Twenty-plus years ago, I got my first job as an actual, card-carrying linguist, working for a company that did things with big collections of linguistic data, using them to improve computer programs that did speech recognition, i.e. figuring out what words a person is saying.
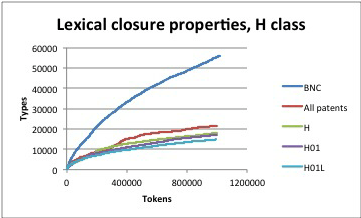
One fine day the people that gave us the vast majority of our income sent their big-collection-of-linguistic-data specialist to visit us. We demonstrated to him the computer program that we had built to answer the question how can you tell when a big collection of linguistic data is big enough? We pointed out how to spot the tell-tale sign on a graph that means “it’s big enough.” “Oh, that just means that linguistic data is bursty.”

What did he mean by “bursty?” We had a guess, but weren’t exactly sure, and given that his company paid us a lot of money and he was their expert, my boss thought it best not to push back. A few months later, they declined to renew our contract, and our owner laid everyone off and went away to do something else. Was it because we didn’t push back on the big-collection-of-linguistic-data expert’s dismissiveness? Probably not–our little company committed far bigger errors, and on a sadly regular basis. Whatever–the job market for computational linguists was not terrible in those days (it’s pretty wonderful now), and I found my second job as an actual, card-carrying linguist pretty quickly. But: burstiness is pretty important, and it continues to bump into my life today, in various and sundry ways, some of which will be of interest to readers of this blog.
What burstiness means: per Wikipedia,
In statistics, burstiness is the intermittent increases and decreases in activity or frequency of an event.
Wikipedia, Burstiness
In plain English: burstiness is present when something doesn’t happen for long periods of time, but then happens a lot, and then goes back to not happening very often. Some things that have this characteristic: hurricanes, and pandemics. Statisticians care about burstiness because bursty things are difficult to characterize with normal statistics, so you have to come up with new techniques to work with them; people like disaster planners and public health experts care about those statistics because it is difficult to predict, and therefore to plan for, things that have weird statistical properties.
From a computational linguist’s perspective, burstiness is important because in big collections of language, you don’t see new words very often, but when you do, sometimes you see a lot of them at once. If you’re trying to do something like build a dictionary for a computer program, you typically do that by finding all of the words in a big collection of linguistic data. But, how do you know when your collection of linguistic data is big enough? See above; the problem is that if you kept growing the collection, you know that there will be bursts of new words, but you can’t keep growing your collection forever–at some point, you have to stop and work with what you have at hand.
Many of our dear fellow readers are engaged in learning a language that they don’t already speak. I am one of them–if you have been reading this blog for a few years, you have followed my feeble attempts to learn la langue de Molière, also known as “French.” By now I know the language well enough that I can pick up a book in it and not have to turn to a dictionary very often. But, when I do, it typically happens like this…
Right at this moment, I’m reading Paris brûle-t-il ?, “Is Paris burning?,” the work of reference on the liberation of Paris. I typically get through about three pages before I have to look up a word. But, then this morning, I’m reading about the French 2nd Armored Division rolling from Normandy to Paris when I come across this sentence. I had to look up all of the words in bold face:
Glissant en silence sur leurs six roues de caoutchouc, les automitrailleuses des spahis à calots rouges, “chiens de chasse” de la division, ouvraient la marche.
Dominique Lapierre and Larry Collins, Paris brûle-t-il ?, published by Robert Laffont in 1964.
- l’automitrailleuse: a light armored vehicle.
- le spahi: native cavalry trooper of the Maghreb.
- le calot: garrison cap in English; when I was in the Navy, we called them “cunt caps.” A calot has no brim or visor, and therefore can be folded flat and tucked under the epaulet of a military jacket.

After that, it was back to my normal rate: about one word every three pages. That certainly counts as “not very often,” and is pretty good for a non-native speaker. To then jump to three words in a single sentence, and then go back to my base rate of one word every three pages, is a good example of burstiness. Once again, we see why one might right a blog like this one–a blog about the statistical properties of language and their implications for people who are trying to learn one. What happened to the dismissive big-collections-of-linguistic-data expert? I don’t know for a fact, but I do know that people who are dismissive of the opinions of others don’t typically have much professional success. Personally, I took what I learned from the experience of working at a failed software start-up to do a better job of being a computational linguist, and have had a wonderfully fun time with it. Want to try a career in computational linguistics yourself? Start here if you are not a graduate student, or here if you are, and I hope you have as much fun with it as I have!
French notes:
Despite what its name would lead one to think, an automitrailleuse does not necessarily carry a machine gun. Here some pictures of modern automitrailleuses. You’ll notice that some of them look a lot like tanks. The salient differences are that (1) they weigh less, and (2) they have wheels, not treads.