the plane on the way to Guatemala on the 30th. If I screw up and miss a day? Not the end of the world–I’ll make it up. If I just can’t stand anesthesia vocabulary on July 11th? No problem–I’ll just switch a couple days around. Is the list intimidating? No–the opposite. I know that if I prepare, everything will probably go fine, and I know that if I work my list, I’ll be prepared–so, it’s actually reassuring, not intimidating.
Why no days for working on oral comprehension? Because that’s what listening to the news on the way to work, podcasts while I stretch, etc., are for. That really has to be part of your daily life–you can’t partition that off into specific days. Gotta work, work, work your oral comprehension. On the good side: not one second of the time that you spend doing it will be wasted.
English notes
a couple versus a couple of: this is controversial amongst English speakers. People who prefer a couple of are likely to complain about those of us who say a couple. Je les emmerde. How I used it in the post: If I just can’t stand anesthesia vocabulary on July 11th? No problem–I’ll just switch a couple days around.
ilk: maybe acabit in French? How I used it in the post: My phonology really, really wants it to be tun abuelita, or something of that ilk, which does not exist in Spanish… I think in French something of that ilk would be quelque chose du même acabit, or words to that effect. Phil d’Ange?
The picture at the top of this post is from lolphonology.tumblr.com. I picked it because in the post I carped about sequences of sounds, and the meme is about sequences of sounds (one in particular–the sound of the ch in English chat, but more on that another time, perhaps). You don’t get it? No worries–that just means that you’re cool, not nerdy like some stupid linguist.





















 (Twitter, @TheSuperAmanda)
(Twitter, @TheSuperAmanda)
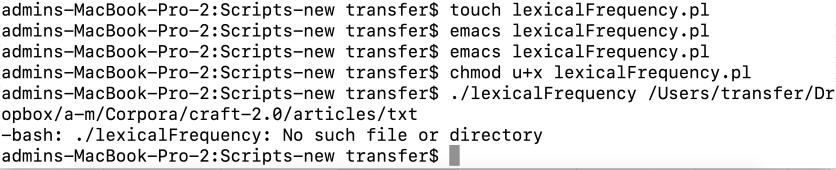






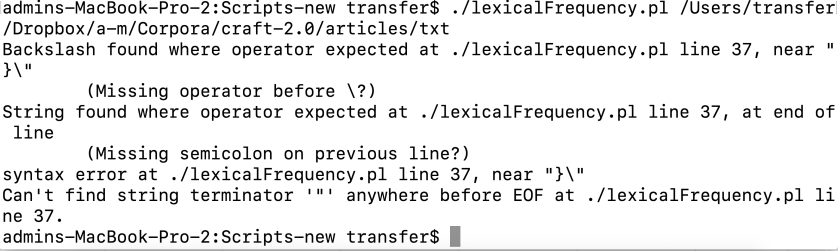




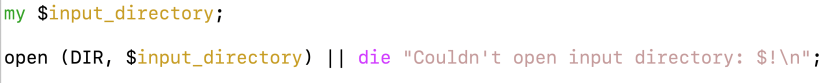
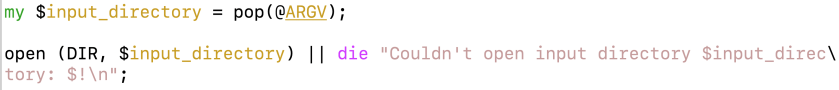




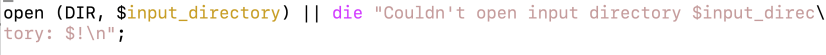 …when I shoulda written this:
…when I shoulda written this: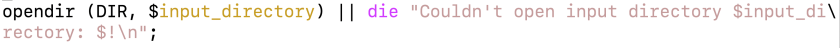





 You know how the matching game works: we have words in English, words in French, and we match them. Today’s words (and a tiny bit of grammar) are taken from the discussion of Zipf’s Law in the book
You know how the matching game works: we have words in English, words in French, and we match them. Today’s words (and a tiny bit of grammar) are taken from the discussion of Zipf’s Law in the book