
For several years, my judo club in the States had a number of highly-ranked players on the junior national level. The coaches decided to take them to Mexico to train at one of the national Olympic training centers, and they brought me along to interpret. We spent a week at the training center in Guadalajara, and I interpreted for everything from practice sessions to our head coach explaining his philosophy of judo.
At the end of the week, we all piled into a bus and headed to Mexico City for the annual national tournament–a few of us grown-ups, our kids, and a lot of young Mexican children.
The bus ride was long, and going through the mountains, it was coooold. As kids got cranky and the ride got miserable, I decided to kill two birds with one stone: distract the kids for a while, and take advantage of an opportunity to improve my Spanish. I asked the busfull of kids what I sounded like when I spoke Spanish. Could they imitate me?
I thought that I would learn something that I already knew–hilarious imitations of my aspirated voiceless stops, ludicrously elongated syllable nuclei, vocalic offglides, and the like. I figured that the kids would get a laugh out of it. In fact, when you learn to do linguistic fieldwork on under-studied languages, you’re encouraged to go to adolescents for feedback–the idea is that teenagers being what they are, they might be less deferential than adults, and more willing to tell you the truth about how bad you sound. No one was biting, though.
Finally, I managed to convince one of the older guys to speak up. For once, the bus got quiet. Well…you always say estoy contento (“I’m happy”) instead of estoy feliz (also “I’m happy”).
The kids roared–apparently, they had noticed. They’re…you know…synonyms, he added apologetically. Sometimes you use synonyms wrong.
Now other kids jumped in with poor synonym choices that I apparently made quite regularly. Who knew?? It seemed to be the case that I made a lot of poor synonym choices, because this activity kept the kids in stitches for quite a while. A bus-wide global meltdown was averted, and we reached Mexico City without any major traumas.
This story came back to me today while reading the comments on a blog post that I wrote the other day about faces. A question came up: I gave the French words figure and visage for the English word “face,” but what about the French word face?
Simple answer: I didn’t know that the French word face meant “face.” To my knowledge, I’ve only ever heard it in the expressions face à and faire face à. My old nemesis: synonyms.
What is a synonym, though? Here’s the definition from Merriam-Webster:

Linguists don’t typically like that definition of “synonym,” though. Meaning is really, really hard to pin down (we’ve had a couple of posts on the difficulty of describing word meanings, looking at a number of options for doing so, none of which works out perfectly–see here for representing meanings with necessary and sufficient conditions, and here for representing meanings with prototypes). We tend to use a definition more like this: two (or more) words are “synonyms” if they can freely replace each other in all contexts. The idea would be that if you can say pail every place that you can say bucket, then they’re synonyms. If you can’t, then they’re not.
The thing is this: on this “distributional” definition of the term “synonym,” there are almost no synonyms. In American English, I can think of two pairs of synonyms:
- pail/bucket
- stone/pit (in the sense of the seed of a succulent fruit–a peach, or a plum, or an apricot)
Bullshit, you’re thinking–English is full of synonyms. Good, virtuous, righteous, moral. Bad, wicked, sinful, immoral. If you look at data, though, you’ll soon see that there are almost no words in English that have this characteristic of being freely replaceable. Rather, words that we think of as synonymous usually have subtle differences in how they’re used in the language. In technical terms, they have different “distributions.”
Let’s take two words that I imagine every native speaker of American English would think of as synonymous: big, and large.
All of the data on big and large in this post comes from Douglas Biber, Susan Conrad, and Randi Reppen’s 1998 book Investigating language structure and use, published by Cambridge University Press. The graphics are from my lecture notes and are based on Biber, Conrad, and Reppen’s data.
There’s a nice collection of naturally-occurring English texts called the Longman-Lancaster Corpus. It contains 5.7 million words from fiction and from academic prose. If you count the number of occurrences of big, the number of occurrences of large, and then convert those counts to frequencies per million words, you get this:

What are we seeing here? If we look at the combined texts, we see that large occurs more frequently than big, and that’s about it–not much of interest.
If we break out the two categories of texts, though–academic prose, and fiction–something jumps out at us. The two words have very different distributions in academic prose and in fiction. In academic prose, large is far more common than big. On the other hand, in fiction, big is far more common than large. What the hell?
Let’s look at the contexts that the words show up in. We’ll separate out academic prose and fiction, and within those categories, we’ll separate out big and large. For each one, we’ll show the most common words that appear to the right of the word in question.
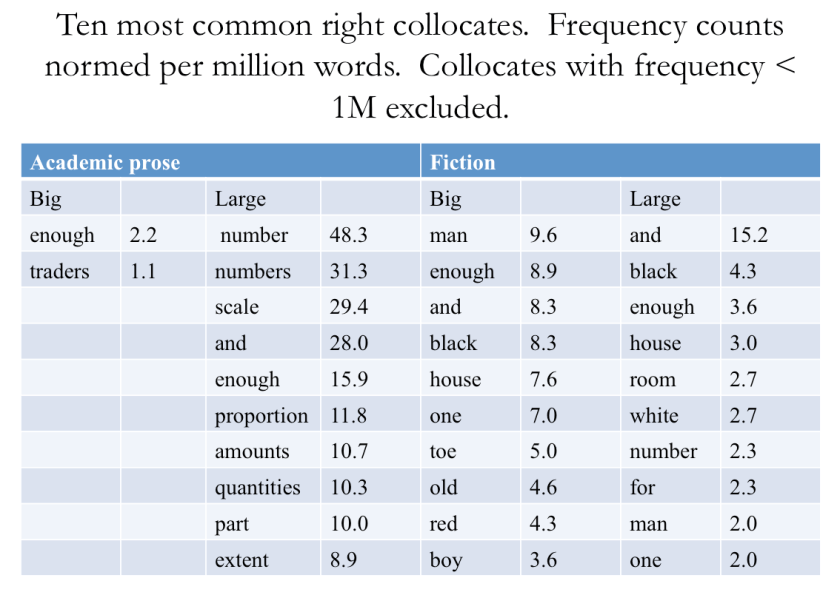
We’ll only show words that show up to the right of these words at least 1 million times. In the academic prose, that only leaves two–remember how big the bar for large was compared to the tiny bar for big in the academic prose part of the graph above. In fiction, we see both, although you’ll notice that the numbers for the words to the right of large in the fictional texts are much smaller than the numbers for the words to the right of large in the academic prose–large just doesn’t show up as often in the fictional texts.
Think about the two sets of words–the ones that show up after big, and the ones that show up after large–and you might notice something:
- big tends to appear before physical objects.
- large tends to appear before amounts and quantities.
How does that relate to the differences in the distributions of the two words across academic prose, and fiction?
- Fiction contains lots of physical descriptions, which can refer to size (and therefore uses big)
- Academic prose is more likely to use measurements to describe size (and therefore is less likely to use big)
- Academic prose deals more with amounts and quantities (and therefore uses large)
I’ll try not to drone on and on with details, but the effect is quite robust. It shows up at longer distances, such as when the words are separated by an adjective: big black eyes, big black saucepan, big black mongrel dog. It shows up when the words follow the words that they modify: The cart was not really big enough…. The revolver, which looked big enough to…. The ratio is large enough, however…. …a finite number of steps (which may be large enough to…
The moral of the story: could you substitute big and large for each other? You could–it’s not like it’s not interpretible if you say large revolver or big quantity. You probably do produce things like that–I’m sure I do, too. This stuff is probabilistic–it’s about frequencies, about what you do more often or less often, not about always or never. But: if you sound like a native speaker, you mostly don’t just swap these two words in and out randomly. The distributions are different: if you’re a native speaker, you don’t just substitute big and large for each other freely. You use them differently, in ways that are so subtle that you’re almost certainly not aware of it. (I sure as hell wasn’t before I read the book. I’ll point out that I’ve given linguistics graduate students the homework assignment of finding differences in the use of big and large for maybe ten years, and in all of that time, exactly one student has come up with this.)
So: back to the three French words visage, figure, and face, all of which correspond to the English word “face.” How the hell could I not know that face meant “face”? Why have I only ever heard it in face à and faire face à? And why can’t I figure out the difference between visage and figure? Let’s look at some data.
I went to the Sketch Engine web site. This gives me access to a bunch of big collections of texts in an astounding variety of languages, and a tool for searching those collections. The tool will also do analyses of statistical data–what other words a word tends to occur with in those text collections, what verbs it tends to be the subject and the object of (if it’s a noun), what nouns it tends to have as its subjects and objects (if it’s a verb), and so on.
I picked a corpus (collection of linguistic data) called frTenTen, just because it’s big–9.9 billion words. For each word–visage, figure, and face–I got an analysis of the words that it tends to occur with, and the structures that it tends to occur in–what verbs it tends to be the subject and object of, which prepositions it tends to modify and to be modified by, and so on. You can see screen shots of the three analyses below.
The first thing that we see is that the frequencies of the three words are different, and face is actually the most common. In 9.9 billion words of French text, this is how often they show up:
- visage: 115 times per million words
- figure: 48 million times per million words
- face: 258 times per million words
Seriously? How did I miss face, when it shows up more than twice as often as visage, which shows up more than twice as often as figure? If we look closely at how these words tend to combine with other words and structures, it starts to make sense. In what follows, I’m going to focus on two things: (1) the kinds of words that modify the word that we’re talking about, and (2) the kind of words that it gets coordinated with–in other words, what kinds of words show up on the other side of the word “and” or the word “or” with the word in question.
We’ll start with le visage. To begin with, let’s look at the words that modify it. Visage is a noun, so these are probably going to be adjectives. Why do I care about the words that modify it? Because different kinds of things tend to get modified with different kinds of words. Kittens are cuddly, warm, and cute. Sharks are hungry, vicious, and deadly. Knowing something about the kinds of words that modify something tells you something about how the people who speak a language think about that thing.
So, the words that modify visage: look at the box to the left in the figure below, labeled modifier. Here are the words that we see most frequently modifying visage in that 9.9-billion-word sample:
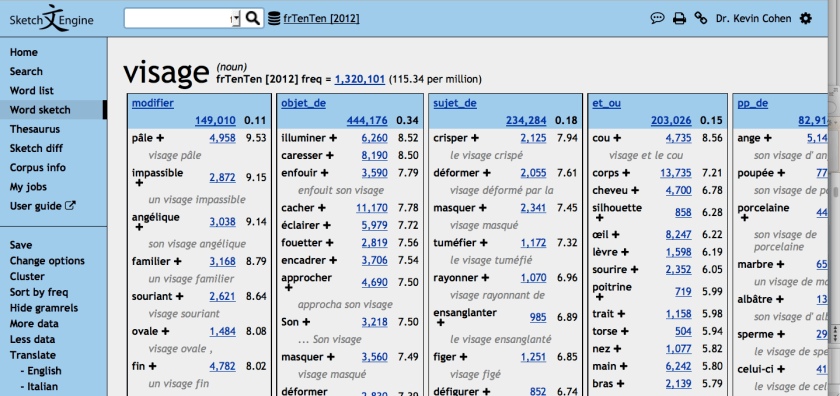
Definitions from WordReference.com:
- pâle:
- impassible: impassive, calm, emotionless, and many related words
- angélique: angelic
- familier: familiar
- souriant: smiling, cheerful, happy
- ovale: oval
- fin: in ths context: small or thin, according to what I found on Linguee.fr.
The generalization that I would suggest here is that these are all words that you would not be surprised to see being used to describe a human face.
Now let’s look at the words that most frequently show up with visage on the other side of the words “and” or “or.” I care about this because words are often combined by and or or with similar categories of words. For example, nouns tend to get joined with other nouns, verbs with other verbs, etc. This time we’ll look at the fourth box from the left, labelled et_ou. Let’s see if that suggests anything to us about how to understand visage:
- cou: neck
- corps: body
- cheveu: hair (this probably shows up as cheveu rather than cheveux because Sketch Engine oftend does something called “lemmatization:” converting all forms of a word into what you might think of as their “basic” form–in the case of nouns, the singular form)
- silhouette: profile, shape, contour
- oeil: eye
- lèvre: lip
- sourire: smile
The generalization that I would suggest here is that these are mostly body parts. Not surprising, if visage is a body part.
Now let’s look at the word that I’m struggling with–la face. Here are the statistics:
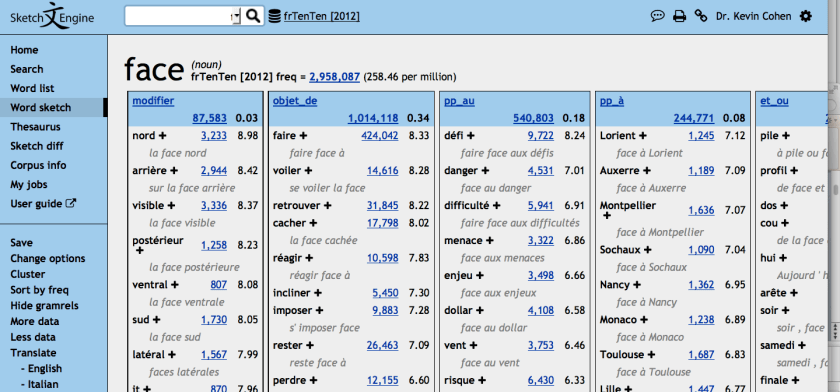
Once again, let’s look at the most frequent modifiers. Here’s what we get:
- nord: north
- arrière: rear
- visible: visible
- postérieur: back, posterior
- ventral: ventral (this word refers to the side that your stomach is on. To see why this is a useful word from an anatomical point of view, think about a person, and a fish. On a person, the belly is to the front, while on a fish, the belly is on the bottom. Using the word ventral lets you refer to the side that the stomach is on, regardless of the orientation of that side (forward, or down).
- sud: south
- latéral: lateral (side)
Here are some uses of ventral (and its opposite, dorsal)–scroll down past them to continue reading:


A totally different set of modifiers from visage! These sound a lot more like words that word describe one of the several faces of a mountain, or of a building. When we look for the words that face occurs with in coordinations with et or ou, we find:
- pile: In pile ou face, it’s “heads or tails.”
- profil: profile.
- dos: back
- cou: neck
- arête: bridge (of nose)
- soir: evening
- samedi: Saturday
- finale: final
Some of those are consistent with the interpretation of face as a body part–profile, back, necks, bridge of the nose. The others aren’t.
When we look at the “word sketch” for figure, there’s very little that suggests that the word is used as a body part–at any rate, not as often as it’s used for other meanings:
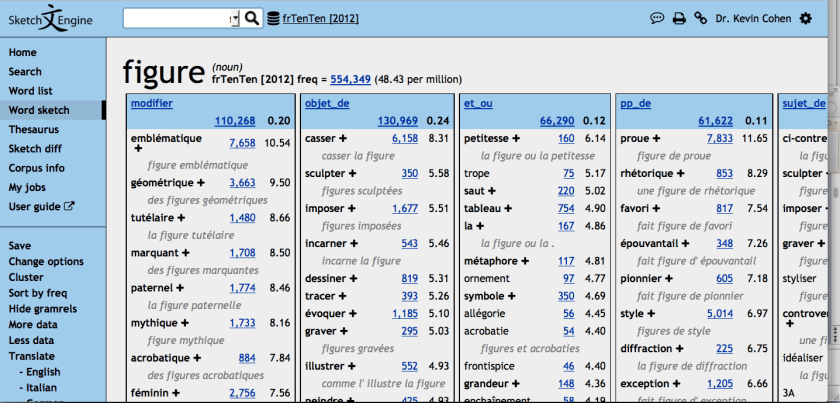

So, what insight does this give us? For one thing: it’s not surprising that I haven’t come across face with the meaning “face (of a person).” Rather, it seems to be used more often for the “faces” of objects–buildings, mountains, computers, etc. For another thing: it’s surprising that I’ve come across figure with the meaning “face” at all, since it doesn’t seem to be used for that as often as it’s used with other meanings. Finally, the major point: it’s hard to see any of these as synonyms for the others, as the patterns of usage are quite different. On the definition of “synonym” as “word that is freely replaceable for another word,” these aren’t.
Having said all of this: I don’t mean to imply that synonymy is not a useful concept. In fact, there’s an enormously useful resource called WordNet that is organized completely around the notion of synonymy. WordNet encodes relationships between words. But, what’s the definition of word? For WordNet, it’s what they call a “synset:” not a single word, but the full set of synonyms for that word. Synsets are the basic unit of WordNet–this whole (very useful, as I said) resource is organized as relationships between them.
The kids did great at the tournament. As Jigoro Kano, the founder of judo, would have put it: the ones who won got positive feedback on their training, and the ones who lost got valuable insight into the things that they needed to work on. I got off the plane in the US a couple days later with my boots coated with dust from an Aztec temple, and thought a lot about how small the world is these days.

I can tell you about “pile”, it’s in the expression “pile ou face” with a coin . I think you say “heads or tails” .
LikeLiked by 1 person
Thanks–fixed!
LikeLike
Now I can swear you “face” can be found in French books to mean the English face, and I heard it too in my life . “Il a pris le coup en pleine face”, ” Hé! Face de lune!” .
I agree with what you say about synonyms . I don’t study language from your angle, try to marry which teachings art can add to science, but we all know, we all feel at least, that official synonyms are not understood the same . We all painfully discover this when we start another language . Words don’t “convey” the same background in a culture we know nearly nothing about . Let’s just think to our own choices in our language when we use this “synonym” rather than that one at this particular moment . The background they convey is not the same, nor can be our intention in this definite moment : sometimes we choose a special word ( even slang rather than straight) deliberately to create the atmosphere we want to be the odor of what we mean .
So yes, “Synomyms are a Swindle !”
LikeLiked by 1 person
I totally believe you! We see that it’s not uncommon to be joined with “cou” or “dos,” so it does seem like it gets used as a body part. Apparently, it’s just not as frequent as “visage.”
There’s a great novel by Jonathan Safran Foer called “Everything is illuminated.” One of the main characters is a Ukrainian guy who interprets for the protagonist. Part of where the humor of the Ukrainian guy comes from is that he constantly misuses synonyms and collocations (“large sister” instead of “big sister”–“strong rain” instead of “heavy rain,” “heavy wind” instead of “strong wind”). It’s quite charming, really.
LikeLiked by 1 person
It must be fun . Not quite the same but there is a theater play called “Un mot pour un autre” written by Jean Tardieu in the first part of the XXth century. In this play nearly all words are replaced by another one but you nevertheless can perfectly understand the story . The play itself is a part of 8 plays collectively called “La comédie du langage” . Maybe a searcher like you could find materials for your quest ( whatever it is) .
LikeLiked by 1 person
I made it to the end of your interesting if very technical 🙂 discussion. When trying to enrich students’ vocabulary, working with “synonyms” is lots of fun, precisely along the lines you’ve pointed out: with examples, examples, examples, to try to convey the fine differences in usage.
LikeLiked by 2 people
Just stumbled upon your blog today on Twitter, but your visage looks familiar. 😜
Speaking of familiar, I am familiar with the use of face in connection with French audio cassettes, Face A / Face B or Face 1 / Face 2. I would expect a similar use on vinyl LPs. I’ve never seen it used for the human face, but I’m no expert.
Interesting use of Sketch Engine, which I’ve never seen before. I am on mobile only, so I have the Linguee app, the Reverso app, and VaTeFaireConjuguer app on my iPhone, plus a bookmark for L’Internaute.com
http://www.linternaute.com/dictionnaire/fr/
though I’m quite irritated by the new font and color scheme they just switched to.
LikeLiked by 1 person
Qu’est-ce que t’es fort ! 🙂 VaTeFaireConjuguer–great name. I’ll check it out. I love Linguee.fr for finding examples, and occasionally also Reverso.net (although lately I’ve only been getting definitions from that site–what’s up with that?).
LikeLiked by 1 person
Too bad WordPress comments don’t allow posting of images like Disqus does, otherwise I’d post some screen shots.
For on the spot definitions, I just use Apple’s internal dictionaries.
Linguee is my go to app, though, for more context and multi-word expressions, Multi word expressions,since it seems to boot fastest on my aging iPhone 5.
If I can’t find what I’m looking for on Linguee, then my next step is Reverso, which has two modes: the context lookup which displays definitions plus context examples, and the translation page your familiar with on the website.
Reverso has a premium version for a subscription fee of $4.99 per year, but I’m fine with the free version. If it was five bucks for a one-shot payment, I’d go for it just to get rid of the ads.
I like both of those apps for the pronunciation of words, but Linguee has much better recordings. (Or perhaps, it might be a matter of real people talking versus computer voices.)
As for VTFC, I like it better than other conjugation apps, because it displays two columns at once. I also like his word cloud presented when it first boots up. Saves a lot of typing.
Finally, L’Internaute.com has an app, but for some reason, the word of the day doesn’t update daily. Must be buggy. But the website is great for exploration, because the words in the definitions are all hotlinked.
And has lists of idiomatic expressions with short explanations of their origins. Plus, I really like the spelling videos, speaking of l’orthographe.
LikeLike
Does WordPress enable comment editing on the dashboard? Fair number of dictation errors and editing leftovers in that last comment. 😖
LikeLike
BTW MacSmiley, the link to your site seems to be broken.
LikeLike
Which site is broken?
Apple ditched it’s homepage service years ago, if that’s what you’re talking about.
I miss my homebase 😡.
I pretty much identify as MacSmiley everywhere on the Internet except Facebook or anyplace owned by Facebook, which officially requires a real name.
I haven’t posted to my WordPress blog in ages, since it was mostly set up just for trying it out.
http://macsmiley.wordpress.com
I occasionally post to Flickr and Tumblr, but these days I’m mostly active on Twitter.
LikeLiked by 1 person
I haven’t seen VaTeFaireConjuguer.com before. For conjugation, L’Obs has an app that I’ve been using. Do you like the VaTeFaireConjuguer app?
LikeLike
The broken one is the one that you are taken to if you click on your icon. The WordPress page looks fine. Checked out your Twitter feed–looks like we share some geekish tendencies…
LikeLike
“La comédie du langage” looks really interesting. I found a lot of copies, although it doesn’t seem to be playing in Paris at the moment. BTW, I’ve spent a lot of time recently trying to figure out when to use “langue” and when to use “langage”–everyone with whom I work does stuff with language, so it does occasionally come up around the office…
LikeLike
I can tell you but it may need a long paragraph because as for synonyms in general we might need several examples to make a foreigner integrate when using one or the other . But for sure when we mean the language, the fact we humans are able to speak and the abstract concept of codified oral communication, the right word is “le langage” .
LikeLiked by 1 person
OK–great! That’s the way I’ve been using it (with a disclaimer at the beginning of my talks pointing out that we don’t have the langage/langue contrast in my native language, and I apologize for any screw-ups).
LikeLike
Why, by Jove, apologizing ? Everybody on Earth understands a non native cannot speak freely . When in your place, I feel nothing but cursing against this present and f… handicap ! This happens everytime I write in English, ha ha .
LikeLiked by 1 person
A very reasonable question! Why apologize… in this case, a number of reasons, I guess. For one thing, the langage/langue contrast is one where I think that by screwing up, I could genuinely impede communication, and I try not to ever impede communication just so that I can speak French. Overall, choosing between English and French in a professional context in France is somewhat tricky for me. My number one principle: don’t let my language choice prevent progress. If someone’s English is a thousand times better than my French, then I’ll speak English with them. If I just can’t get my point across in French, then I’ll switch to English, and then go back to French when I’m on firmer ground. This works because almost everyone with whom I interact professionally is comfortable in English to at least some extent, at least as far as professional language is concerned. The flip side is that as far as I can tell, people appreciate the effort that I make to speak French in a professional situation, particularly when I’m giving a talk, which I always have the opportunity to prepare for, e.g. by making sure that I know the relevant vocabulary (modulo whatever residual mistakes come up with that). I would guess that this appreciation comes from some combination of the practical (not having to deal with technical content in English) and the social (appreciation that a hairy barbarian is trying to learn enough French to be able to interact in French in a professional context in France, versus just assuming that everyone speaks MY language, so why bother trying to learn theirs). That’s just a guess, though, mostly based on the little comments that I sometimes get after giving talks.
LikeLike
Each one of our languages is better to transmit certain informations ( I say French is a super vertical medium of transmission and English a super horizontal one), so in your present life it seems a good thing to use the most practical and change when it’s worthy .
You have to take care of social emotional interferences but you seem to get by well among all these obstacles . It’s only a question of proportions between the gain and the loss .
But apologizes no . Sure it’s a hassle when communication is impeded but you are no more supposed to be fluent in a foreign language than the hearers . So all of you can apologize in front of the Great Spirit of communication … and blame Babel tower builders .
LikeLiked by 1 person
Tell me more about horizontal and vertical, please?
LikeLiked by 1 person
This is quite personal . I have a high esteem for the initiatic meanings of many French words, multiple meanings that show the way in the quest towards the ultimate goal “γνώθι σαυτόν”, know yourself and you’ll know universe and gods . The verb “réfléchir” for instance, but there are many occurrences of this special quality . That’s what I call vertical .
(Old Egyptian was the best vehicle of this deeply wise help but it required somehow already enlightened minds . Then as humanity was going downwards Egypt produced a lower quality help when it created the Hebrew language . Different meanings in many words, words made by associations of different shorter meaningfull roots AND the mathematic “map”, for each letter is also a number, basis of Kabbalah . Later as humanity didn’t stop going down, old Greek and the last and still lower key, French and its philosophical verticality .)
Now English . Not involved in this matter at all but I remember when I discovered it together with rock’n roll, blues, motorbikes, adventures and eventually Hippies inspiration I adored the possibilities this primitive idiom offered . There are many things you are not sure about, or many things in which you cannot distinguish for sure among several impulses, many things for which I hated having to choose a specific word . And fortunately English was there, with its numerous vague terms that allow the speaker to just give a general indication, letting the hearer choose a flower, or better, feel the whole possibilities as a bouquet. By this time I readily switched to English vocabulary within a French speech when I felt the need for an imprecise concept . The word “feeling” is one of the gems offered by English . And I was not alone , by this time only a somehow marginal minority used English words now and then, unlike now when the lowest mediatized excrements, advertisements, are full of English .
LikeLike