The web, and the shelves of your local bookstore, are full of resources for getting introduced to the French language. Once you get to a more advanced level, it’s much more difficult to find good materials. One that I like is the 7 jours sur la planète app. Available for the iPhone and for Android, 7 jours gives you the following, every week:
3 TV news stories
For each story:
the film clip,
an audio recording of the story,
its transcription, and
a selection of words from the story with monolingual definitions (i.e., definitions in French).
There’s also a vocabulary-learning game, although I’ve never really figured out how to use it in any amusing sort of way.
The topics of the news stories are always topical. (Is that a tautology? I think maybe it is, but can’t think of a better way to say it.) This week’s topics are:
As one of the reviewers on the Apple App Store pointed out, the words that they select to define are often not the ones that you would want. For example, in the story on the Malian festival, the words that the app defines include attaque, festival, lutte, and quartier, all of which I would think you would learn in French 101. However, the story also includes échassiers, fanfare, investir, orphelinat, and couche, all of which seem to me to be more advanced, and none of which get defined. (The word orphelinat is obscure enough that it actually appeared in a previous post on this blog.) However, since the whole thing is transcribed, it’s not difficult to identify words that even as a more advanced speaker, you might not know, and to then look them up elsewhere.
l’échassier (n.m.): wading bird; tall, skinny person
la fanfare: brass band; fanfare
investir: to flood (several other meanings)
l’orphelinat (n.m.): orphanage
la couche: social class (several other meanings)
Tout commence par la traditionnelle parade. Des centaines de personnes suivent échassiers et marionnettes géantes au son de la fanfare. Pendant quatre jours, les artistes investissent les quartiers, les orphelinats, les villages alentours.
Everything starts with the traditional parade. Hundreds of people follow stilt-walkers and giant puppets to the sound of the brass band. For four days, artists flood the neighborhoods, the orphanages, the surrounding villages.
On permet aux couches défavorisées, à toute personne sans distinction, de pouvoir vivre la culture…
This lets the disadvantaged classes, every person without distinction, to be able to live the culture…
Trigger warning: this post contains an obscenity related to a bodily function.
Picture source: screenshot of ABC News story on my cellphone. “GOP” is a nickname for the Republican Party.
I was surprised to see a very colloquial American English expression in an ABC News story today. Sentator Lindsey Graham, referring to support for Donald Trump (reality TV star and candidate for the Republican Party presidential candidate nomination) by the Republican Party was quoted as saying that the party was “batshit crazy.”
Batshit is a modifier that can be attached only to the adjective crazy, as far as I know. Batshit crazy means something like “very crazy.” You can also use it by itself to mean “crazy.” For example, if I said The dog went batshit when I took the chicken out of the oven, it means The dog went crazy when I took the chicken out of the oven.
Be aware that although the expressions batshit crazy or batshit are very colorful and fun to use, they are not polite, and you must not use them in a formal situation. I would not say either one of them around my grandmother, or while teaching. However, in the right situation, this is a great expression with which to add a true American flavor to your English.
Does someone know a good French equivalent to batshit crazy? I’d love to hear about it in the comments section.
Regarding dates: the definite article le always has to be there, as my interlocutor said. Be careful: you say a date with the masculine definite article le, e.g. le 8 mars, “March 8th”–but, the word “date” itself is feminine–quelle est la date? “What’s the date?” For more on how to talk about dates in French, see this page on the Lawless French web sit.
Regarding negating infinitives: the first thing to note is that ne pas goes in front of the infinitive, so you would say ne pas manger “not to eat,” NOT ne manger pas. Throw in a direct object pronoun and it goes in front of the infinitive, too: ne pas le dire, “not to say it.”
What happens if you have an indirect object pronoun? A direct pronoun and an indirect object pronoun? A direct object pronoun, an indirect object pronoun, and a reflexive verb? Here are some examples of those, from blogger and native speaker Bea dM:
Direct and indirect object pronouns: ne pas le lui donner, “not to give it to him.” Moral of the story: ne pas precedes all of the object pronouns.
Reflexive pronoun and direct object pronoun: ne pas se le répéter, “not to repeat it to himself.” Moral of the story: ne pas precedes the reflexive pronoun, as well.
As we saw in a recent post, beauty is not a linguistic concept. Linguistics is about the scientific study of language, and science doesn’t have a concept of beauty, at least not for its objects of study (as opposed to, say, a really nice proof). So, if I say that Brazilian Portuguese has the most beautiful consonnes fricatives (fricative consonants), I’m speaking as a civilian (or “normal person,” as we linguists call the rest of you), not in my official capacity.
Having gotten that disclaimer out of the way, you’ll find below a list of people’s thoughts about the most beautiful French verbs. There aren’t a lot of repeats on this list (unlike a similar list of nouns that I saw the other day), so I’ll just pass it on without much comment, and add some of my favorite French verbs or verbal expressions to use:
rester cloîtré dans mon appartement: to stay shut up in my apartment–literally, to stay cloistered.
podcaster: to download a podcast, to listen to by podcast. (In other words: the opposite of the English meaning, although if you look it up on Linguee.fr,you’ll see some translations with the English meaning, too. I’ve only heard it with the opposite of the English meaning, though.)
retweeter: to retweet.
chunker: to break down into analyzable units. This is a technical term in language processing, where the usual English verb is “to chunk.”
I knew that I was meant to be a linguist the day that I was listening to a Brazilian guy being tortured on the radio. As the Portuguese-speaking police officer questioned him and the guy screamed in the background, I thought: what beautiful fricatives. I think that this is also strong evidence that I am a terrible person, but that’s a conversation for another time.
There’s something that you need to keep in mind about this story: my judgement about the relative beauty or lack thereof of a language isn’t a professional judgement at all. Rather, it is an entirely personal one. Linguists think of themselves as people who study language from a scientific perspective, and from a scientific perspective, beauty is not a relevant characteristic for describing a language. Are there people who study language from a non-scientific perspective? Sure–poets. Poets typically have a very deep awareness of language, and fantastic insights into it. However, a poet’s understanding of what language is and how language works is very different from a linguist’s understanding of what language is and how language works. I can’t imagine protesting against a poet’s description of something linguistic as beautiful. But, that’s not a word that you would hear coming out of my mouth as a linguist. As a civilian? Sure–for example, Brazilian Portuguese is beautiful. But, as we’ve seen, I’m a terrible person–so, take my aesthetic judgements with a grain of salt.
Is there a reason that so many rock stars have been dying lately? Here’s how to talk about it in French.
The Poisson distribution describes the probability of a given number of events occurring in a fixed interval of time and/or space if these events occur with a known average rate and independently of the time since the last event (definition from Wikipedia.com). Who cares? As Wikipedia puts it, with some highlighting by me: The Poisson distribution can be applied to systems with a large number of possible events, each of which is rare. How many such events will occur during a fixed time interval? Under the right circumstances, this is a random number with a Poisson distribution. If you’ve been reading this blog for a while, you know that (a) a language has a lot of words, and b) most of the words in a language are rare–that’s why we can use Zipf’s Law to describe the distribution of words in a language, and that’s why I write this blog, which keeps track of the obscure words that I learn in the course of my day. (Just some of them–there are far too many in any given day for me to track them all.) So, you could imagine using the Poisson distribution to predict things like how many new words I will run into today.
There are many practical applications of the Poisson distribution. For example, most of my colleagues work with genomic data of one sort or another. Say you’re looking at the number of mutations in a particular stretch of DNA. Mutations are rare. You have a stretch of DNA that you think has a lot of mutations, and you think that you know what caused them. Before you draw conclusions about whether or not the mutations were, in fact, caused by that, you need to be sure that the stretch of DNA couldn’t have acquired that large (you think) number of mutations by chance. The Poisson distribution lets you assign a probability of that number of mutations occurring by chance in that one stretch of DNA. If the Poisson distribution suggests that the probability of that number of mutations occurring by chance is greater than, say, 5%, then you probably shouldn’t draw the conclusion that you were considering concerning what caused it. On the other hand, if the Poisson distribution suggests that the probability of that number of mutations occurring by chance is, say, 0.00001%, then you may be onto something. Poisson distributions have been used in many fields; the most famous application was a study of the number of Prussian soldiers killed by horse-kicks. Suppose that you suddenly have a large number of soldiers being killed by getting kicked by horses. Do you need to be training your soldiers differently? Has someone been selling you lousy horses? If the incidence of deaths by horse-kicks follows a Poisson distribution (and deaths by horse-kick are rare events that are presumably independent of each other, so they do follow a Poisson distribution), then you can calculate the probability of the aforementioned large number of horse-kick deaths having occurred by chance. If the probability of them having occurred by chance is large, then you probably don’t need to retrain your soldiers or start looking for a lousy horse-dealer. If the probability of them having occurred by chance is low, then you might want to look into retraining your soldiers, or reconsidering your horse-buying practices, or whatever. (I don’t know how the study turned out–see this Wikipedia page for a reference to the book.)
One of the practical consequences of the Poisson distribution is that even rare events will occasionally occur together. The classic example: three rock stars die in the same month. Here are some of the rock stars who died last month (January 2016):
…and there’s your classic three-rock-stars-in-one-month phenomenon. Actually, it’s even weirder—three rock stars actually died on one day that month. January 17th, 2016 saw the loss of Blowfly, Mic Gillette, and Dale Griffin.
What’s going on? Is someone killing off the rock stars of the Anglophone world? Probably not–the Poisson distribution tells us that such events, which are both rare and independent, will sometimes occur in bursts, despite their rarity and independence.
Some implications for the world of Zipf’s Law:
I have to admit that I’ve been mischaracterizing the Poisson distribution somwhat in previous posts. Briefly: I’ve been ignoring the independence assumption. More on that later, because it’s a really big deal in language in general.
When you’re learning a second language, you’re going to have some good days and some bad days. On the bad days, you’re going to run across a lot of words that you don’t know. The Poisson distribution tells you to not get down on yourself about this fact: it’s just the nature of rare events (including words) to show up in clusters sometimes.
All of these dead rock stars have brought a new word into my life: la disparition. As you probably know, this can mean “disappearance.” What you might not be aware of is that it can also mean “death, passing,” or “demise.” So, on the radio this morning, the host of Les Matins de France Culture was talking about ladisparition of Umberto Eco.
Reviewing some relevant vocabulary (definitions from WordReference.com):
In general, there is not nearly as much dialectal diversity in the United States as there is in most of the rest of the world. There are a couple of reasons for this, the biggest one being that English speakers haven’t been here long enough to develop very many of them. English has been spoken in England for maybe 1600 years, and there is an enormous amount of dialect diversity there. (I’m a native speaker, and I frequently can’t understand people in the north of England, although they’re definitely native speakers, too. Actually, I have trouble with some of the south of England, too.) In contrast, we’ve been here for maybe 400 years–there just hasn’t been time for the language to diverge as much as it has on the other side of the pond. You can see a strong correspondence between dialect diversity and how long a region of the United States has been settled by English speakers–the population history is oldest on the East Coast, and that’s where the bulk of the dialect diversity is. Travel west, where English speakers settled much more recently, and there’s much less regional difference in the language. (In contrast: Spanish has been spoken in the western US considerably longer, and there are fascinating regional dialects of Spanish in the western US.)
The weird rhythms of the ongoing American presidential election season are taking us to South Carolina at the moment, and that has had the effect of bringing South Carolina dialects to someplace where you don’t normally hear them much: the national media. In case you’re not American, here’s a little something to help you acclimate yourself to the way the English language is spoken in the south of the country. The first video is short, but has a lot of data. The second one is long, but funny. Some things to watch for:
The l after vowels. Across the Anglophone world, l after vowels (i.e., at the end of the syllable) is a common locus for dialectal variation. For the southerners, there really isn’t one–it’s more like a w or a u. In English dialects worldwide, this is a pretty common variant. Listen to the words oil and y’all.
The second person plural y’all.
Lexical items. In the longer video, any American native speaker will fall on the floor laughing when the southerner first says that she calls any carbonated beverage coke, and then claims that she doesn’t. Basically, carbonated beverages are soda in some parts of the country, pop in others, soda pop in a few, and–this is highly stigmatized–coke in others, stereotypically in southern parts of the country.
The pronunciation of the vowel spelt a at the end of words like grandma, and in the middle of water,caught, and lawyer.
Here’s the short video:
Here’s the long video. The Northerner is from Pennsylvania, and the Southerner is from North Carolina. (Yes, North Carolina is in the south.) I get the impression that they both went to college in Pennsylvania, and the Southerner talks a lot about how she has tried to speak differently since leaving the South.
A couple of notes:
As a native of the Pacific Northwest, I must insist on this. They’re not rolly-pollies–they’re potato bugs!
I can’t even imagine what word or expression the survey is trying to get at when it asks what you call it when rain falls while the sun is shining: in the Pacific Northwest, the sun does not shine.
If you’re wondering about the expression for when you throw toilet paper at a house: yes, in the United States that is “a thing.” Teenagers do it to hassle people they don’t like. Typically it includes TP’ing a tree in the front yard in addition to the house; it’s difficult to impossible to get the TP out of a tree, and it stays there, a mark of shame, for weeks. See below.
For some years, the US National Institute of Standards and Technology (NIST) has run a “shared task” in which groups can try out and compare the pluses and minuses of various approaches to information retrieval. Information retrievalis the process of using a computer to find sources of information–that might be web pages if you’re Google, or books if you’re a library–and in a shared task, multiple groups agree on (a) a definition of the task, (b) a data set to use for the task, and (c) a scoring metric. The shared task model helps to make research by different groups more comparable. Otherwise, you often have different groups defining the “same” task somewhat differently, and/or evaluating their performance on different data sets, and/or reporting different metrics in their publications. We deliberately don’t call shared tasks “competitions”–the hope is that the meetings where people discuss the results are occasions for sharing and learning (although, of course, the people with the highest scores brag like hell about it). The National Institute of Standards and Technology’s shared task on information retrieval, known as TREC (Text REtrieval Conference), was one of the earliest shared tasks in language processing, and it’s probably the most famous of the ones that are still taking place today.
When you participate in TREC, there’s a computer program that is used to calculate scores for your performance on the various tasks. It’s called trec_eval. The documentation is sketchy, and bazillions of graduate students around the world have individually figured out how to use it. In this post, I’m going to pull together some of the details about how to format your data correctly for the trec_eval program, and then how to run it. I won’t go into all of the options, which I don’t claim to understand–my goal here is just to give you the information that you need in order to get up and running with it.
I’ve pulled this information together from a number of sources, and supplemented it with a bit of experimentation and some very patient emails from Ellen Voorhees, the TREC project manager. If you find a particularly good web page on trec_eval, please tell us about it in the comments.
In what follows, I’ll discuss data format issues for the gold standard and for the system output. (One of the dirty little secrets of the otherwise-glamorous world of natural language processing and computational linguistics is that we spend an inordinate amount of time getting data into the proper formats for doing the stuff that’s actually interesting to us.) Then I’ll show you how to run the trec_eval program. You’re on your own for interpreting the output, for the moment–there are just way too many metrics to fit into this blog post.
One global point about the qrels file and the system output file: as Ellen Voorhees points out, For both qrels and results files, fields can be separated by either tabs or spaces. But all fields must be present in the correct order and all on the same line.
Formatting the gold-standard answers
You will typically be provided with the gold-standard answers for trec_eval, assuming that you’re participating in a shared task. However, you may occasionally want to make your own. For example, I sometimes use trec_eval to evaluate bioinformatics applications that return ranked lists of things other than documents. In that case, I model the other things as documents–that is, I replace the document identifier that I describe below with, say, a pathway identifier, or a Gene Ontology concept identifier, or whatever. In TREC parlance, the gold standard answers are called the qrels. You only need to remember this if you want to be able to read the original documentation (or know what people are talking about when they talk about evaluating information retrieval with trec_eval).
There are four things that go into the gold standard. One of them is a constant–the number 0 in the second column, which is there for reasons that are now opaque. They get separated by tabs. Here are the four things:
query number: there are typically 50 or so queries in a good gold standard. Each one is identified by a number.
0: this is a constant. It’s the number zero. Historically, it’s the iteration number. More specifically, this page at NIST says that it is “the feedback iteration (almost always zero and not used)“. Ellen Voorhees says that the ‘iteration number’ was intended to record what iteration within a feedback loop the results were retrieved in so that a feedback-aware evaluation methodology (such as frozen ranks) could be implemented. But it soon became clear that trying to compare feedback algorithms across teams within TREC was a far thornier problem than simply recording an iteration number and the idea was abandoned. But by that time there were all sorts of scripts that were expecting four-column qrels files, so the four columns remain. Some of the later tracks have started to use this field. For example, web track diversity task qrels use this field to record the aspect number. But those tasks are not evaluated using trec-eval, and trec_eval does not use the field.
document ID: in the prototypical case, this will be the identification number of an actual document. If you’re using trec_eval for something other than document retrieval per se, it can be any individual item that can be right or wrong–a sentence identifier, a gene identifier, whatever.
relevance: this is either a 1 (for a document that is relevant, i.e. a right answer) or 0 (for a document that is not irrelevant, i.e. a wrong answer).
There are six things that go into the file with your system’s output. Two of them are constants, although I think that in theory it’s possible to put something else in these columns in order to support some kind of (possibly now defunct) analysis. They get separated by tabs. Here are the six things:
query number: the query numbers should match query numbers in the gold standard. Wondering what happens if you have a query number in your output file that’s not in the gold standard? Ellen Voorhees says that Query ids that are in the results file but not in the qrels are ignored. Query ids that are not in the results file but are in the qrels are also ignored by default. However, that is not how we evaluate in TREC itself because systems are supposed to process the entire test set. (You can game your scores by only responding to topics that you know you will do well on.) To force trec_eval to compute averages over all topics included in the qrels, use the -c option—this uses ‘0’ as the score for topics missing in the results file for all measures.
Q0: this is a constant. It’s the letter Q followed by the number zero.
document ID: see above–prototypically, this would be a document ID, but you could have IDs for other kinds of things here, too. Due to the way that TREC gold standards are built, I would be surprised if it’s a problem to have a document ID show up in here that’s not in the gold standard. On this subject, Ellen Voorhees says that Document ids that are in the results file but not in the qrels file are assumed to be not relevant for most measures. There are some measures such as bpref that ignore unjudged (i.e., missing in qrels) documents. You can force trec_eval to ignore all unjudged documents using the -J
option, but people using this option should have a clear idea of why they are doing so…and you probably shouldn’t. I certainly don’t.
rank: This is a row number, and within a topic, it needs to be unique. trec_eval actually ignores this number. How does it break ties in the score, then? Ellen Voorhees explains: …trec_eval does its own sort of the results by decreasing score (which can have ties). trec_eval does not break ties using the rank field, either: whatever order its internal sort puts those tied scores is the order used to evaluate the results. This is done on purpose, with the idea being that if the system really can’t distinguish among a set of documents, then it is fair to evaluate any ordering of those documents. A user who wants trec_eval to evaluate a specific ordering of the documents must ensure that the *SCORES*
reflect the desired ordering.
score: there needs to be some number in this spot.
Exp: on various and sundry web pages, you will see this described as the constant “Exp”. Ellen Voorhees again: The final field is the run tag (name). I don’t think trec_eval uses it at all (although it might pass it through to label the results), but TREC uses it heavily. The final field is not used by trec_eval other than it expects some string to be there. The reason the format contains a field trec_eval does not use is because TREC itself uses the field in lots of places. The final field is the “run tag” or name of the run. TREC uses the value of that field to name the files it keeps about a run, to identify the run in the appendix to the proceedings where the evaluation results are posted, to label graphs when run results are plotted, etc. The run submission system enforces that the run tag is unique across runs (over all tracks and all participants) for that TREC.
Here’s an example of a snippet from a system output file:
An extract from an example of a system output file. Picture source: me.
Running trec_eval
There are a number of options that you can pass to trec_eval, but the basics of the usage are like this:
trec_eval gold_standard system_output
The official score reports that you get from TREC are produced like this:
trec_eval -q -c gold_standard system_output
That the usage should be like this is obvious from the documentation only if you know that qrels refers to the gold standard, and now you do! So, if I have a file named pilot.qrels that contains my gold standard and a file named pilot.system.baseline that contains my system outputs, then I would type this:
On to the options. This from Ellen Voorhees: By default, trec_eval reports only averages over the set of topics. With the -q option, it prints scores for each topic (the -q is short for ‘query’), and then prints the averages. The score reports TREC participants receive from NIST are produced using the -q (and -c) option.
As I said above, I won’t attempt to explain the scores that you will get in this one little blog post. See a good reference on information retrieval evaluation for that. You can find an explanation of the scores, and the motivation for each of them, in the appendix of every issue of the TREC proceedings, which you can find on line for free.
Is an event a thing? In traditional grammar, they are, at least on the level at which we’re taught traditional grammar in the Anglophone education system. Events are nouns, and specifically common nouns, as far as I know. So, we see a similarity between many dogs and many breakdowns, and a difference between many storms and a lot of juice. Dogs and breakdowns are easily pluralizable and take many, while juice is not pluralizable (it certainly is, but with different meanings) and takes a lot of.
So: in English, events are things. However, today I ran across some evidence that in French, they are not. Here’s how it went, and how I sounded stupid.
I’d been trying to work out the details of some flights for the past couple days. My host in France was the go-between between me and the person booking the travel. Eventually the person booking the travel sent me some flights, and I wanted to write back to say that they were fine–“that works,” as you might say in English:
My email.
One of the things that I really, really appreciate about France is that many French people (as you will have read in innumerable books about France) are willing to point out your errors in French. This is how we improve, and I love it! Here’s what I got back:
(Part of) the response.
What’s going on here? It’s as my interlocutor described it: marcher is something that can refer to a thing, but not to an event. From a linguist’s perspective, this is fascinating, because it sheds some light on the status of a basic, very fundamental question in the semantics of a language: what are the kinds of distinctions that the language makes? Or, from a more poetic standpoint: from the point of this language, how is the world constructed? This is a question of ontology, the subject of this post from a couple days ago. Questions about language can be framed as very concrete questions about statistics, and they can be framed as very abstract questions about philosophy, and both approaches have their uses. Either way, the answer to the question should come from actual data.
Anyways: that’s how I sounded stupid today. Or, at least, that’s one way that I sounded stupid! Oh, and one more thing: the French word for “event” is one of the words affected by the big spelling reform coming up this fall. It’s going from événement to évènement. You know what this means: one more word that I’ve been pronouncing incorrectly for the past two years!
Update, March 26th, 2016
I showed this post to my interlocutor. Here’s his response–an alternative analysis.
Ta-Nehisi Coates. Picture source: By David Shankbone (Shankbone) [CC BY 3.0 (http://creativecommons.org/licenses/by/3.0)%5D, via Wikimedia Commons.Ta-Nehisi Coates is this super-cogent writer whose essays I love to read. His second book, Between the world and me, won the 2015 National Book Award for Nonfiction, and he was recently awarded a MacArthur Genius Grant. He took the MacArthur money and moved to Paris, as any reasonable person would. Here is a wonderful video of him in the midst of trying to learn French. I can completely relate to his pain. As he puts it: he sounds like an intelligent guy in English, but in French…different story. That’s totally the story of my life these days–I think I’m fairly articulate in English, but when I try to explain the simplest things in French, I sound like a bumbling idiot. Oh, well–practice makes perfect. I hope.




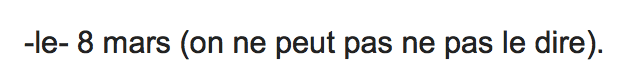




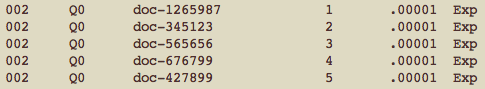

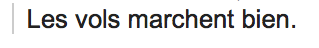




{kind=link}