
I know, I know—computational linguistics sounds like it would be the most glamorous job in the world, right? We have a dirty little secret, though: 85% percent of our time is spent just trying to read in, and clean up, data files.
The novel coronavirus covid-19 has me on lockdown just like anybody else. What to do all day? Well, the National Library of Medicine, the Allen Institute for Artificial Intelligence, and some other folks whose names escape me recently released a corpus (set of linguistic data) of scientific journal articles that might or might not be relevant to covid-19 research, named CORD-19, and asked the artificial intelligence people of the world to see what they could do with it. Great—what else would I do all day?
For starters, how about fight to get the fucking files to open?

After that, we could clean some of the useless stuff out of the data—section headings (Introduction, Methods, Results…), puffery (important, significant), stuff like that…

Get rid of spaces and that sort of nonsense…
…and then make a TermDocumentMatrix, a “data structure” that lists all of the words in the corpus and the documents in which they occur (or all of the documents in the corpus and which words occur in them, depending on how you flip it).

We’ll try to make a word cloud, which will result in us watching several pages’-worth of error messages fly by (most of them removed for your viewing pleasure):


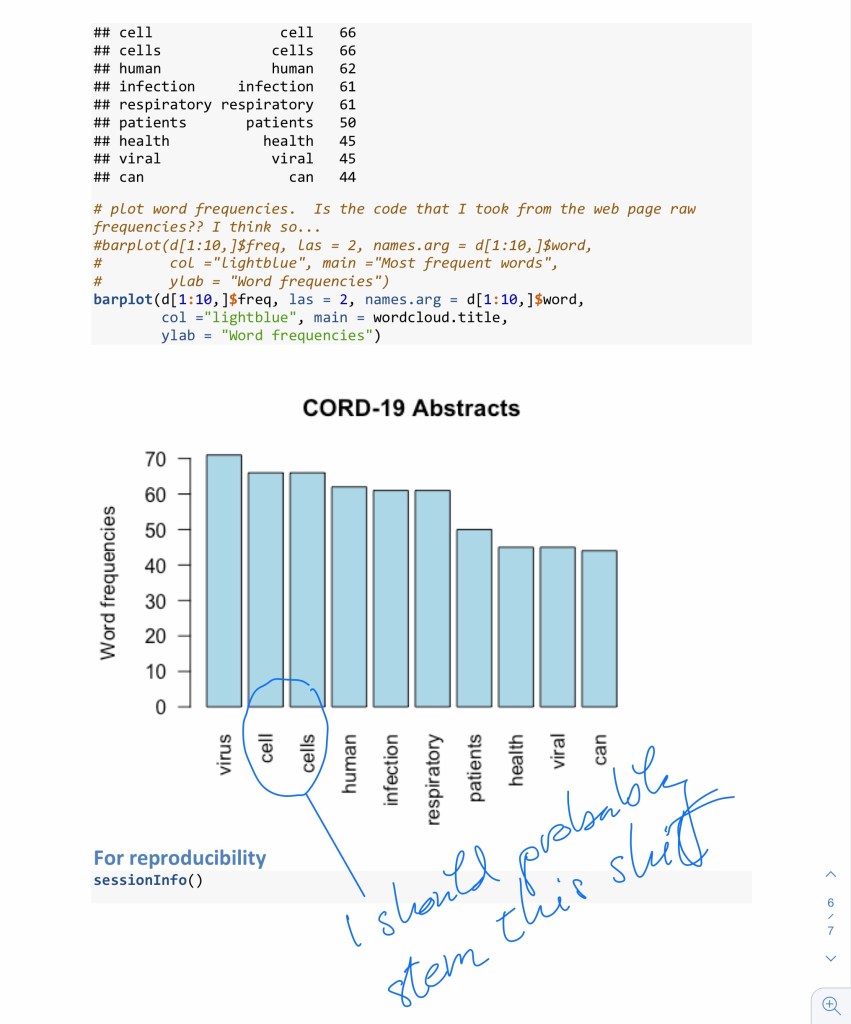
…and finally, we will record exactly what we did, in hopes of actually being able to do it on demand, which we obviously need to do immediately, or as soon as we fix the problems that we just identified, at any rate.


Indeed, I think 85% may be a lower bound from my personal experience with every NLP project I started.
LikeLiked by 1 person
Every PROGRAMMING project, in my experience 🙂
LikeLike