
I recognize the difficulty of defining things like good and evil. I recognize the hazards of binarity: a lot of things in life just aren’t simple enough to talk about in terms of yes/no, up/down, right/left. Nonetheless: some things are just WRONG.

Case in point: labelling your y-axis in graphs. The y-axis of a graph is the vertical part. It typically indicates a quantity of something. Most quantities in life have some natural range of values. For example:
- Percentages can’t go lower than zero, or higher than 100. That’s just part of the definition of “percent.”
- Accuracy can’t go lower than zero, or higher than 1. That’s just part of the definition of “accuracy.” (Yes, accuracy does have a definition.)
- Minutes in an hour can’t go lower than zero, or higher than 60.
Not everything has a fixed range, right? For example: temperature has a minimum (the point at which all molecular movement ceases), but (as far as I know), it doesn’t have a maximum. Age can’t be a negative number, but if there’s an upper limit on how old something can be, I don’t know what it is. (Obviously, there’s a limit on how old I can be, and I won’t mind hitting it.)
Now, if you are graphing something that has a fixed range–percentages, you should have a y-axis that corresponds to that range. You’re graphing the accuracy of your man-eating-rabbit detector? No accuracy at all (i.e. always being wrong) is an accuracy of zero, and always being right is an accuracy of 1, so your y-axis should go from 0 to 1. You’re graphing the percentage of recently-fed post-pubescent man-eating rabbits that your man-eating-rabbit-electrocutor successfully electrocutes? The smallest possible percentage is 0, and the largest possible percentage is 100, so your y-axis should go from 0 to 100.
Why do I say this? Where the hell do I, an English major and an acknowledged innumerate, get off telling anybody how to draw their graphs? Who the fuck do I think I am–some Strunk and White of data visualization? No, not at all. You use y-axis ranges that reflect the natural range (if there be one) in your data for two reasons.
Reason number 1: Using a natural range helps your reader understand what you’ve found. The top and bottom of the y-axis are visual landmarks that your user uses to get the instinctive feel that graphics are so good for about the size of whatever effect it is that you’d like to convince them that you found. (English note: I don’t have a clue about whether your reader is male or female, so in my dialect, you use the “generic plural” them to refer to him/her/it.) Not using a natural range for your y-axis is failing to help your reader get your point.
Reason number 2: Not using a natural range can be completely misleading. I’ve never seen anybody use an enormously larger range than they should have. No: when people don’t use a natural range for the y-axis, they’re using a smaller range than they should have. What is the effect of using a smaller range than you should? It makes things look more different from each other. Why does looking more or less different matter? Because science is typically about finding the differences between things. These cancer cells got treated with Drug A and didn’t die, these cancer cells got treated with Drug B and did die–that’s a difference that will save some lives. What happens when your y-axis doesn’t show the full range of possible values? It makes it look like there are differences where there really aren’t any differences. It’s misleading, and if you’re going to claim that you’re doing science, you should avoid misleading people.
Yes: I am ranting. In fact, this is the kind of thing that I like to rant about when I teach. (Well, I don’t like to rant about it–it irritates me, and I would prefer that it not exist. But, rant about it I do. (See the end of this blog post for an explanation of that weird construction rant about it I do.)) But, somehow, when I’m teaching, I never seem to have an example handy, and I sometimes wonder if my students think that I’m ranting about a phenomenon that doesn’t actually exist. (I’m pretty sure that they think that when I rant about man-eating rabbits, but I haven’t actually asked.) So, when I happened to come across a stellar example today, I took a screen shot of it. I’m not going to tell you what the source was–to protect the guilty. Check it out. What do you think the point is of those columns labelled ours? It’s that their numbers are bigger than the other guys’, and therefore better. But, are they, really?
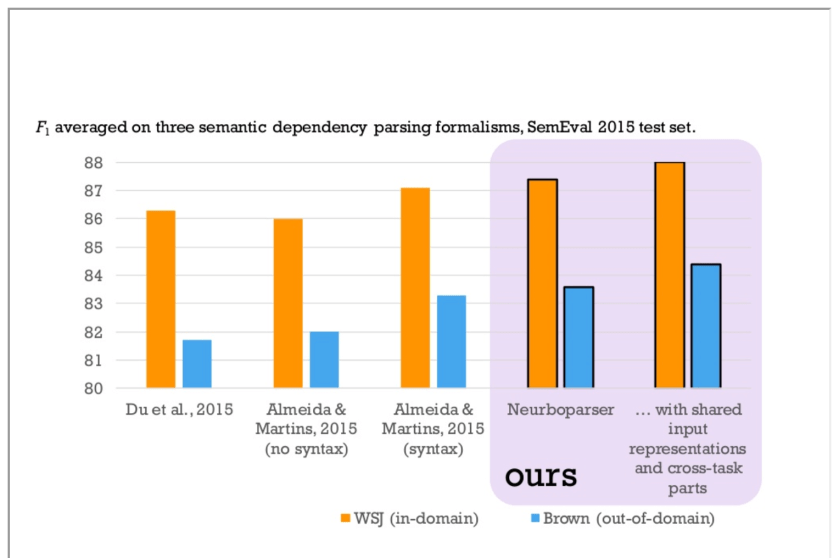
I think not. Are their bars higher than the other guys’? Yep. But, look at the values on the y-axis–the range is only from 80 to 88. They’re graphing something called F-measure, which has a range of possible values from 0 to 100. (Actually, it’s from 0.0 to 1.0, but I’ll let that go for the moment.) Their crappy y-axis range makes it easy to think that there’s some interesting difference there, but actually, there’s barely any difference at all between their score and the next-best score–that tiny difference means essentially nothing, and is more likely to be statistical “noise” than it is to reflect anything real. Note that these guys could have made the range be from 80 to 89 just as easily, but making it go from 80 to 88 means that if you don’t look closely, it looks like they have a perfect score–the orange bar goes all the way up to the top of the graph, right?
Sheesh.

Is this an early Monday rant?
Just been listening to the opening lyrics of the Eurythmics song “I saved the world today”.
The lyrics are apt as I am sitting hear wondering why everyone is conspiring to make my day job impossible this morning..
” Monday finds you like a bomb that’s been left ticking there to long”
LikeLiked by 1 person
I will freely admit that one of the two most perverse things about me is that I like Mondays–I love my job, and on Monday I’m rarin’ to go. (By Thursday I’m exhausted and it’s a totally different story, but we’re not talking about Thursdays here.)
The other perverse thing about me is that I LOVE first dates.
LikeLike
Sorry “here”
LikeLike