In practice, we spend most of our time trying to figure out where we went wrong in writing some computer program or another.
Tell someone that you’re a computational linguist, and the next thing out of their mouth is likely to be either:
- How many languages do you speak?, or…
- What’s that?
In theory, computational linguists spend their time thinking about fun questions like:
- Is natural language Turing-complete?
- The relationship, if any, between what we know about words (say, the word dog can be a noun or a verb, and it occurs more often with the words bark and leash than with the word meow) and what we know about the world (say, a dog is a canine, and might like to chase balls, and will eat cat shit if not instructed otherwise).
- How Zipf’s Law, which describes the fact that a small number of words are extremely common, while a large number of words are extremely rare, but do occur, might or might not be related to the mathematical phenomenon of the fractal.
In practice, we spend most of our time trying to figure out where we went wrong in writing some computer program or another. (OK: that, and writing grant proposals.) Think that being a computational linguist sounds glamorous? Here’s how I spent my morning.
All I gotta do: go through a bunch of documents and count how often each word in that bunch of documents occurs. Easy-peasy–barely hard enough for a homework in Computational Linguistics 101.
Seulement voilà…
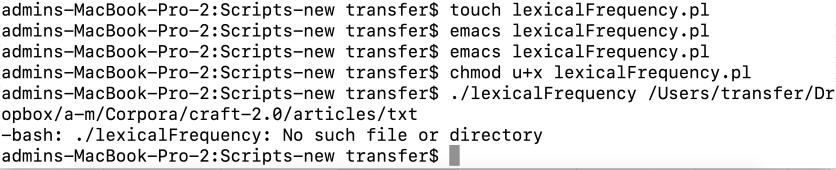
Easy enough to fix–I just failed to give the complete name of the program, and…. marde.

OK, easy enough to fix–I had written

…when I shoulda written

Shoulda: the typical spoken form of should have.
(Note the square bracket near the end of the middle line–I had left it out.) Great–avançons, alors. But, no, fuckashitpiss:

Easy enough to fix–turns out I wrote this:

…when I shoulda written this:

(Note the dollar sign before the rightmost instance of words now.) And so, on we go, but…
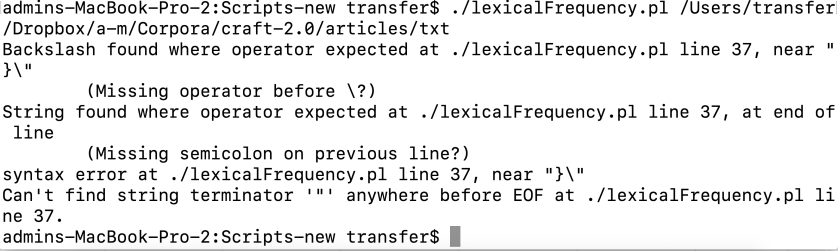
…and it’s easy enough to fix–I had written this:

…when I shoulda written this:

(Note the double quote before $frequencies{$words[$i]}\n”;) …and now I’m wondering:
- These errors were all on one single line–what other horrors have I hidden in this code, and will they be as easy to find as those were?
- What the hell was I thinking when I wrote that line? Was I thinking about the upcoming dissertation defense at 2 PM? Was I thinking about Trump giving my country to China? Was I thinking about tomorrow’s colonoscopy? Who the hell knows, really–whatever it was, it apparently wasn’t this line of code…
Mais returnons… Ah marde, but at least this one will be easy to fix…

…except that I verify the existence of the directory, and then get this:

…which is the exact same error that I got before. So, I go back and look at my code, where I see this, and remember that my error message is supposed to print out the name of the directory that it couldn’t open, but it did no such thing:
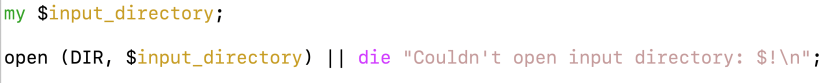
…which is ’cause I never gave the program the name of the input directory. So I take care of that, and also tell my program to print out the name of the directory that it couldn’t open if, it fact, it can’t open a directory–as we saw above, I had planned to do this, but of course left out that little detail:
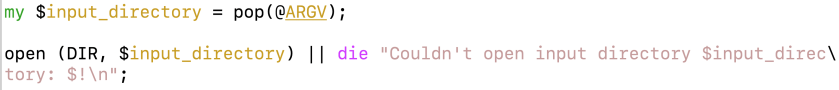
…and now I experience a tiny little bit of success, because my program does not crash. Seulement voilà, it doesn’t actually produce any ouput:

Note the lack of a bunch of lexical frequencies… So, I go back to my script, and I start looking around in the region of the program where I meant for the output to happen. I don’t see anything obvious in that area, so: I go further up in the code, and start doing what I need to do to convince myself that the earlier parts of the program are working the way that I intended them to. This means printing out the results at intermediate steps of the processing. The resulting code (leaving out a bunch of details) looks like this:

…which does nothing different than it was doing before, so I know that I need to go even further up in the program and, again, print stuff out as I go, resulting in this:

…which, when I run the script, produces this:

…which suggests to me that the directory exists, and that I’m opening it correctly, but that I am either (a) reading its contents incorrectly, or (b) making a mistake when I make a decision about whether or not to open each file. A quick Google search finds the problem for me–I had written this:
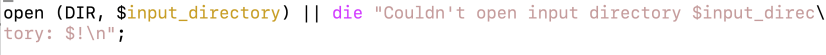 …when I shoulda written this:
…when I shoulda written this:
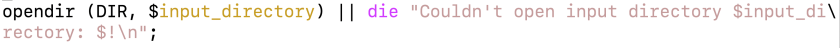
(Note that the text at the left end of the line was open, and now is opendir.)
Progress! Now I get some output, but note the last line–I’m just getting a bunch of file names, and no word frequencies. I can see the problem right away, though–I have the directory name right, and I have the file name right, but I need to combine them in order to be able to open the file. Doing so gives me this code:

…which results in my script running successfully for a while, but then crashing, and I know exactly what causes said crash…

…and I know that it’s a bear to fix, and I’ve been working on this fucking task that’s barely difficult enough to make a good homework assignment for two hours, and now it’s time to go to the aforementioned dissertation defense, and… Soupire…
Meme source: https://imgur.com/gallery/fzbkRI8





















 (Twitter, @TheSuperAmanda)
(Twitter, @TheSuperAmanda)









