

For some years, the US National Institute of Standards and Technology (NIST) has run a “shared task” in which groups can try out and compare the pluses and minuses of various approaches to information retrieval. Information retrieval is the process of using a computer to find sources of information–that might be web pages if you’re Google, or books if you’re a library–and in a shared task, multiple groups agree on (a) a definition of the task, (b) a data set to use for the task, and (c) a scoring metric. The shared task model helps to make research by different groups more comparable. Otherwise, you often have different groups defining the “same” task somewhat differently, and/or evaluating their performance on different data sets, and/or reporting different metrics in their publications. We deliberately don’t call shared tasks “competitions”–the hope is that the meetings where people discuss the results are occasions for sharing and learning (although, of course, the people with the highest scores brag like hell about it). The National Institute of Standards and Technology’s shared task on information retrieval, known as TREC (Text REtrieval Conference), was one of the earliest shared tasks in language processing, and it’s probably the most famous of the ones that are still taking place today.
When you participate in TREC, there’s a computer program that is used to calculate scores for your performance on the various tasks. It’s called trec_eval. The documentation is sketchy, and bazillions of graduate students around the world have individually figured out how to use it. In this post, I’m going to pull together some of the details about how to format your data correctly for the trec_eval program, and then how to run it. I won’t go into all of the options, which I don’t claim to understand–my goal here is just to give you the information that you need in order to get up and running with it.
I’ve pulled this information together from a number of sources, and supplemented it with a bit of experimentation and some very patient emails from Ellen Voorhees, the TREC project manager. If you find a particularly good web page on trec_eval, please tell us about it in the comments.
In what follows, I’ll discuss data format issues for the gold standard and for the system output. (One of the dirty little secrets of the otherwise-glamorous world of natural language processing and computational linguistics is that we spend an inordinate amount of time getting data into the proper formats for doing the stuff that’s actually interesting to us.) Then I’ll show you how to run the trec_eval program. You’re on your own for interpreting the output, for the moment–there are just way too many metrics to fit into this blog post.
One global point about the qrels file and the system output file: as Ellen Voorhees points out, For both qrels and results files, fields can be separated by either tabs or spaces. But all fields must be present in the correct order and all on the same line.
Formatting the gold-standard answers
You will typically be provided with the gold-standard answers for trec_eval, assuming that you’re participating in a shared task. However, you may occasionally want to make your own. For example, I sometimes use trec_eval to evaluate bioinformatics applications that return ranked lists of things other than documents. In that case, I model the other things as documents–that is, I replace the document identifier that I describe below with, say, a pathway identifier, or a Gene Ontology concept identifier, or whatever. In TREC parlance, the gold standard answers are called the qrels. You only need to remember this if you want to be able to read the original documentation (or know what people are talking about when they talk about evaluating information retrieval with trec_eval).
There are four things that go into the gold standard. One of them is a constant–the number 0 in the second column, which is there for reasons that are now opaque. They get separated by tabs. Here are the four things:
- query number: there are typically 50 or so queries in a good gold standard. Each one is identified by a number.
- 0: this is a constant. It’s the number zero. Historically, it’s the iteration number. More specifically, this page at NIST says that it is “the feedback iteration (almost always zero and not used)“. Ellen Voorhees says that the ‘iteration number’ was intended to record what iteration within a feedback loop the results were retrieved in so that a feedback-aware evaluation methodology (such as frozen ranks) could be implemented. But it soon became clear that trying to compare feedback algorithms across teams within TREC was a far thornier problem than simply recording an iteration number and the idea was abandoned. But by that time there were all sorts of scripts that were expecting four-column qrels files, so the four columns remain. Some of the later tracks have started to use this field. For example, web track diversity task qrels use this field to record the aspect number. But those tasks are not evaluated using trec-eval, and trec_eval does not use the field.
- document ID: in the prototypical case, this will be the identification number of an actual document. If you’re using trec_eval for something other than document retrieval per se, it can be any individual item that can be right or wrong–a sentence identifier, a gene identifier, whatever.
- relevance: this is either a 1 (for a document that is relevant, i.e. a right answer) or 0 (for a document that is not irrelevant, i.e. a wrong answer).
Here’s a screen shot of the qrels (gold standard) document http://trec.nist.gov/data/robust/qrels.robust2004.txt:

Formatting your system’s output
There are six things that go into the file with your system’s output. Two of them are constants, although I think that in theory it’s possible to put something else in these columns in order to support some kind of (possibly now defunct) analysis. They get separated by tabs. Here are the six things:
- query number: the query numbers should match query numbers in the gold standard. Wondering what happens if you have a query number in your output file that’s not in the gold standard? Ellen Voorhees says that Query ids that are in the results file but not in the qrels are ignored. Query ids that are not in the results file but are in the qrels are also ignored by default. However, that is not how we evaluate in TREC itself because systems are supposed to process the entire test set. (You can game your scores by only responding to topics that you know you will do well on.) To force trec_eval to compute averages over all topics included in the qrels, use the -c option—this uses ‘0’ as the score for topics missing in the results file for all measures.
- Q0: this is a constant. It’s the letter Q followed by the number zero.
- document ID: see above–prototypically, this would be a document ID, but you could have IDs for other kinds of things here, too. Due to the way that TREC gold standards are built, I would be surprised if it’s a problem to have a document ID show up in here that’s not in the gold standard. On this subject, Ellen Voorhees says that Document ids that are in the results file but not in the qrels file are assumed to be not relevant for most measures. There are some measures such as bpref that ignore unjudged (i.e., missing in qrels) documents. You can force trec_eval to ignore all unjudged documents using the -J
option, but people using this option should have a clear idea of why they are doing so…and you probably shouldn’t. I certainly don’t. - rank: This is a row number, and within a topic, it needs to be unique. trec_eval actually ignores this number. How does it break ties in the score, then? Ellen Voorhees explains: …trec_eval does its own sort of the results by decreasing score (which can have ties). trec_eval does not break ties using the rank field, either: whatever order its internal sort puts those tied scores is the order used to evaluate the results. This is done on purpose, with the idea being that if the system really can’t distinguish among a set of documents, then it is fair to evaluate any ordering of those documents. A user who wants trec_eval to evaluate a specific ordering of the documents must ensure that the *SCORES*
reflect the desired ordering.
- score: there needs to be some number in this spot.
- Exp: on various and sundry web pages, you will see this described as the constant “Exp”. Ellen Voorhees again: The final field is the run tag (name). I don’t think trec_eval uses it at all (although it might pass it through to label the results), but TREC uses it heavily. The final field is not used by trec_eval other than it expects some string to be there. The reason the format contains a field trec_eval does not use is because TREC itself uses the field in lots of places. The final field is the “run tag” or name of the run. TREC uses the value of that field to name the files it keeps about a run, to identify the run in the appendix to the proceedings where the evaluation results are posted, to label graphs when run results are plotted, etc. The run submission system enforces that the run tag is unique across runs (over all tracks and all participants) for that TREC.
Here’s an example of a snippet from a system output file:
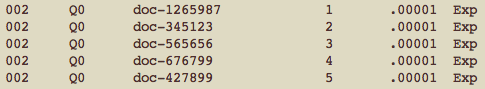
Running trec_eval
There are a number of options that you can pass to trec_eval, but the basics of the usage are like this:
trec_eval gold_standard system_output
The official score reports that you get from TREC are produced like this:
trec_eval -q -c gold_standard system_output
That the usage should be like this is obvious from the documentation only if you know that qrels refers to the gold standard, and now you do! So, if I have a file named pilot.qrels that contains my gold standard and a file named pilot.system.baseline that contains my system outputs, then I would type this:
./directory_containing_treceval_executable/trec_eval pilot.qrels pilot.system.baseline
On to the options. This from Ellen Voorhees: By default, trec_eval reports only averages over the set of topics. With the -q option, it prints scores for each topic (the -q is short for ‘query’), and then prints the averages. The score reports TREC participants receive from NIST are produced using the -q (and -c) option.
As I said above, I won’t attempt to explain the scores that you will get in this one little blog post. See a good reference on information retrieval evaluation for that. You can find an explanation of the scores, and the motivation for each of them, in the appendix of every issue of the TREC proceedings, which you can find on line for free.
