
One of the hot topics in linguistics right now is mixed effects models. A mixed effect model is a kind of regression analysis. Regression analysis is a way of building a statistical model of a phenomenon. There are all kinds of things that you might want to build a statistical model of in linguistics, including phonetic relationships, sociolinguistics, syntax, and doubtless many others. I’m going to use this post to put up some links to things that you might find useful in learning about mixed models, and of course we’ll come across some French vocabulary on the way. (A note on the vocabulary in this post: it is mostly not found in dictionaries. I induced it from examples on linguee.fr, an excellent source for finding examples of French technical vocabulary in use.)
The absolute best material for learning about mixed effects models so far is this tutorial by Bodo Winter. If you’re not familiar with simple linear regression (i.e. with fixed effects only), you might want to check out this tutorial of his first. Besides being really clear, Bodo’s tutorial is especially suitable for linguists, because it works through an extended example on F0 (fundamental frequency–roughly, the pitch of your voice) variation in situations of different politeness levels.
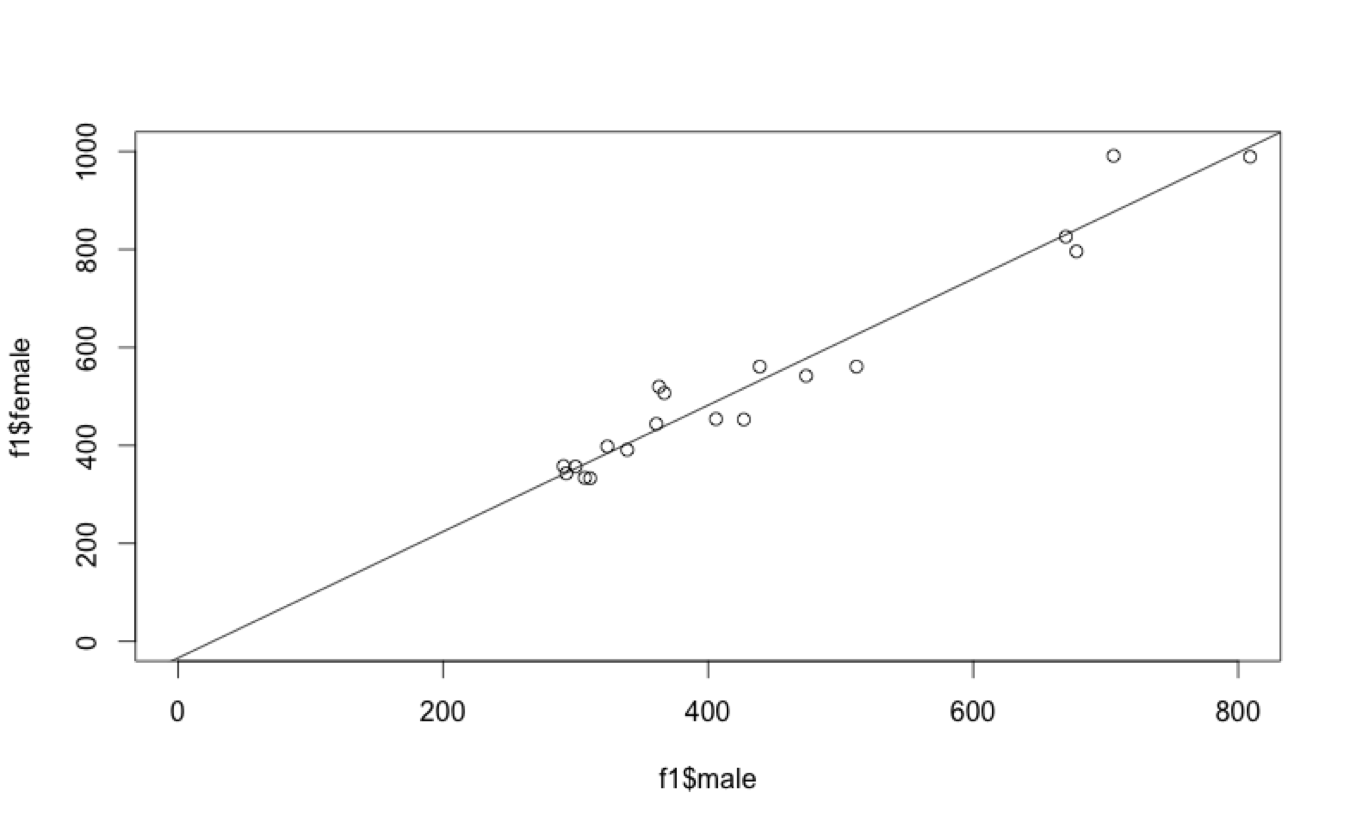
Let’s build up to the vocabulary of mixed effects models. First, some basic vocabulary for talking about regression modelling. Bear in mind that regression modelling–well, simple linear regression modelling–is about finding a formula that can predict the value for something on the basis of the value of something else. The figure to the left plots F1 (first formant frequencies–part of what makes a vowel sound like what it sounds like) for female speakers of several language over the F1 for male speakers of the same language. (The data comes from the web site accompanying Keith Johnson’s book Quantitative methods in linguistics.) The line on the plot reflects a formula that will let you predict the F1 of a female speaker if you know the F1 of a male speaker. Not surprisingly, the female frequencies are always higher–one of the determinants of overall patterns of F1 is that all other things being equal, the shorter your vocal tract is, the higher your F1 will be, and all other things being equal, women have shorter vocal tracts than men, on average. What the line says is that you can get pretty close to an accurate prediction of the female F1 if you multiply the male F1 by 1.29. (Yes, we’re glossing over the y intercept.) OK, now on to that basic vocabulary:
- le modèle: model.
- le modèle de régression: regression model.
- la régression linéaire: linear regression.
- la régression logistique: logistic regression.
- la régression linéaire simple: simple linear regression.
That got us through simple linear regression modelling. Recall that in simple linear regression, you’re predicting a value for something on the basis of the value of something else. But, most things don’t have simple one-to-one relationships. Rather, it’s often the case that you need to predict one thing on the basis of multiple other things. For example, suppose that you want to know what affects how long it takes a speaker of a language to respond to the question of whether or not a given sentence is grammatical (i.e., could be said in that language. Colorless green ideas sleep furiously doesn’t mean anything, but you could say it in English. On the other hand, green sleep colorless ideas furiously is something that you couldn’t say in English). You might have to include multiple things in the model–how long the sentence is, how frequent the words in the sentence are, how long the words are, etc. In this case–predicting one thing (response time) from multiple things (sentence length, word frequency, word length)–you need something called multiple linear regression. This brings up more vocabulary:
- la régression multiple: multiple regression.
- la régression linéaire multiple: multiple linear regression.
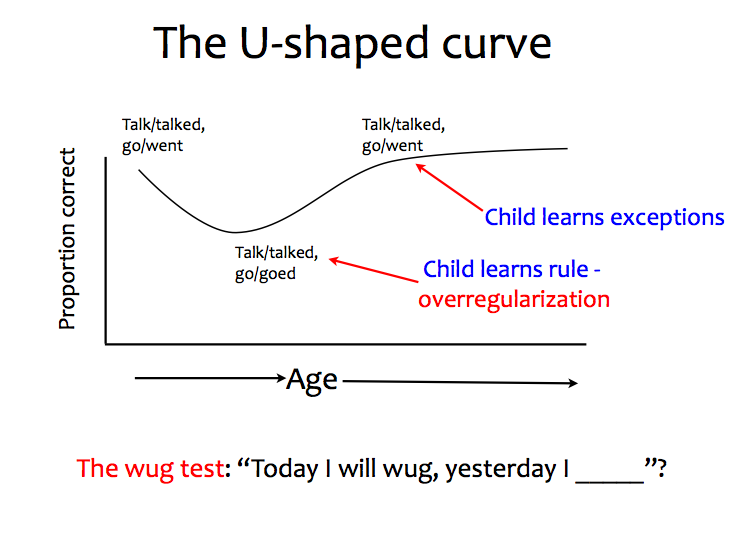
So far, we know how to talk about linear regression. What both kinds of linear regression have in common is that (a) we’re predicting a value from something else–from one value in the case of simple linear regression, or from multiple values in the case of multiple linear regression–and (b) we can describe the relationship between the value that we’re trying to predict and the value(s) that we’re trying to predict it from on the basis of a (straight) line. Some relationships can’t be described by a straight line, though. A classic example in linguistics is the U-shaped curve in language acquisition by children. This describes a common phenomenon relating age to the percentage of correct productions of some linguistic target–say, irregular plurals, or the past tenses of verbs. Initially, the child has a high percentage of correct productions. Then, the child goes through a stage where the percentage of correct productions drops. (As the figure suggests, this is thought to be because the child has made a transition from “memorizing” the regular and irregular forms to developing a hypothesis about a rule for forming plurals, or past tenses, or whatever.) Finally, the child’s percentage of production of the correct forms climbs again. Now we can’t describe the relationship between what we’re trying to predict (the percentage of correct productions and what we’re trying to predict it from (the child’s age) with a straight line. However, there is another kind of regression that we can use. It is called non-linear regression:
- la régression non linéaire: non-linear regression.
We’ve now talked about three kinds of regression modelling. They all have in common the fact that they are used to predict the value for something from the value(s) for something else. If we’re trying to predict one value from one other value, that’s simple linear regression (la régression linéaire simple). If we’re trying to predict one value from multiple other values, that’s multiple linear regression (la régression linéaire multiple). And, if the relationship between what we’re trying to predict and what we’re trying to predict it from can’t be described by a straight line, then we have non-linear regression (la régression non linéaire). (Before you ask: yes, there is such a thing as non-linear multiple regression, but I don’t know how to say it in French. Heck, I’m not even sure how to say it in English–non-linear multiple regression? Multiple non-linear regression? It’s pretty rare.) There’s one more kind of regression modelling that we need to talk about before we can move on to mixed effects regression modelling: logistic regression.
Logistic regression is used to predict the probability of something from something else. Up ’til now, we’ve been predicting a value; now we’re predicting a probability. What is the probability that a vowel will be unvoiced (whispered)? What is the probability that I will pronounce -ing, versus -in’? These are questions for logistic regression. I’ll leave out the details, but we need to know the vocabulary:
- la régression logistique: logistic regression.
OK, we can talk about a variety of types of regression modelling in French now. But, to talk about mixed effects regression modelling, we also need to be able to talk about effects. This post is already super-long, so let’s save that for next time. In the meantime, here’s a shout-out to Bodo Winter, regression-modelling explainer extraordinaire: https://twitter.com/BodoWinter.

One thought on “Regression models in French: Part I”