A blog about the implications of the statistical properties of language
Estimate your vocabulary size
When you figure out how to draw a representative sample of language, notify the linguists, because we sure as hell haven’t figured it out…
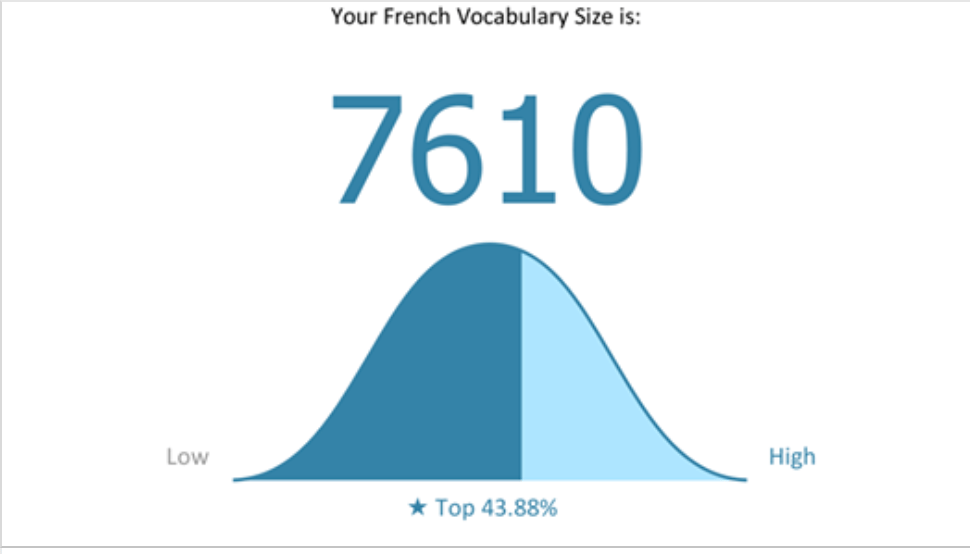
Want to see an application of Zipf’s Law? Go to this web site, where you can get an estimate of your vocabulary size in any of 21 different languages. I don’t know the details of how they come up with these estimates, but as an indicator of their accuracy (or lack thereof), I can tell you that my percentile placement on their English-language test was the same as my percentile placement on the GRE (the exam that you take if you want to go to graduate school in the United States). It estimated my French vocabulary size at just over 7,600, which seems reasonable–I would guess that I’ve been learning about 3,000 words a year for almost three years, of which I probably forget about a third due to not running into them a second time (Zipf’s Law: 50% of the language that you will run into today consists of words that occur only very rarely–but that do, indeed, occur), which would work out to just under 6,000; add in another 500 for the one semester of French that I took in college (“university” to you French-speakers in the audience) and you get within 10% of their estimate, which seems reasonable. (According to the web site, this lands me in the top 44% or so–of whom? No clue.)
How would you use Zipf’s Law to do this kind of estimate? Remember what the curve described by Zipf’s Law looks like:
Zipf’s Law: a small number of words occur very frequently, while the vast majority of words occur very rarely–but, they do occur. Credit: @ASvanevik.
One way to use this to estimate a vocabulary size would be to figure out how far to the right (towards 100) a person can “go,” so to speak. If someone can’t reliably understand words above a rank of, say, 20, there is a massive number of words that they don’t know. On the other hand, if someone can reliably understand words in the 90-100 range, their vocabulary is enormous. How do you turn enormous into an actual number? I have no clue how they do that–quantifying vocabulary size is hugely difficult, and as far as I know, it’s not possible to do it precisely for anyone, even for very, very young children. The SWAG approach would be to figure out the rank at which you stop recognizing words reliably, and then calculate the number of words above that rank. The Devil would, of course, be in the details–what texts would you use to determine your curve? Load those texts heavily with scientific journal articles about linguistics and someone like me would probably do pretty well–load them heavily with scholarly analyses of metaphors for love in Finnish epic sagas and I would probably do pretty poorly. Use a representative sample, you say? When you figure out how to draw a representative sample of language, notify the linguists, because we sure as hell haven’t figured it out…
Source: smile.amazon.com
Want to know some of the many technical details that make quantifying vocabulary size more or less impossible, even in principle? See pages 22-28 of my colleague Elisabetta Jezek’s book The lexicon: An introduction.
English notes
hugely: an adverb meaning “very.” Is it English? It first appeared in the language in the 12th century (along with archangel, asleep, dittany, lion, whoredom, and welkin–how cool is Merriam-Webster’s “Time Traveler” feature, and WTF is dittany??). Have you ever come across it before? Quite likely not–here are the relative frequencies of hugely and very:
Screen shot from the Google Ngram Viewer.
…but, it’s hard to argue that it’s not part of the language.
Want to see some cool shit? Click on the version of the graph that you see below. Do I REALLY think that this is cool? Yes. Is that fact related to the shockingly large number of times that I’ve been divorced? I would imagine so.
“Representative sample”, huh? That’s not a straightforward idea at all. The point is that you want the sample to faithfully reflect those aspects of the full population that you care about. And you can’t do that without specifying what you care about. If your study is going to be about gender, you will draw a different sample from a population of 10 women and 90 men than you would if your study was going to hinge on the effects of high-school grades, with no gender component.
Or you can decide that you don’t know what you care about, and adopt any process that you like. For example, the Brown Corpus was designed in the following funky way:
The list of main categories and their subdivisions was drawn up at a conference held at Brown University in February 1963.4 The participants in the conference also independently gave their opinions as to the number of samples there should be in each category. These figures were averaged to obtain the preliminary set of figures used.
This process produces a sample that represents, if it represents anything at all, the averaged mindset of roughly 1920s born English majors.
I just completed the English Vocabulary estimation and ranked in the top 6.33%. “Your vocabulary is at the level of professional white-collars in the US.” Interesting that it estimates to two decimal places and provides an antiquated example as a reference point. Great Fun!
Middle aged avid reader with a PhD. Scored in the top .01 percentile. Said I was “Shakespearean,” which seems a little over the top, but a fun quiz (and I do realize I’m using “fun” as an adjective here, not a noun).
I used arealme to test my Russian vocab size. I don’t know any russian, so I clicked randomly through the answers. It said I knew 4000 words which was the level of an 8 year old child.
I used arealme to test my Russian vocab size. I don’t know any Russian, so I just clicked randomly. In the end it said I knew 4000 words, like an 8 year old child.





“Representative sample”, huh? That’s not a straightforward idea at all. The point is that you want the sample to faithfully reflect those aspects of the full population that you care about. And you can’t do that without specifying what you care about. If your study is going to be about gender, you will draw a different sample from a population of 10 women and 90 men than you would if your study was going to hinge on the effects of high-school grades, with no gender component.
Or you can decide that you don’t know what you care about, and adopt any process that you like. For example, the Brown Corpus was designed in the following funky way:
The list of main categories and their subdivisions was drawn up at a conference held at Brown University in February 1963.4 The participants in the conference also independently gave their opinions as to the number of samples there should be in each category. These figures were averaged to obtain the preliminary set of figures used.
This process produces a sample that represents, if it represents anything at all, the averaged mindset of roughly 1920s born English majors.
LikeLiked by 1 person
I just completed the English Vocabulary estimation and ranked in the top 6.33%. “Your vocabulary is at the level of professional white-collars in the US.” Interesting that it estimates to two decimal places and provides an antiquated example as a reference point. Great Fun!
LikeLiked by 1 person
Yeah, two decimal places seems overly confident!
LikeLike
Middle aged avid reader with a PhD. Scored in the top .01 percentile. Said I was “Shakespearean,” which seems a little over the top, but a fun quiz (and I do realize I’m using “fun” as an adjective here, not a noun).
LikeLike
Sweeeet!
LikeLike
I used arealme to test my Russian vocab size. I don’t know any russian, so I clicked randomly through the answers. It said I knew 4000 words which was the level of an 8 year old child.
LikeLike
That’s pretty bad performance on their part! You designed a nice experiment–thanks for telling us how it turned out.
LikeLike
I used arealme to test my Russian vocab size. I don’t know any Russian, so I just clicked randomly. In the end it said I knew 4000 words, like an 8 year old child.
LikeLike