The most common questions that people ask me about life in Paris:
How come nobody in Paris speaks English? (How come explained in the English notes below.)
How come whenever I try to speak to people in Paris in French, they always answer me in English?
Aren’t you afraid of terrorist attacks?
Where can I buy non-touristy souvenirs?
(1) and (2) are, of course, contradictory, and I’ve written about them before (and will again, ’cause it’s super-complicated). I’ve written about (3), too, and no, I’m not–every 3 days in the US, we have more gunfire deaths than Paris had in its worst terrorist attack in history. I literally have a greater chance of being shot to death in a road rage incident on my way to work in the US than I do of dying in a terrorist attack in Paris. Seriously.
(4): a question that I love to answer. Today I’ll tell you where to buy non-touristy souvenirs in Montmartre.
Before there were museums, there was the cabinet of curiosities–le cabinet de curiosités. If you were powerful, or maybe just really rich, your cabinet of curiosities was where you showed off your collection of … interesting stuff. Mostly stuff from the natural world. A narwhal’s tusk, say; rare stones; perhaps some fossils. Showing it off was the point. As Wikipedia puts it:
The Kunstkammer (cabinet of curiosities) of Rudolf II, Holy Roman Emperor (ruled 1576–1612), housed in the Hradschin at Prague, was unrivalled north of the Alps; it provided a solace and retreat for contemplation[3] that also served to demonstrate his imperial magnificence and power in symbolic arrangement of their display, ceremoniously presented to visiting diplomats and magnates.[4]
Montmartre is a neighborhood in the northern part of Paris. As you might expect from the name Montmartre, it has an elevation, and at the peak of that elevation is one of Paris’s most popular tourist attractions: Sacré Coeur, “Sacred Heart,” France’s way of saying it’s sorry that Paris seceded from it in 1871.
I jest–bitterly: Sacré Coeur expresses France’s wish that Paris would say that it’s sorry that it seceded in 1871. Sacré Coeur is reactionary France’s way of putting words in Paris’s mouth–specifically, an apology for having seceded from France in 1871. As if it weren’t enough that the Versaillais (the soldiers of the national government) killed 20,000-ish Parisians when they retook the city. La semaine sanglante, it’s called–The Bloody Week.
Descending from the aforementioned elevation on a Sunday-afternoon walk the other day, I came across Grégory Jacob and a truly delightful place to buy non-touristy stuff in Montmartre. Curiositas is a charming little store in the style of a 19th-century cabinet of curiosities, complete with a nice selection of marlin snouts–far more practical in a little Parisian apartment than a narwhal tusk, and just as pointed.
Grégory spent 20 years as an optician before the insurance companies sucked the joy out of the profession, at which point he decided to become a boutiquier (see the French notes below for some subtleties of the terminology of shop-owners) and opened Curiositas. His new profession lets him pursue his passions–la chine, la brocante, les curiosités, l’ostéologie, l’entomologie–in the very neighborhood where Gabriel loses his glasses and delivers his monologue in Zazie dans le métro.
And all of those passions are represented–the wares on offer include skulls, bugs, and the super-cool apparatus for drinking absinthe. (Who knew that there are nifty devices for holding the sugar cube over which you pour la fée verte, “the green fairy”–absinthe itself. Hell, I didn’t even know that you pour it over a sugar cube. Hell, again: I didn’t even know that they still make the stuff.) You need coasters with anatomical organs on them? Grégory’s got them. An emu egg? No problem. Skulls? Curiositas has both carnivores and herbivores. You’re tired of the Montmartre crêpe shops, wannabe artists, and fabric stores? Step into Curiositas. Tell Grégory the weird American guy says hi. Scroll down past the pictures for the English and French notes.
You don’t expect the zombie apocalypse to be relevant to research in computational linguistics–and yet it is; it so, so is.
Spoiler alert: this post about the TV show The Walking Dead–which, I will note, is as popular in France as it is in the US–will tell you what happens to Carol around Season 3 or 4.
In general, it’s the stuff that surprises you that’s interesting, right? No one ever expects the arctic ground squirrel to have anything to do with computational linguistics–and yet it does: it so, so does. No one ever expects to be confronted with problems with the relationship between compositionality and the mapping problem over breakfast in a low-rent pancake house–and yet it happens; it so, so happens. (Low-rent as an adjective explained in the English notes below.) You don’t expect the zombie apocalypse to be relevant to research in computational linguistics–and yet it is; it so, so is.
You’ve probably heard of machine learning. It’s the science/art/tomfoolery of creating computer programs to learn things. We’re not talking about The Terminator just yet–some of the things that are being done with machine learning, particularly developing self-driving cars, are pretty amazing, but mostly it’s about teaching computers to make choices. You have a photograph, and you want to know whether or not it’s a picture of a cat–a simple yes/no choice. You have a prepositional phrase, and you want to know whether it modifies a verb (I saw the man with a telescope–you have a telescope, and using it, you saw some guy) or a noun (I saw the man with a telescope–there is a guy who has a telescope, and you saw him). Again, the computer program is making a simple two-way choice–the prepositional phrase is either modifying the verb (to see), or it’s modifying the noun (the man). (The technical term for a two-way choice is a binary decision.) Conceptually, it’s pretty straightforward.
Cats keep showing up in these illustrations because the latest-and-greatest thing in machine learning is alleged to have solved all extant problems and made the rest of computer science irrelevant, but the major reported accomplishment so far has been classifying pictures as to whether or not they are pictures of cats. The “It uses a few CPUSs!” part is a reference to the fact that in order to do this, it requires outlandish amounts of computing resources (a CPU is a “central processing unit”). Picture source: https://doubleclix.wordpress.com/2013/06/01/deep-learning-next-frontier-01/
When you are trying to create a computer program to do something like this, you need to be able to understand how it goes wrong. (Generally, seeing how something goes right isn’t that interesting, and not necessarily that useful, either. It’s the fuck-ups that you need to understand.) There are two concepts that are useful in thinking your way through this kind of thing, neither of which I’ve really understood–until now.
I recently spent a week in Constanta, Romania, teaching at–and attending–the EUROLAN summer school on biomedical natural language processing. “Natural” language means human language, as opposed to computer languages. Language processing is getting computer programs to do things with language. Biomedical language is a somewhat broad term that includes the language that appears in health records, the language of scientific journal articles, and more distant things like social media posts about health. My colleagues Pierre Zweigenbaum and Eric Gaussier taught a great course on machine learning, and one of the best things that I got out of it was these two concepts: bias and variance.
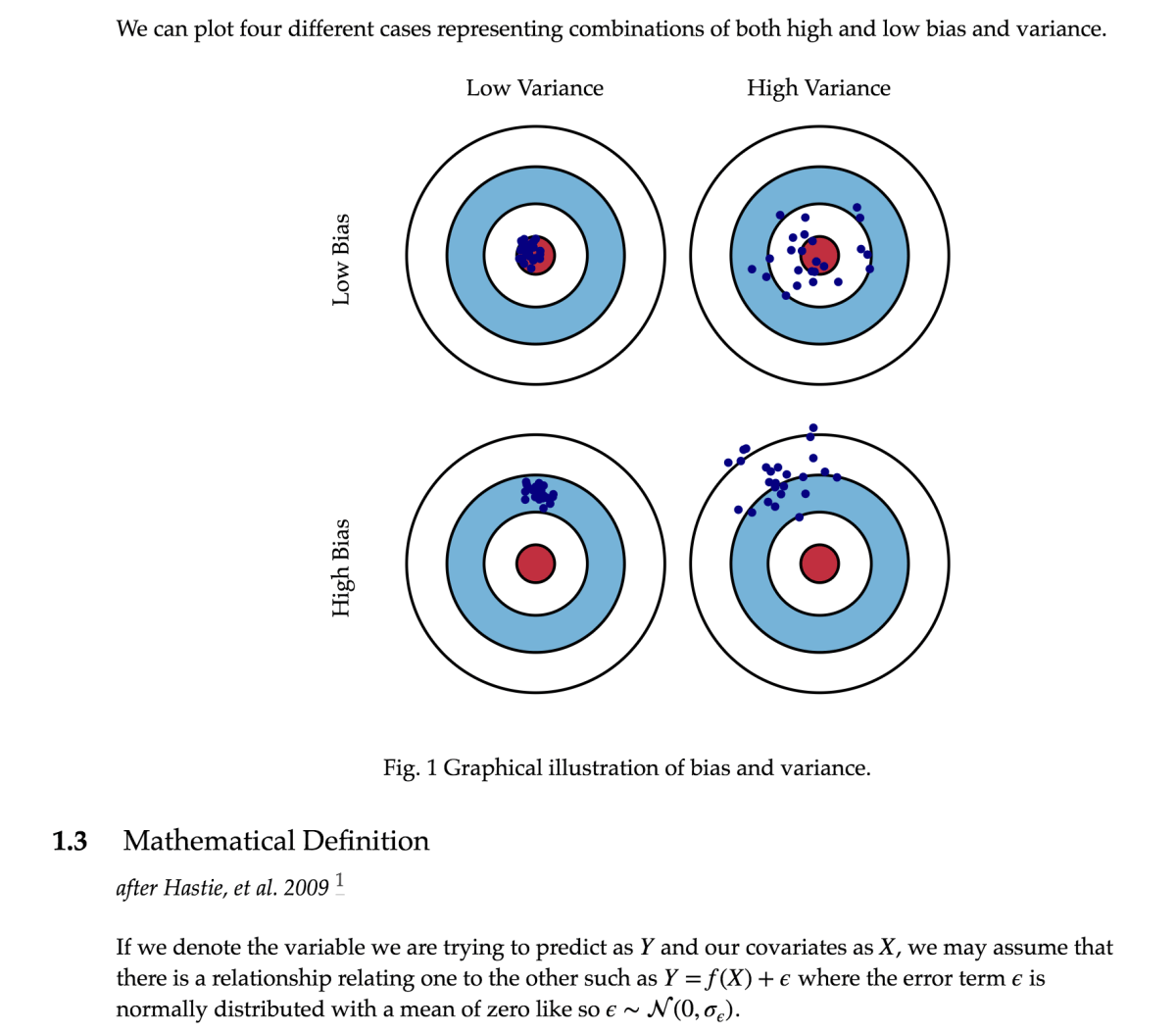
Bias means how far, on average, you are from being correct. If you think about shooting at a target, low bias means that on average, you’re not very far from the center. Think about these two shooters. Their patterns are quite different, but in one way, they’re the same: on average, they’re not very far from the center of the target. How can that be the case for the guy on the right?
Picture source: XX
Think about it this way: sometimes he’s a few inches off to the left of the center of the target, and sometimes he’s a few inches off to the right. Those average out to being in the center. Sometimes he’s a few inches above the target, and sometimes he’s a few inches below it: those average out to being in the center. (This is how the Republicans can give exceptionally wealthy households a huge tax cut, and give middle-class households a tiny tax cut, and then claim that the average household gets a nice tax cut. Cut one guy’s taxes by 1,000,000 dollars and nine guys’ taxes by zero (each), and the average guy gets a tax cut of 100,000 dollars. One little problem: nobody’s “average.”) So, he’s a shitty shooter, but on average, he looks good on paper. These differences in where your shots land are are called variance. Variance means how much your results differ from each other, on average. The guy on the right is on average close to the target, but his high variance means that his “average” closeness to the target doesn’t tell you much about where any particular bullet will land.
Thinking about this from the perspective of the zombie apocalypse: variancemeans how much your results differ from each other, on average, right? Low variance means that if you fire multiple times, on average there isn’t that much difference in where you hit. High variance means that if you fire multiple times, there is, on average, a lot of difference between where you hit with those multiple shots. The guy on the left below (scroll down a bit) has low bias and low variance–he tends to hit in roughly the same area of the target every time that he shoots (low variance), and that area is not very far from the center of the target (low bias). The guy on the right has low bias, just like the guy on the left–on average, he’s not far off from the center of the target. But, he has high variance–you never really know where that guy is going to hit. Sometimes he gets lucky and hits right in the center, but equally often, he’s way the hell off–you just don’t know what to expect from that guy.
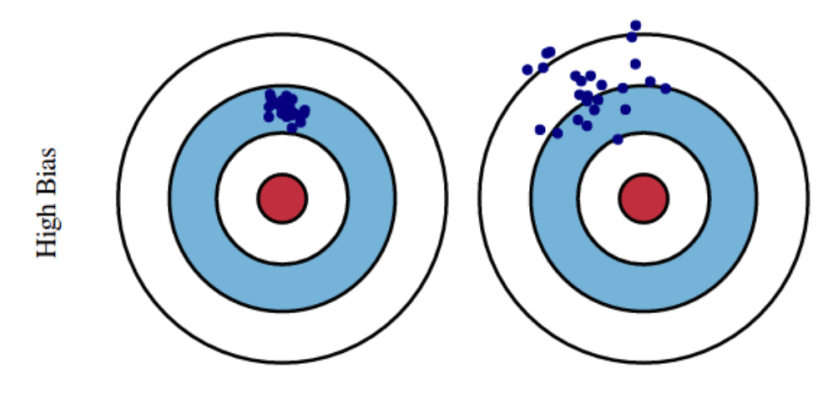
We’ve been talking about variance in the context of two shooters with low bias–two shooters who, on average, are not far off from the center of the target. Let’s look at the situations of high and low variance in the context of high bias. See the picture below: on average, both of these guys are relatively far from the center of the target, so we would describe them as having high bias. But, their patterns are very different: the guy on the left tends to hit somewhere in a small area–he has low variance. The guy on the right, on the other hand, tends to have quite a bit of variability between shots: he has high variance. Neither of these guys is exactly “on target,” but there’s a big difference: if you can get the guy on the left to reduce his bias (i.e. get that small area of his close to the center of the target), you’ve got a guy who you would want to have in your post-zombie-apocalypse little band of survivors. The guy on the right–well, he’s going to get eaten.
High bias: both of the shooters tend to hit fairly far from the center of the target. The guy on the left has low variance, while the guy on the right has high variance.
A quick detour back to machine learning: suppose that you test your classifier (the computer program that’s making binary choices) with 100 test cases. You do that ten times. If it’s got an average accuracy of 90, and its accuracy is always in the range of 88 to 92, you’re going to be very happy–you’ve got low bias (on average, you’re pretty close to 100), and you’ve got low variance–you’re pretty sure what your output is going to be like if you do the test an 11th time.
Abstract things like machine learning are all very well and good for cocktail-party chat (well, if the cocktail party is the reception for the annual meeting of the Association for Computational Linguistics–otherwise, if you start talking about machine learning at a cocktail party, you should not be surprised if that pretty girl/handsome guy that you’re talking to suddenly discovers that they need to freshen their drink/go to the bathroom/leave with somebody other than you. Learn some social skills, bordel de merde !) So, let’s refocus this conversation on something that’s actually important: when the zombie apocalypse comes, who will you want to have in your little band of survivors? And: why? “Who” is easy–you want Rick, Carol, Darryl. (Some other folks, too, of course–but, these are the obvious choices.) Why them, though? Think back to those targets.
Low bias, low variance: this is the guy who is always going to hit that zombie right in the center of the forehead. This is Rick Grimes. Right in the center of the forehead: that’s low bias. Always: that’s low variance.
Low bias, high variance: this is the guy who on average will not be far from the target, but any individual shot may hit quite far from the target. This guy “looks good on paper” (explained in the English notes below) because the average of all shots is nicely on target, but in practice, he doesn’t do you much good. This guy survives because of everyone else, but doesn’t necessarily contribute very much. In machine learning research, this is the worst, as far as I’m concerned–people don’t usually report measures of dispersion (numbers that tell you how much their performance varies over the course of multiple attempts to do whatever they’re trying to do), so you can have a system that looks good because the average is on target, even though the actual attempts rarely are. On The Walking Dead, this is Eugene–typically, he fucks up, but every once in a rare while, he does something brilliantly wonderful.
High bias: both of the shooters tend to hit fairly far from the center of the target. Picture source: XXSPOILER AERT! The Walking Dead’s Carol. She starts out as a meek, mild, battered housewife who can barely summon up the courage to keep her daughter from being sexually abused. Later… Yes, she’s my favorite TWD character. Picture source: https://goo.gl/8D6323
High bias, low variance: this guy doesn’t do exactly what one might hope, but he’s reliable, consistent–although he might not do what you want him to do, you have a pretty good idea of what he’s going to do. You can make plans that include this guy. He’s fixable–since he’s already got low variance, if you can get him to shift the center of his pattern to the center of the target, he’s going to become a low bias, low variance guy–another Rick Grimes. This is Daryl, or maybe Carol.
High bias, high variance: this guy is all over the place–except where you want him. He could get lucky once in a while, but you have no fucking idea when that will happen, if ever. This is the preacher.
Which Walking Dead character am I? Test results show that I am, in fact, Maggie. I can live with that.
Here are some exercises on applying the ideas of bias and variance to parts of your life that don’t have anything to do (as far as I know) with machine learning. Scroll down past each question for its answer, and if you think that I got wrong, please straighten me out in the Comments section. Or, just skip straight to the French and English notes at the end of the post–your zombie apocalypse, your choice.
Your train is supposed to show up at 6 AM. It is always exactly 30 minutes late. If we assume that 30 minutes is a lot of time, then the bias is high/low. Since the train is always late by the same amount of time, the variance is high/low.
The bias is high. Bias is how far off you are, on average, from the target. We decided that 30 minutes is a lot of time, so the train is always off by a lot, so the bias is high. On the other hand, the variance is low. Variance is how consistent the train is, and it is absolutely consistent, since it is always 30 minutes. Thus: the variance is low.
Your train is supposed to show up at 6 AM. It is always either exactly 30 minutes early, or 30 minutes late. More specifically: half of the time it is 30 minutes early, and half of the time it is 30 minutes late. Assume that 30 minutes is a lot of time: is the bias high or low? Is the variance high or low?
Since on average, the train is on time–being early half the time and late half the time averages out to always being on time–the bias is low. Zero, in fact. This gives you some insight into why averages are not that useful if you’re trying to figure out whether or not something operates well. The give-away is the variance—even when something looks fine on average, high variance gives away how shitty it is.
Want to know which Walking Dead character you are? You have two options:
Take one of the many on-line quizzes available.
Analyze yourself in terms of bias and variance.
English notes
low-rent: “having little prestige; inferior or shoddy” (Google) “low in character, cost, or prestige” (Merriam-Webster)
I’m getting the feeling that The Penguin is a real low-rent villain to a lot of people. Like, you want him there, but not as THE boss. Not good enough to fight Batman on his own, but good enough for Batgirl and the Birds of Prey. Intriguing. 🤔
How is she still on TV? Why isn’t her career ruined? We run Franken out on a rail for some ancient bs but she gets to keep running her disgusting low-rent mouth?
to look good on paper: “to seem fine in theory, but not perhaps in practice; to appear to be a good plan.” (McGraw-Hill Dictionary of American Idioms and Phrasal Verbs) Often followed by “but…”
Argentina looks good on paper but when the games start, you’ll be seeing only Messi.
Some of it is systemic. Ending earmarks seemed like a good idea until it removed the catalyst for compromise. And Newt’s dictum to live in one’s district looks good on paper but a lot of negative consequences.
From the French-language Wikipedia article on what’s called in English the bias-variance tradeoff:
En statistique et en apprentissage automatique, le dilemme (ou compromis) biais–variance est le problème de minimiser simultanément deux sources d’erreurs qui empêchent les algorithmes d’apprentissage supervisé de généraliser au-delà de leur échantillon d’apprentissage :
Le biais est l’erreur provenant d’hypothèses erronées dans l’algorithme d’apprentissage. Un biais élevé peut être lié à un algorithme qui manque de relations pertinentes entre les données en entrée et les sorties prévues (sous-apprentissage).
La variance est l’erreur due à la sensibilité aux petites fluctuations de l’échantillon d’apprentissage. Une variance élevée peut entraîner un surapprentissage, c’est-à-dire modéliser le bruit aléatoire des données d’apprentissage plutôt que les sorties prévues.
Waiting in line at the San Jose children’s museum just now, I overheard this conversation:
Customer: Do you have pizza?
Clerk: We stopped serving hot food at 2:30.
Clear enough to a human: the clerk’s answer was no. In fact, when the customer stared at him blankly in response, the clerk said this: We do not have pizza.
What did I have to do in order to understand that we stopped serving hot food at 2:30 meant “no”? Think about this: if you walked up to me in the street and asked Do you know where Notre Dame is? …and I responded We stopped serving hot food at 2:30, would you take that to mean “no” ? I think not. So, let’s think about what had to happen at that cash register:
The listener had to make an assumption that we call relevance: that the clerk’s response was, in fact, relevant to his question. (For those of you who are into pragmatics and discourse: this is one of the Gricean maxims.)
The listener had to know that pizza is a “hot food”.
The listener had to know or consider that the current time was past 2:30.
The listener had to make a number of inferences: I got a response about hot foods, pizza is a kind of hot food, so what is true of hot foods will be true of pizza.
The semantics of to stop are such that when the guy says that they did it at 2:30, I should understand that they are still doing it now. (Contrast to stop with the verb to pause, which doesn’t require the same inferences as to stop.)
…and of course it’s the fact that I get excited about the guy in line behind me at the museum snack bar not being able to get his fucking pizza that keeps me from ever getting a second date, and so I’m just gonna go talk about the mammoth skeleton with my niece and nephew. What will we say about it, exactly? See below.
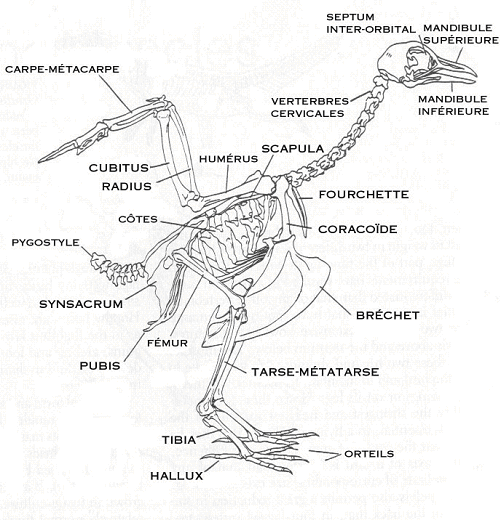
The mammoth has two clavicle bones. They articulate with the sternum, but aren’t attached to it. Why do we care? Because that’s pretty characteristic of mammals. In contrast, in birds the clavicles have fused to form what’s called the furcula or fourchette in French, or the wishbone in English. Check it out next time you’re stripping the post-Thanksgiving turkey carcass, and see below for the French-language terminology.
The mammoth’s shoulder blade (omoplate in French–it’s the thing that looks triangular) is on the great beast’s side. Why do you care? Because that’s characteristic of quadrupeds. Humans, apes, and birds all have their scapula on their backs, not their sides.
…and lacking a good ending for this post, I finish my coffee and head back to the mammoth room.
Oh: the guy got a bag of potato chips. Junk food is junk food, I guess.
When I was in graduate school–in the US–I had a colleague whose child was allegedly growing up francophone. I think the father was an American professor in the French department, or something. We were all very impressed.
One semester we had a visiting academic from France in our lab. He had super-hip glasses. Over lunch one day, the kid asked him: “why do your glasses have such tiny lenses? His response: c’est à la mode.
The kid thought for a minute. Then, another question: “why do you have ice cream on your glasses?” I try not to be mean, but I thought to myself: this kid speaks French even worse than I do, and that’s an accomplishment…
In the French notes today (scroll down past the picture): my attempts to understand various words that could be used to translate the English word fashion.
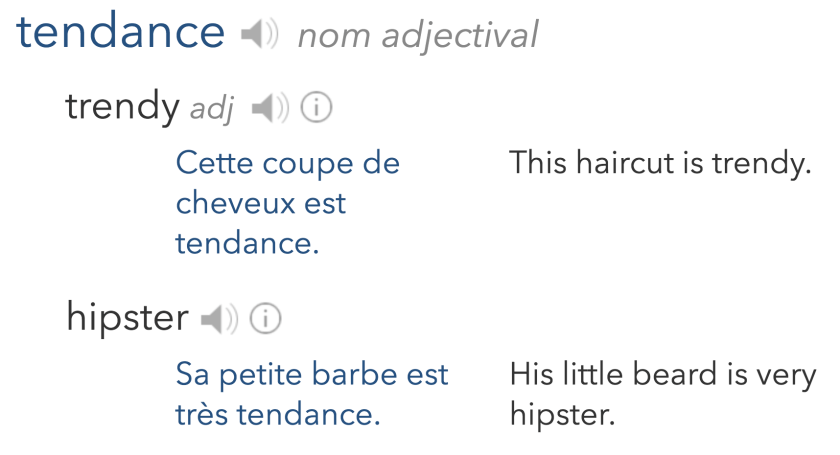
In trying to figure out the differences between la mode and la tendance via looking at examples on Linguee.fr, the trend (ha) seems to be that la tendance is not used to talk about things that are “in fashion” so much as tendencies/trends more generally. The closest uses to “in fashion” are their adjectival examples:
Source: screen shot from Linguee.fr.
Compare some nominal (noun) examples–their translations are more about trends in general, versus trends in the sense of things being fashionable:
Source: screen shot from Linguee.fr.
Linguee.fr gives a number of examples of avoir tendance à, translated as “to tend to:”
From Linguee.fr.
For fashion in the sense of haute couture and the like (yes, that’s the English term, too), la mode seems to be more common:
From Linguee.fr.
Change the gender to masculine — le mode — and you have senses along the lines of “mode” in English:
From Linguee.fr.
…and some fixed expressions (all examples from Linguee.fr):
le mode d’emploi : operating instructions, instruction manual, user guide
J’ai lu le mode d’emploi avant d’utiliser l’appareil. I read the instruction manual before using the device.
Le mode d’emploi est fourni en cinq langues. The operating instructions are provided in five languages.
Avant de nous contacter, veuillez vous assurer d’avoir respecte le dosage des produits et suivile mode d’emploi. Before contacting us, please, make sure that
you take the right dosage of the products and follow the instructions for use.
le mode de vie : lifestyle
le mode aperçu : preview mode
It seems so simple that it makes one wonder: why was I ever confused about this? As it happens, I have a pretty good memory for the contexts in which I run into words, so I can tell you that the source of my confusion is an advertising poster that I saw in the metro one day. I interpreted it (possibly incorrectly) as meaning something like “so you think you know what’s cool?”, and my recollection is that it said something like tu penses que tu connais la tendance? Maybe it’s just that the aforementioned kid (ledit marmot) spoke French better than I thought, and I speak French even worse than I thought…
We already knew that the patient had the primary, secondary, and tertiary stages of syphilis.
Tell someone you’re a computational linguist, and the next question is almost always this: so, how many languages do you speak? This annoys the shit out of us, in the same way that it might annoy a public health worker if you asked them how many stages of syphilis they have. (There are four. When I was a squid (military slang for “sailor”), one of our cardiologists lost her cool and threw a scalpel. It stuck in one of my mates’ hands. We already knew that the patient had the primary, secondary, and tertiary stages of syphilis, so my buddy was one unhappy boy…)
Being asked “how many languages do you speak?” annoys us because it reflects a total absence of knowledge about what we devote our professional lives to. (This is obviously a little arrogant–why should anyone else bother to find out about what we devote our professional lives to? That’s our problem, right? Nonetheless: the millionth time that you get asked, it’s annoying.) It’s actually easier to explain what linguistics is in French than it is in English, because French has two separate words for things that are both covered by the word language in English:
une langueis a particular language, such as French, or English, or Low Dutch.
le langageis language as a system, as a concept.
No, I did not just make up “tone-bearing unit.”
Linguists study the second, not the first. People who call themselves linguists might specialize in vowels, or in words like “the,” or in how people use language both to segregate themselves and to segregate others. Whatever it is that you do, you’re basing it on data, and the data comes from actual languages, so you might work with any number of them–personally, I wrote a book on a language spoken by about 30,000 people in what is now South Sudan. The point of that work, though, is to investigate broader questions about langage, more so than to speak another language–that’s a very different thing. I can tell you a hell of a lot about the finite state automata that describe tone/tone-bearing-unit mappings in that language, but can’t do anything in it beyond exchange polite greetings (and one very impolite leave-taking used only amongst males of the same age group).
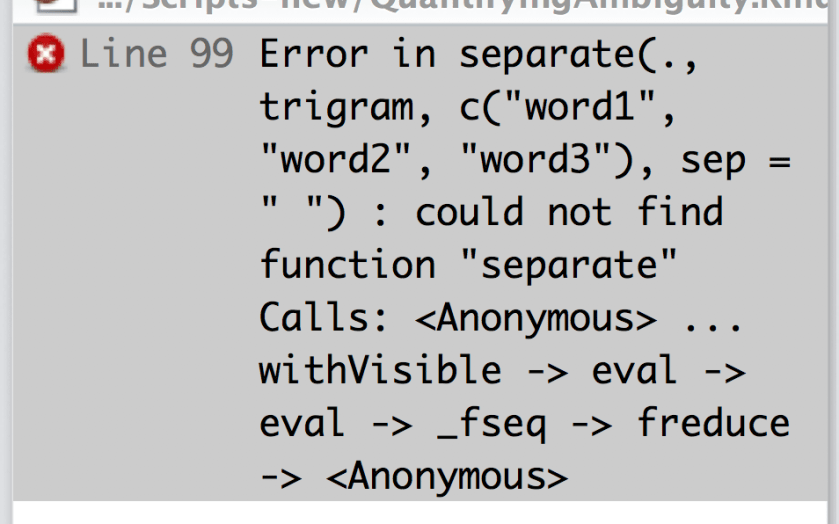
So, if you’re not spending your days sitting around memorizing vocabulary items in three different regional variants of Upper Sorbian, what does a linguist actually do all day? Here’s a typical morning. I was trying to do something with trigrams (3-word sequences–approximately the longest sequence of words that you can include in a statistical model of language before it stops doing what you want it to do), when I ran into this:
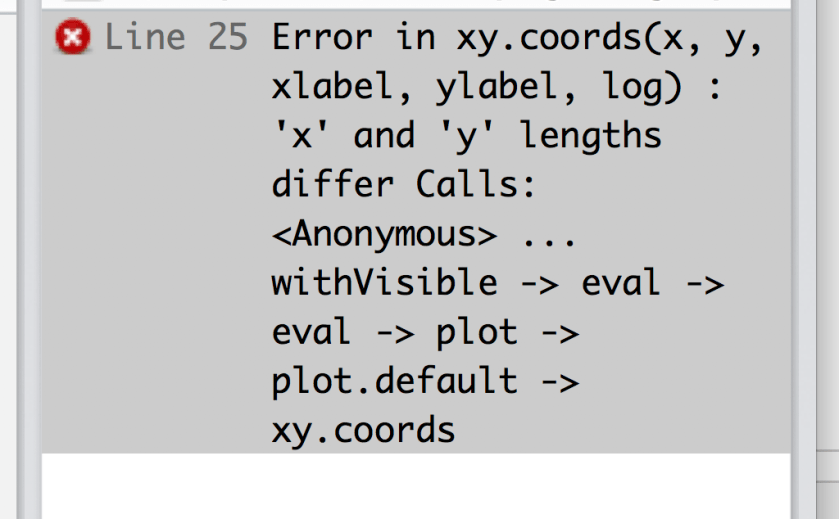
Fixed that one, and then there was a problem with my x-ray reports (my speciality is biomedical languages)…
Fixed that one, and then…
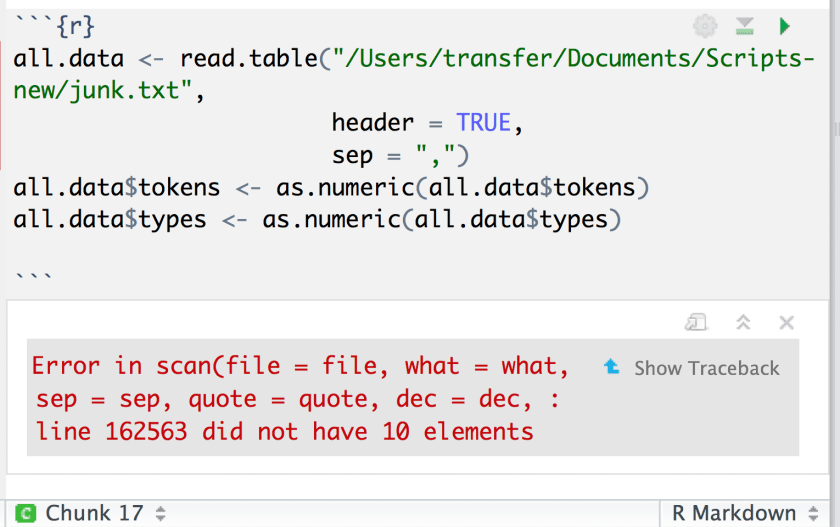
…and your guess may well be better than mine on that one. God help you if you run into this kind of thing, though…
Source: me.
…because that message about not having some number of elements (a) usually takes forever to figure out, and then (b) once you do figure it out, reflects some kind of problem with your data that is going to give you a lot of headaches before you get it fixed.
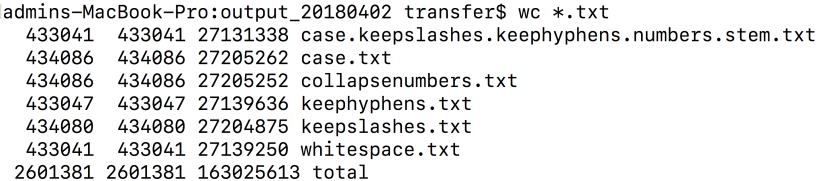
I spend a lot of my day looking at things like this:
Source: me.
.,..which is a bunch of 0s and 1s describing the relationship between word frequency and word rank, plus what goes wrong when your data gets created on an MS-DOS machine, which I will have to fix before I can actually do anything with said data (see the English notes below for what said data means); or this…
Source: me.
…which tells me some things about the effects of “minor” preprocessing differences on type/token ratios–they’re not actually so minor; or this…
Source: Cohen, K. B., Verspoor, K., Fort, K., Funk, C., Bada, M., Palmer, M., & Hunter, L. E. (2017). The Colorado Richly Annotated Full Text (CRAFT) corpus: Multi-model annotation in the biomedical domain. In Handbook of Linguistic Annotation (pp. 1379-1394). Springer, Dordrecht.
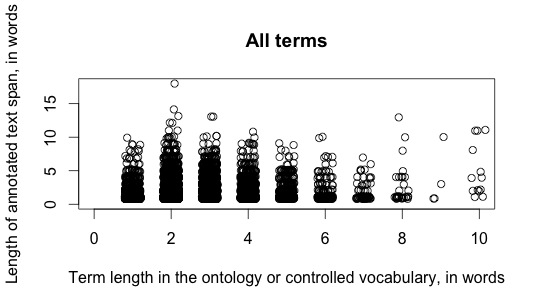
…which tells me that either there are some errors in that data, or there is an enormous amount of variability between the official terminology of the field and the way that said terminology actually shows up in the scientific literature. (See the leftmost blob–it indicates that there are plenty of cases of one-word terms that show up as more than 5 words in actual articles. That is certainly possible–disease in which abnormal cells divide without control and can invade nearby tissues is 13 words that together correspond to the single-word term cancer—but, I was surprised to see just how frequent those large discrepancies in lengths were. In my professional life, I love surprises, but they also suggest that you’d better consider the possibility that there are problems with the data.)
So, yeah: it’s not like I can’t get my hair cut in Japanese, or explain how to do post-surgical hand therapy in Spanish, or piss off a con artist in Turkish (a story for another time)–but, none of those have anything to do with my professional life as a computational linguist. That’s all about computing, which means computers, and I hate computers. Ironic, hein? Life is fucking weird, and I like it that way.
English notes
I think this is Queneau, but couldn’t swear to it. Source: it’s all over the place.
said: a shorter way of saying “the aforementioned.” Both of these are characteristic of written language, more so than of spoken language. Even in writing, though, it’s pretty bizarre if you’re not a native speaker, which is why I picked it to talk about today. A French equivalent would be ledit/ladite/lesdites (not sure about that last one–Phil dAnge?), which I have a soft spot for ’cause I learned it in Queneau’s Exercices de style.
Trying to think of helpful ways to recognize this bizarre usage of said, I went looking for examples of said whose part of speech is adjectival. Here are some of the things that I found:
As such, any dispute that you may have on goods purchased or services availed of should be raised directly withsaid merchant/s.
A seemingly endless shopping list to conquer, a shrinking budget with which to dosaidshopping ~ and let’s face it: our businesses don’t run themselves while we’re visiting relatives.
This is a monumental pain in the ass — you don’t exactly trip over Notary Publics in today’s day and age — and I can only assume came fromsaidcompany having a problem with identity once sometime in the last twelve years, and the president saying “fuck it.”
How it appears in the post:
…what goes wrong when your data gets created on an MS-DOS machine, which I will have to fix before I can actually do anything with said data;…
Either there are some errors in that data, or there is an enormous amount of variability between the official terminology of the field and the way that said terminology actually shows up in the scientific literature.
debugging: A technical term in software programming that refers to finding problems in your program. I used it in the title of today’s post because most of the illustrations that I gave of what I do all day are of irritating problems of one sort or another that I (really did) have to track down in the course of my day. They don’t tell you in school that tracking down such things are literally about 80% of what any programmer spends their time doing. Of course, any problem in a computer program is a problem that you created, so you can get irritated about them, but you most certainly cannot take your irritation out on anyone else…
A recording with a transcript is a great way to develop your oral comprehension skills. Here’s a link to a story on National Public Radio. It analyzes the recently released questions that the Justice Department wants to ask Donald Trump, the draft-dodging, give-secrets-to-the-Russians asshole who is the president of the United States–for the moment.


 Descending from the aforementioned elevation on a Sunday-afternoon walk the other day, I came across Grégory Jacob and a truly delightful place to buy non-touristy stuff in Montmartre. Curiositas is a charming little store in the style of a 19th-century cabinet of curiosities, complete with a nice selection of marlin snouts–far more practical in a little Parisian apartment than a narwhal tusk, and just as pointed.
Descending from the aforementioned elevation on a Sunday-afternoon walk the other day, I came across Grégory Jacob and a truly delightful place to buy non-touristy stuff in Montmartre. Curiositas is a charming little store in the style of a 19th-century cabinet of curiosities, complete with a nice selection of marlin snouts–far more practical in a little Parisian apartment than a narwhal tusk, and just as pointed.























 Camus’s L’Étranger, end of the first chapter of Part II: “that’s all for today, Mr. Antichrist.” Note that the final T is pronounced.
Camus’s L’Étranger, end of the first chapter of Part II: “that’s all for today, Mr. Antichrist.” Note that the final T is pronounced.