

Like loving a woman with a broken nose, you may well find lovelier lovelies. But never a lovely so real. — Nelson Algren, Chicago: City on the Make (1951)
I have never managed to translate these lines from Nelson Algren’s (book-length) prose poem Chicago: City on the Make to French to my satisfaction. The problem comes from the fact that lovely can (and usually is) an adjective, but can also be — super-rarely, I suspect — a noun. Hmmm–not unlike belle in French, maybe? Native speaker Phil d’Ange came up with this classical couplet:
To keep the rhyme but also to have the same number of syllables, a must in French classical poetry, I made two 12-foot verses (the top of classicism, what we call “des alexandrins”, 12 foot verses with “la césure à l’hémistiche” i.e. a natural pause right in the middle, after 6 feet) that keep the meaning and the rhyme.
“Peut-être verras-tu un jour belles plus belles
Mais jamais ne verras de belle plus réelle” .
Nelson was talking here about Chicago, but Chicago was not his only love: Simone de Beauvoir was another. The end of their relationship is typically portrayed as her leaving him to return to Jean-Paul Sartre, but I am not entirely convinced. Here is an excerpt from a letter that she wrote to him in 1950, when he had pulled back from her, dissatisfied with the relationship.
I am not sad. Rather stunned, very far away from myself, not really believing you are now so far, so far, you so near. I want to tell you only two things before leaving, and then I’ll not speak about it any more, I promise. First, I hope so much, I want and need so much to see you again, some day. But, remember, please, I shall never more ask to see you — not from any pride since I have none with you, as you know, but our meeting will mean something only when you wish it. So, I’ll wait. When you’ll wish it, just tell. I shall not assume that you love me anew, not even that you have to sleep with me, and we have not to stay together such a long time — just as you feel, and when you feel. But know that I’ll always long for your asking me. No, I cannot think that I shall not see you again. I have lost your love and it was (it is) painful, but shall not lose you. Anyhow, you gave me so much, Nelson, what you gave me meant so much, that you could never take it back. And then your tenderness and friendship were so precious to me that I can still feel warm and happy and harshly grateful when I look at you inside me. I do hope this tenderness and friendship will never, never desert me. As for me, it is baffling to say so and I feel ashamed, but it is the only true truth: I just love as much as I did when I landed into your disappointed arms, that means with my whole self and all my dirty heart; I cannot do less. But that will not bother you, honey, and don’t make writing letters of any kind a duty, just write when you feel like it, knowing every time it will make me very happy.
Well, all words seem silly. You seem so near, so near, let me come near to you, too. And let me, as in the past times, let me be in my own heart forever.
Your own Simone
In lieu of English (or French) notes, here’s some linguistics geekery to ruin your day (or, at a minimum, Algren’s poetry).
In this post, I introduced an intuition without actually backing it up:
The problem comes from the fact that lovely can (and usually is) an adjective, but can also be — super-rarely, I suspect — a noun.
How could one know whether or not it’s the case that it’s quite rare for lovely to be an adjective? Data, data, data.
I went to the Sketch Engine web site, where one can find all manner of corpora (pre-analyzed sets of linguistic data), as well as a nice interface for searching them. (No, they don’t pay me to shill for them–I pay a pretty penny for access to the site, which I use in my actual research.) I picked a corpus (the singular of corpora) called the enTenTen13 corpus. It contains a bit under 20 billion words of English from various and sundry sources, mostly scraped off of the web. The analysis that’s been done on this data consisted of using a computer program to “tag” the lexical categories (parts of speech to those civilians amongst you) of all of the words in it.
With that data, and a tool that will let me specify the part of speech for which I’m looking, I can do two separate searches:
- lovely as an adjective
- lovely as a noun
Why two searches? I wanted to know whether it’s rare for lovely to be a noun, so why didn’t I just search for lovely as a noun? Because numbers by themselves aren’t really meaningful: to know if a number–in this case, the frequency of lovely occurring as a noun–is large or small (why didn’t I say big or little? see previous posts about how there aren’t really any synonyms), I need to compare it to something else–in this case, to the frequency of some other word/lexical category. Which word, with which lexical category? Well, lovely as an adjective makes as much sense as anything else, so I did that.
Here’s what I got when I searched for lovely as an adjective. Notice that in the upper-left corner of the white-background panel, it says Query (lovely)-j: the “j” means adjective (for reasons that we need not get into, but it’s obvious enough to someone in the field that the Sketch Engine folks clearly didn’t see any need to explain it). You may be wondering: what about lovelier or loveliest? Gotcha covered–I actually did the search not for the “word” lovely, but for the “lemma” lovely, which means that the program is also looking for loveliest (you can see that it found an example of that, about halfway down the list)–and Lovely, Lovelier, and any other form with capital letters (and found one, 5 down from the top). The program found 943,084 tokens of lovely (or, more precisely, of the lemma lovely); we don’t know whether 943,084 is a lot or a little (remember the Best Movie Line Ever: 5 inches is a lot of snow, and it’s a TREMENDOUS amount of rain, but it’s not very much dick), but pas de souci, Sketch Engine does the math to convert that into a frequency: 41.49 occurrences per million words (see the gray bar (or grey if you’re a Brit) at the top of the white panel.
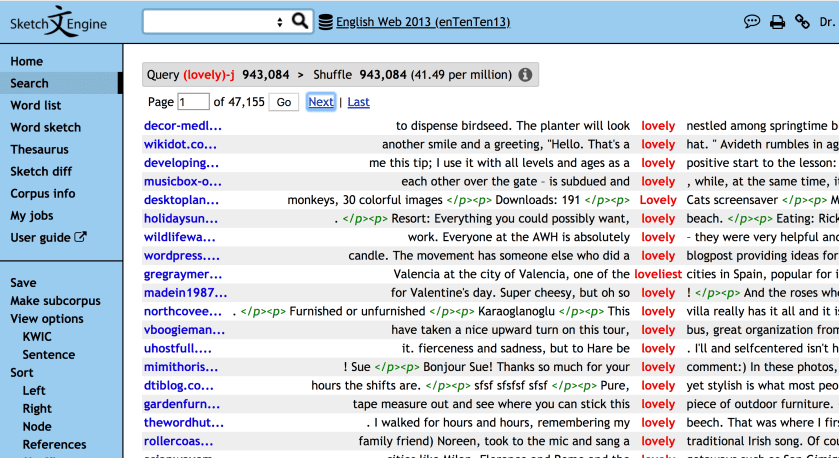
With a frequency for lovely as an adjective to which I can now compare the frequency of lovely as a noun, I did another search. This time, I looked for the lemma lovely, but as a noun. 6th from the top, you’ll see it pluralized–Kylie also kindly sent me various other lovelies including a gorgeous notebook… …and if you’re pluralized and in you’re in English, then you’re not an adjective. The frequency of lovely as a noun? Sketch Engine tells me that it’s 0.73 times per million words.
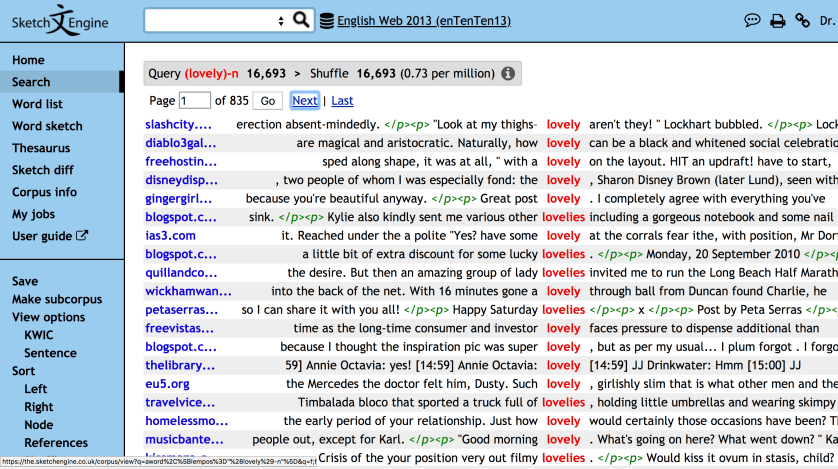
So, I get the following frequencies:
- lovely as an adjective: 41.49 occurrences per million words
- lovely as a noun: 0.73 occurrences per million words
41.49 is about 42 times 0.73, so indeed, lovely as a noun seems to be pretty fucking rare: my intuition has been supported by the quantitative data.
Now, I know what you’re thinking: Zipf, your computer program sucks–a LOT of the times that it thought that lovely was a noun, it was ACTUALLY an adjective:
- Look at my thighs–lovely aren’t they! (first line)
- Naturally, how lovely can be a black and whitened celebration… (second line)
Point number one: it’s not that it sucks–it’s that it makes mistakes. If there is a computer program that works with language and does not make mistakes, I have never heard of it, and a priori wouldn’t believe it if someone said that one existed. The question is: what kinds of mistakes does it make, and what can we learn from them?
- It’s making a frequent mistake of thinking that the adjective is a verb. It doesn’t have to be that way, right? It could have been the other way around.
- The mistake that we saw in (1) is a general one: it is too often judging the word to belong to the category to which it belongs most frequently. This is the typical pattern with any computer program that does things with language: when something is ambiguous, computer programs tend to be biased towards the most common “interpretation.”
- Therefore, when we look at the frequency of lovely as a noun, we know that it’s probably an over-estimate. Doesn’t have to be that way, right? We could just as well have gotten an under-estimate. But, since we’re looking at the less-frequent category here, and the program tends to erroneously assign the more-frequent category, we know that we should adjust our estimate of the frequency of lovely as a noun downwards.
Implicit in all three of these observations: in general, we are not getting frequencies of things–we are getting estimates of frequencies, where the difference between the estimate and the truth is affected by a lot of things, including how well the sample represents the world as a whole, the errors in our measuring instruments (in this case, the program that assigned the lexical categories, etc.
…and now, having undoubtedly sucked all of the joy out of Algren’s wonderful words–they’ve stuck with me since I was a teenager, but I’ve probably ruined them for you forever–I will head down to the Office française de l’immigration et de l’intégration–OFII, as we expats call it–to get my carte de séjour, and leave you to curse me. Feel free to post your own poems–it is, after all, National Poetry Month…

I’d write a little about your translation . Il se peut “bien” is to be avoided, too heavy, and in this case a French would rather say “il se pourrait”than “se peut” . Then after this phrase never use the future, “il se peut (or se pourrait) que tu trouves des belles …” Use the subjunctive after “il se peut” .
After this I thought for a while to keep the rhyme but also to have the same number of syllables, a must in French classical poetry . The idea of “Il se peut” can be expressed by non word for word translations so I made two 12 foot verses (the top of classicism, what we call “des alexandrins”, 12 foot verses with “la césure à l’hémistiche” ie a natural pause right in the middle, after 6 feet) that keep the meaning and the rhyme .
“Peut-être verras-tu un jour belles plus belles
Mais jamais ne verras de belle plus réelle” .
LikeLiked by 1 person
Oh my God, Algren in alexandrins–I love it! Thanks!!
LikeLiked by 1 person
I took the liberty of editing the post to include your comments and couplet–hope that’s OK!
LikeLiked by 1 person
No problem, it’s an honor .
LikeLiked by 2 people