This post is a draft of part of a piece that I’m writing at the moment, and on which I would like your feedback. The topic is variability in language. I pay the rent by researching the issues involved in getting computers to understand biomedical language–for example, the language of scientific journal articles, or the language of health records. I’m in the midst of writing a chapter about this topic for a handbook of computational linguistics. The audience is people who are interested in computational linguistics, but don’t have any experience with the biomedical domain. If you’re a reader of this blog, that’s probably not a bad description of you. So, it would be super-helpful to me to have your critique of this material. I’m looking for anything that isn’t clear, anything that makes it difficult to understand my prose–anything that you think could be improved. My grandmother will tell me how wonderful it is, so just feel free to plow into me with both fists–seriously, you’d be surprised at how much pain you can take in your old age, and I’m getting pretty old.
Variability is the property of being able to express the same proposition in multiple ways. If ambiguity is the major problem of natural language processing, variability is the second. From a theoretical perspective, the field of sociolinguistics sees the study of variation in language as the central problem of linguistics, and it makes a strong case for that claim (e.g. Labov 2004)[1]. From a practical perspective in natural language processing, the high degree of variability in natural language prevents us from ever being able to use a dictionary-like data structure (such as hash tables, B-trees, or tries) to accomplish our tasks: we will never have a “dictionary” of all possible sentences (Chomsky 1959)[2]. This kind of approach would be fast and efficient—if only it were possible (Gusfield 1997)[3].
Sources of variability
Some of the sources of variability in language are well-known even to the casual reader—for example, synonymy, or the availability of multiple words that have the same dictionary meaning. A kind of synonymy that is especially relevant in biomedical languages occurs when there is both a technical and a lay or common term for something, such as the lay term heart attack and the technical term myocardial infarction. Using technical terminology is important for the precision of scientific writing and of medical records (Rey 1979)[4]. However, the use of technical terminology also can make it difficult for patients and their families to learn about their illness or to understand their own health records (Kandula et al. 2010)[5]. One way to deal with this problem is to use natural language processing techniques to replace technical terms with their lay synonyms (Elhadad 2006[6], Elhadad and Sutaria 2007,[7] Deléger and Zweigenbaum 2009[8], Leroy et al. 2013a[9], Leroy et al. 2013b[10]) or their definitions (Elhadad 2006)[11] in order to make clinical documents or scientific journal articles accessible to non-professionals. Doing this computationally, rather than manually, allows it to be done at enormous scales, or on demand. This is a good example of why to do natural language processing in the biomedical domain: the possibility of doing real good in the world.
 Paraphrase is the phenomenon of different (and typically syntactically different) expressions in language of the same meaning (Ganitkevitch et al. 2013)[12]. Where synonymy operates of the level of words, paraphrase operates at the level of the phrase, or group of words. Paraphrasing is a source of variability that is especially interesting in the biomedical domain because of how it interacts with the technical vocabulary of the field (Deléger and Zweigenbaum 2008, Deléger 2009, Deléger and Zweigenbaum 2010, Grabar and Hamon 2014)[13],[14],[15],[16]. Funk et al. looked for possibilities to paraphrase or replace synonyms in 41,853 terms from the Gene Ontology, and found that 27,610 out of 41,852 were paraphrasable, or had synonyms, or both[17]. This indicates that the possibilities for variant forms of the same thing occurring in the biomedical literature are tremendous.
Paraphrase is the phenomenon of different (and typically syntactically different) expressions in language of the same meaning (Ganitkevitch et al. 2013)[12]. Where synonymy operates of the level of words, paraphrase operates at the level of the phrase, or group of words. Paraphrasing is a source of variability that is especially interesting in the biomedical domain because of how it interacts with the technical vocabulary of the field (Deléger and Zweigenbaum 2008, Deléger 2009, Deléger and Zweigenbaum 2010, Grabar and Hamon 2014)[13],[14],[15],[16]. Funk et al. looked for possibilities to paraphrase or replace synonyms in 41,853 terms from the Gene Ontology, and found that 27,610 out of 41,852 were paraphrasable, or had synonyms, or both[17]. This indicates that the possibilities for variant forms of the same thing occurring in the biomedical literature are tremendous.
 But, do those tremendous numbers of variants really occur? It appears that they do. Cohen et al. (2008) looked at the incidence of alternative syntactic constructions involving common nominalizations (nouns derived from verbs, such as treatment from to treat) in scientific journal articles—for example, drug treatment of cancer and cancer treatment with drugs. Figure 1 shows a typical finding: for some nominalizations, as many as 15 out of 16 possible variants could be found even in a relatively small corpus[18].
But, do those tremendous numbers of variants really occur? It appears that they do. Cohen et al. (2008) looked at the incidence of alternative syntactic constructions involving common nominalizations (nouns derived from verbs, such as treatment from to treat) in scientific journal articles—for example, drug treatment of cancer and cancer treatment with drugs. Figure 1 shows a typical finding: for some nominalizations, as many as 15 out of 16 possible variants could be found even in a relatively small corpus[18].
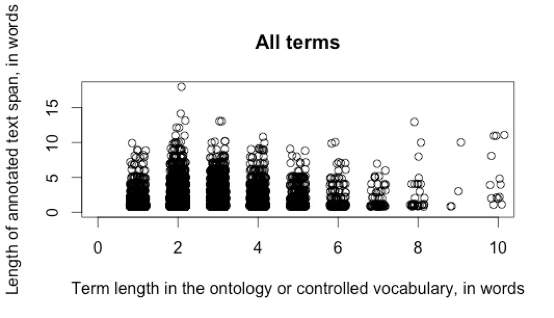
 How different can these paraphrases be from each other? Technical terms in biomedical research can be quite long, which means that there can be multiple candidates for paraphrasing and for replacement of synonyms (see above). This means that the number of possible paraphrases of a long term can be explosive. Those paraphrases, even for a short term, can be quite different—for example, Cohen et al. (2017) examined the relationship between the length of terms in the Gene Ontology and the length of appearances of those terms in the CRAFT corpus of biomedical journal articles, and found that 2-word terms could show up with paraphrases as long as 15 words[19]. The high incidence of just these two forms of variability in language—synonymy and paraphrasing—as well as the large differences that can be seen in forms with the same meanings illustrate just how much of an issue variability is for natural language processing in general, and in biomedical texts in particular.
How different can these paraphrases be from each other? Technical terms in biomedical research can be quite long, which means that there can be multiple candidates for paraphrasing and for replacement of synonyms (see above). This means that the number of possible paraphrases of a long term can be explosive. Those paraphrases, even for a short term, can be quite different—for example, Cohen et al. (2017) examined the relationship between the length of terms in the Gene Ontology and the length of appearances of those terms in the CRAFT corpus of biomedical journal articles, and found that 2-word terms could show up with paraphrases as long as 15 words[19]. The high incidence of just these two forms of variability in language—synonymy and paraphrasing—as well as the large differences that can be seen in forms with the same meanings illustrate just how much of an issue variability is for natural language processing in general, and in biomedical texts in particular.
Harsh critiques in the Comments section below, please!
[1] Labov, William. “Quantitative reasoning in linguistics.” Sociolinguistics/Soziolinguistik: An international handbook of the science of language and society 1 (2004): 6-22.
[2] Chomsky, Noam. “A review of BF Skinner’s Verbal Behavior.” Language 35, no. 1 (1959): 26-58.
[3] Gusfield, Dan. Algorithms on strings, trees and sequences: computer science and computational biology. Cambridge university press, 1997.
[4] Rey, Alain. La terminologie: noms et notions. No. 1780. Presses Univ. de France, 1979, p. 56.
[5] Kandula, Sasikiran, Dorothy Curtis, and Qing Zeng-Treitler. “A semantic and syntactic text simplification tool for health content.” In AMIA annual symposium proceedings, vol. 2010, p. 366. American Medical Informatics Association, 2010.
[6] Elhadad, Noemie. “Comprehending technical texts: Predicting and defining unfamiliar terms.” In AMIA annual symposium proceedings, vol. 2006, p. 239. American Medical Informatics Association, 2006.
[7] Elhadad, Noemie, and Komal Sutaria. “Mining a lexicon of technical terms and lay equivalents.” In Proceedings of the Workshop on BioNLP 2007: Biological, Translational, and Clinical Language Processing, pp. 49-56. Association for Computational Linguistics, 2007.
[8] Deléger, Louise, and Pierre Zweigenbaum. “Extracting lay paraphrases of specialized expressions from monolingual comparable medical corpora.” In Proceedings of the 2nd Workshop on Building and Using Comparable Corpora: from Parallel to Non-parallel Corpora, pp. 2-10. Association for Computational Linguistics, 2009.
[9] Leroy, Gondy, David Kauchak, and Obay Mouradi. “A user-study measuring the effects of lexical simplification and coherence enhancement on perceived and actual text difficulty.” International journal of medical informatics 82, no. 8 (2013): 717-730.
[10] Leroy, Gondy, James E. Endicott, David Kauchak, Obay Mouradi, and Melissa Just. “User evaluation of the effects of a text simplification algorithm using term familiarity on perception, understanding, learning, and information retention.” Journal of medical Internet research 15, no. 7 (2013).
[11] Elhadad, Noemie. “Comprehending technical texts: Predicting and defining unfamiliar terms.” In AMIA annual symposium proceedings, vol. 2006, p. 239. American Medical Informatics Association, 2006.
[12] Ganitkevitch, Juri, Benjamin Van Durme, and Chris Callison-Burch. “PPDB: The paraphrase database.” Proceedings of the 2013 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2013.
[13] Deléger, Louise, and Pierre Zweigenbaum. “Paraphrase acquisition from comparable medical corpora of specialized and lay texts.” AMIA Annual Symposium Proceedings. Vol. 2008. American Medical Informatics Association, 2008.
[14] Deléger, Louise. Exploitation de corpus parallèles et comparables pour la détection de correspondances lexicales: application au domaine médical. Diss. Paris 6, 2009.
[15] Deléger, Louise, and Pierre Zweigenbaum. “Identifying Paraphrases between Technical and Lay Corpora.” LREC. 2010.
[16] Grabar, Natalia, and Thierry Hamon. “Unsupervised method for the acquisition of general language paraphrases for medical compounds.” Proceedings of the 4th International Workshop on Computational Terminology (Computerm). 2014.
[17] Funk, Christopher S., K. Bretonnel Cohen, Lawrence E. Hunter, and Karin M. Verspoor. “Gene Ontology synonym generation rules lead to increased performance in biomedical concept recognition.” Journal of biomedical semantics 7, no. 1 (2016): 52.
[18] Cohen, K. Bretonnel, Martha Palmer, and Lawrence Hunter. “Nominalization and alternations in biomedical language.” PloS one 3.9 (2008): e3158.
[19] Cohen, K. B., Verspoor, K., Fort, K., Funk, C., Bada, M., Palmer, M., & Hunter, L. E. (2017). The colorado richly annotated full text (craft) corpus: Multi-model annotation in the biomedical domain. In Handbook of Linguistic Annotation (pp. 1379-1394). Springer, Dordrecht.
Harsh critiques in the Comments section below, please!












 You know how the matching game works: we have words in English, words in French, and we match them. Today’s words (and a tiny bit of grammar) are taken from the discussion of Zipf’s Law in the book
You know how the matching game works: we have words in English, words in French, and we match them. Today’s words (and a tiny bit of grammar) are taken from the discussion of Zipf’s Law in the book 









