In America, we do love our dogs. A culturally common way for us to show our dogs affection is this: we pet them, while saying Who’s a good boy? (or Who’s a good girl?, depending on gender). In my family, we do it a little differently: we pet the dog while saying Who’s got a sagittal crest? Dogs don’t look at you with any more or less puzzlement regardless of which one you pick, so: feel free to go crazy with this one.
What’s a sagittal crest? The next time you run into a dog, run your hand along the center of the top of his skull. That ridge that you feel is his sagittal crest. Sagittalmeans along a plane that runs from the front to the back of the body. A sagittal crest runs along that plane. This sense of crestmeans something sticking out of the top of the head–think the plume on top of a knight’s helmet. Many animals have a sagittal crest, but not us modern humans. You see them in species that have really strong jaw muscles. A sagittal crest serves as one of the points of the attachment of the temporalis muscle, which is one of the main muscles used for chewing. If you have a sagittal crest, you can have a bigger temporalis muscle, which means that you can bite/chew harder.
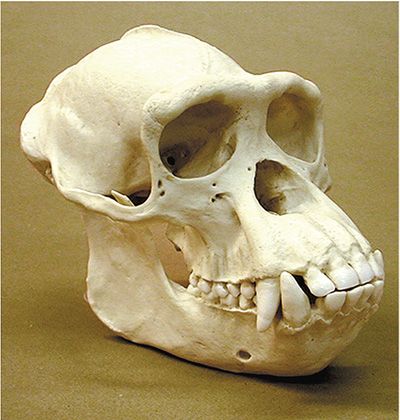
If you look at relatively close relatives to humans, you see sagittal crests on some of them. To the left, you see a gorilla. You wouldn’t want to get bitten by this guy. (Note that some gorilla species, especially their males, have really enormous sagittal crests–this is actually a pretty modest one, for a gorilla.)
Here’s (an excellent replica of) a Pan troglodytes (common chimpanzee) skull. This guy (I think it was a guy) had more of a sagittal crest than you (you don’t have any), but he didn’t have much, compared to that gorilla. Other chimps vary. Monkey species vary pretty widely regarding the presence or absence of a sagittal crest.
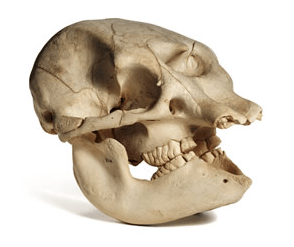
Some hominids that were ancestral to us had sagittal crests, but they disappeared pretty early in the course of our evolution. Here is a picture of the “Black Skull,” about 2.5 million years old. It’s from a type of Australopithecus robustus. By the time Homo erectus comes along (starting about 1.9 million years ago and lasting until about 70,000 years ago), the sagittal crest is gone. Picture below.
So: feel free to express your affection for your dog any way you want–you can’t possibly be any geeker than my son and me. Scroll down past the picture for French vocabulary.
I sat in a lab yesterday waiting to have blood drawn for some routine tests. If it’s in italics, it happened in French:
Lab tech: I’m going to take two you are staggering.
Me: (puzzled, miming staggering by walking my fingers randomly across the desktop) “To stagger” means to walk like this, right?
Lab tech looks at me for a minute, then laughs: I’m going to take two LITTLE TUBES.
Titubes is “you are staggering/stumbling/reeling.” Petits tubes is “little tubes.” Spoken casually, it comes out as p’ti tubes, and if you don’t hear the p, that sounds just like titubes.
There’s a lot we could say about the linguistic phenomena behind this, but at the moment, I’m feeling more impressed by the experience of interacting with the French medical system. The health care system here is one of the best in the world–there’s nothing you can get in America that you can’t get here. One of my foster brothers is a surgeon with a fascinating sub-specialty. He was sent here for a week during his training, because the surgeons in France were doing techniques that hadn’t made it to the US yet. (I find it ironic that Pasteur (the most important microbiologist of the 19th century) was French, and now America forbids French cheeses made with unpasteurized milk if they’re less than 60 days old. It’s going to go to 75 days soon, which will wreak havoc with the tiny bit of an artisanal cheese movement that we have in the US.)
Health care is universal here–it was declared a human right in 1948. In addition to being great, the health care here is not expensive. These routine blood tests done cost me $200 in the US every time that I have them done; here, along with a visit with a friendly young doctor who giggled adorably at my crappy French, they cost me exactly nothing. You gotta laugh at those Trump-voting Americans who sneer at socialized medicine, and then want a socialized snow plow to clear their street before work in the morning…
le système de santé français: the French healthcare system
Ta-Nehisi Coates tries to write in French. The red writing at the top of the page says “30+ errors.” What you have to realize is that in English, Ta-Nehisi Coates is one of the most articulate people you’ll ever read–or hear. Picture source: http://www.theatlantic.com/education/archive/2014/08/acting-french/375743/.
It’s the little things that get you. It amazes and frustrates me that I can spend an evening sitting at home, happily reading a novel that uses the passé simple and the imparfait du subjonctif (two tenses that are used in literary French, but almost never in speaking–we aren’t even taught them in school). But, then I’ll go to work the next day, and someone will say “good morning” to me in a way that I haven’t heard before, and I just stand there like a blithering idiot.
The Lawless French web site just posted an article that shows just how difficult the “easy” things can be. It describes a wide variety of ways to say yes in French. You certainly don’t have to use all of them yourself, but you most definitely do need to understand them. And, as far as I can tell, it’s even more difficult than you would think from the wide range of yes-meaning expressions. For example, I’m told that ben, oui (“well, yes”) can have different meanings, depending on the intonational pattern. Say it one way, and it expresses uncertainty in your yes answer; say it another way, and it expresses confidence in your yes answer.
One of the ways of saying yes that the Lawless French web site talks about is, I suspect, one of the most common mistakes that us Americans make in France. A thousand years ago when I was in college, I took a course on linguistic field methods–how to deal with a situation where you run into a language about which you have no information whatsoever. We did Hungarian for ours. We were all amazed when it turned out that Hungarian had two separate, non-interchangeable words, both of which meant yes, but which were used completely differently:
igen is what you might think of as the “usual” yes.
de is yes, but only when you’re contradicting something that someone has said. You don’t want any ice cream, do you? De. (Yes, I do.)
Although we were all fascinated by this, it’s not that unusual of a phenomenon. French also has a “usual” yes: oui. And, it also has a different yes that you use when you’re contradicting a previous assertion: si. Me, to my delightful office mate Brigitte (if it’s in italics, it happened in French): I can’t SSH into the server. Brigitte: Si–if you can connect to the internal network, you can SSH into the server. Si instead of oui because she’s contradicting what I said–I said I can’t, and her si means something like yes, you can.
Back to the classic American mistake: in America, if we have any knowledge of a second language at all, it’s most likely to be Spanish. Spanish has one word for yes, and it’s sí. Remember the “foreign language buffer” that I swore I would not tell you about? Put an American in a situation where they can’t communicate in English and the language that’s most likely to come out is Spanish, regardless of whether or not that’s the language that’s actually being spoken around them. So: ask an American in France a simple question, and if the answer is yes, they’re quite likely to say si, even if on some level they know that the French word is oui. I have made this mistake a thousand times, myself–I’m not any more immune to it than the next American.
So: check out the Lawless French web site for more ways to say “yes” in French than you ever could have imagined, and here’s hoping that you don’t sound as stupid as I do today.
I studied the head and neck with a Romanian anatomist. He had a delightful accent when he spoke English–think Andrei Codrescu. We spent a lot of time talking about the skull. There’s a lot to say about the skull–the 22 bones that make it up, the multitude of foramina through which blood vessels and nerves enter and exit it, the evolution of the middle ear from the characteristic multi-part jaw bones that you can still see in lizards, I believe. Regarding the forehead, though, about all that he talked about was a structure called the glabella–the little depression between the eyebrows and above the nose. The only known function of the glabella, he said, is to insert a stake to kill a vampire. Imagine that being intoned with a strong Romanian accent and you have a fine example of the humor that characterizes the typical anatomist.
One unpleasant characteristic of scientists: we can suck the joy out of pretty much anything. On the plus side, we can find something interesting to think about pretty much anywhere. Arguably, one of the least interesting aspects of the human face is the forehead. It’s easy to find poems that go into ecstatic descriptions of the eyes and the mouths of a loved one, but I don’t recall ever reading a poem that praised someone’s forehead. There’s a lot to say about the forehead, though.
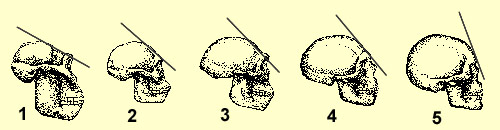
If you look at skulls of non-human great apes and of various extinct non-Homo sapiens species, one of the most distinct differences is that modern humans have a forehead, while the aforementioned others don’t, or at least don’t have the typical modern human tall, vertical forehead. Here is a nice schematic illustrating the trend in changes to the forehead over the course of human evolution (scroll down past it):
It’s also useful to look at the forehead across the range of great apes. Here is a nice picture showing frontal views of the skulls of a variety of apes, great and otherwise (scroll down past it when you’re done):
1) Hylobates hoolock, white-browed or hoolock gibbon 2) Pongo pygmaeus, the Bornean orang-utan 3) Male and female Gorilla gorilla 4) Pan troglodytes, the common chimpanzee 5) Homo sapiens (us) Picture source: http://www.nhc.ed.ac.uk/index.php?page=493.504.508.505.
The development of the skull over the course of growth from infancy to adulthood is especially interesting, as it’s a good illustration of the concept of neoteny. Take a look again at this picture that we saw in a recent discussion of the human chin:
The top shows the development of the skull of a chimpanzee, from infancy to adulthood. The bottom shows the development of the skull of a modern human, from infancy to adulthood. The thing to notice here is that the chimp starts out with a forehead, but it goes away over the course of development. The human starts with a forehead, too, but it doesn’t go away. This is an example of a phenomenon that is often observed in the course of evolution: new species may evolve through the retention of some characteristics of the infant. This is known as neoteny. So, a dog is in some ways like an immature wolf, a domestic cat is in some ways like an immature wild cat, and so on.
The changes in the forehead over the course of human evolution are associated with a larger brain size, but interpret this fact with caution. A larger brain size doesn’t necessarily mean more intelligence–a whale has a heck of a lot bigger brain than you do. I’m not aware of any evidence that a whale is in any sense smarter than you, though, with the possible exception of the fact that humans sometimes get forehead tattoos, while as far as I know, whales don’t:
I wrote up this little squib on how to review a grant proposal for students in one of our classes. No French here, sorry–our usual exploration of the implications of the statistical properties of language for second-language learning will continue tomorrow.
Global issues in grant reviewing
One of the biggest effects that you can have on science and on the future of science is your work as a grant reviewer for the National Institutes of Health. Your activities in this area will affect not just what kinds of research get funded, but the kinds of approaches that people take to doing that research. To give one big example of the past couple of decades, it’s reasonable to say that some of the genomics-based research that is so fruitful today has been possible only because grant reviewers stopped classifying it all as “just a fishing expedition,” having seen that “fishing expeditions” can be as useful as more traditional hypothesis-driven biology. So, when you get the call (well, today, when you get the email) inviting you to join a “study section,” don’t see it as yet another burden–realize that this is one of your opportunities to have a real effect on science in this country.
What I’ll describe here is my approach to writing a grant review. I’m sure that there are lots of others. Objectively, I can say that (a) this is a more efficient approach than other ways that I’ve tried, and (b) I’ve gotten very positive feedback from multiple scientific review officers at NIH since I started doing it this way, so I have at least one data point that’s consistent with the idea that this is a reasonable approach to the task.
One of the hazards of grant-reviewing is that you may often be asked to evaluate proposals that are outside of your strongest area of expertise. If you really and truly don’t think that you can give something a competent evaluation that’s fair to the investigators, you should certainly tell the scientific review officer so. (Do NOT wait until three days before the reviews are due to do this! You need to take a quick look at all of the proposals that you’ve been assigned as soon as you have access to them, and this should be one of the things that you’re checking for–ensuring that the proposal is not so far out of your area that you couldn’t possibly give it a professionally acceptable review. The other thing to look for: double-check for conflicts of interest.) One of the things that I like about the approach to the task that I describe here is that it can help you in writing reviews of proposals in areas in which you’re not necessarily strong, as the criteria are pretty general to scientific computing research as a field. Science is science, and if the investigators make their points well, you’re going to get them. If they don’t make their points well, then that’s not your fault–point out that they’re not making a very strong case for whatever it is that they want you to accept, and you’ll have helped them to improve their proposal.
Practical approach: reading the proposal
You’re going to have to read the entire proposal thoroughly once, and then you’re almost certainly going to have to skim it at least once. One of your goals is to do that reading/skimming, and the subsequent writing, as efficiently as possible. To that end, you’re going to do two things while you’re reading the proposal. One is that you’re going to highlight things–I’ll tell you what you’re going to highlight in a minute. The other is that you’re going to write very short notes in the margins. So: grab your pen and a highlighter. (You’ll note here that I’m assuming that you’ve printed out your proposals. Yes, I am so old that I still print out proposals.)
First step: read the RFA. You will occasionally see a proposal that just is not “responsive,” as we say, to what an RFA is looking for. This won’t typically be an issue with the “open calls,” but it’s not unusual with others. People have lots of approaches to deciding where to submit their proposals, and for some people, that boils down to submitting the same basic proposal to lots of different places with minor tweaks that try to make them seem relevant to the RFA when in fact, they really just aren’t. Also, some RFAs will have specific requirements that others don’t–maybe a dissemination plan, or a requirement to recruit students from specific under-represented groups, or what have you–and your reviewing responsibilities include ensuring that those specific points are addressed.
Having read the RFA, you’re now ready to start reading the proposal. When you do that, you’ll want to read it in such a way as to make it easier to write the review in the format in which it’s required to be written. At the moment, here’s what the required format is:
An “overall impression/summary.” This section describes what the proposal is about. Additional details summarize the strong and weak points very broadly. Overall, the picture that you paint in the impression/summary should make sense in terms of the overall numerical score that you give, and vice versa.
Specific scores for innovation, etc.
For each of those areas, specific lists of strong points and weak points.
So: you’re reading with your highlighter and your pen in hand. You’re going to highlight material that gives a good summary of what the proposal is about. You are completely free to use this material in your overall impression/summary write-up, and there’s some advantage to doing so, as it minimizes the chances of you mis-quoting the proposal. This might come from the introduction to the proposal, or it might be scattered throughout it, depending on the skill of the investigators who wrote it.
As you read, you’re going to mark in the margins anything that you think constitutes a strong point or a weak point, and which area of the review (innovation, approach, etc.) you think it’s a strong point for. You might also scribble a couple words in the margin to remind yourself what it was, exactly, that struck you as a strong or as a weak point. For example: the proposal says that Despite the obvious potential for accelerating biomedical research with better recognition and normalization of cell line names in GOA records, this problem has not previously been studied. In the margin, maybe you write + Inn. In other words: here’s something to list under “strengths” in the Innovation section of the review. Maybe the proposal says that We will write a look-up dictionary for every possible syntactic structure of the English language. Now you write – App in the margin, since this is something that you’ll want to mention under “weaknesses” in the Approach section–there is an infinite number of English sentences, so this approach is not very likely to work.
Talk about the work, not about the writer. Not the PIs do not make a convincing case that… but the proposal does not make a convincing case that… (The one exception to this is when you’re specifically asked to evaluate the investigator–more on that below.)
Try to think about the reviewing process in terms of being helpful, rather than fault-finding, and at least write as if that’s the case. So, for example, write The proposal could be improved by… rather than the proposal does not… Bear in mind here that you don’t just want to sound like you’re being helpful–you should actually try to be helpful! You don’t have to rewrite the proposal for them, but do approach this task from the good place in your heart.
Always try to find a strong point for every section of the review. They can be extremely generic–a strong point of the proposal is that cancer is a serious problem. They can be extremely specific. For example, if reviewing a spectacularly bad proposal on predicting sub-cellular localization from amino acid composition from an investigator at the University of Lower Slobovia, you might say something like this: The University of Lower Slovobia is very strong in the field of marmot communication. The scientific review officer will realize just fine that marmot communication expertise is not relevant to the likelihood of success of a proposed project on predicting sub-cellular localization from amino acid composition. If you say in the Significance section that Cancer is a fatal disease, the scientific review officer knows that if your only strong point is that cancer is a fatal disease, then you absolutely weren’t able to find any strong point of importance. And, don’t worry that saying one good thing about a bad piece of work will lead to crappy science getting funded–the fact that you’ve got one strong point and eight weak points will make it clear that the proposal needs a lot of improvement. You should, however, worry that not saying even one good thing about a bad piece of work might give a troublesome investigator an opening for hassling the scientific review officer about objectivity, or even just be unnecessarily hurtful to the investigator. You can always find one strong point, or almost always:
Innovation: Curing cancer would be novel and important.
Approach: Java does a good job with memory management, so this is a good choice of programming language for the project.
Distribution plan: SourceForge is a relatively stable platform for distributing code.
…you get the idea. These might sound flip and sarcastic to you, and it could be accurate to describe them that way, but if read on the surface, they’re pretty anodyne. I have occasionally run this specific kind of thing by scientific review officers to make sure that they don’t come across as sarcasm, and I have never gotten negative feedback on them. (That’s not to say that I won’t during the next review cycle–but, so far, so good.)
Those are general approaches to writing the review as a whole. There are also some specific things to think about when reviewing specific sections of an informatics proposal. For the Innovation section: is there innovation both in terms of the intended application (finding drug side effects that might indicate potential new uses in electronic health records, mining casual mechanisms from scientific literature, whatever) and also in terms of the informatics aspect of the work? This is potentially one of the toughest areas to evaluate if you’re not an expert in the field, but ultimately, it’s up to the investigators to make a strong case for the innovation of the project. ‘Fess up to gaps in your expertise–let the scientific review officer decide whether or not it’s OK for you to review the proposal.
Regarding the approach: here you’re looking for things that affect the likelihood of success of the work. This is potentially another tough area in terms of dealing with not being an expert, but there’s still a lot that you can do.
Look for aspects of the approach that clearly require specialized expertise in development and in testing. If the proposal has budgeted for a doctoral student to program a system requiring extensive experience with database design and security issues–something that you might conceivably hire a $200-an-hour consultant for–that’s a very valid thing to point out as a weakness of the proposal, as it just isn’t very likely to lead to success.
Who defines the use cases for the software? You want to see someone who is a potential user doing this, not, say, a software developer, unless the intended users are software developers.
Does the proposal include explicit plans for software testing, for ensuring robustness of the applications, and for maximizing the possibility of repeatability and reproducibility of the work? This is a rapidly growing area of concern in biomedical science, and it is likely to become much more so in the immediate future.
Don’t forget about data. Larry Hunter’s definition of bioinformatics is “doing original science with other peoples’ data.” Doing this requires that the data be available to you. If data is required: have the investigators demonstrated that data is available? By this time in your career, you’ve probably discovered that difficulties with getting access to data is one of the most common causes of failed course projects, missed deadlines, and the like.
Reviewers usually want to see back-up plans in case the proposed approach doesn’t pan out. Personally, I usually write these as things that are likely to be successful based on previous work, but that aren’t as innovative as what I’m actually proposing to do. You see proposals getting critiqued for not having back-up plans, but reviewers don’t typically find fault with the back-up plans themselves. (On that last point, your mileage may vary. I once wrote a proposal with a co-worker. We had very explicit back-up plans. One of the reviewers wrote: The back-up plans seem like a good idea. Why don’t the investigators just do that? Oh, well.)
There is a specific section of the review template for the investigator(s). This is the one place where you can’t avoid talking about the people involved (as opposed to my advice above to make your review about the work/the proposal, not about the investigators). This is an area where you can be really hurtful, which is not kind. It’s also a place where you can cause problems for the scientific review officer by saying things that a disgruntled investigator might be able to point to as evidence of lack of objectivity. You’re safe if you stick with the kinds of things that people usually address in this section:
Is this a senior person (in which case you need to check that they’ve actually committed time to the work)?
Is this a junior person (in which case you might want to point out specific evidence that suggests that they could manage the project, if you want to support the proposal, because lack of such evidence is a common way of trashing a proposal)?
Has the person worked in this area before, or are they trying to strike out in a new direction? The latter can be fine, if they have collaborators with suitable expertise.
Has the PI worked with the other members of the team before? If so: strong point. If not: weak point.
At some point, you need to look at the entire group of people involved. You might do this in the Investigator section, or in the Approach section. You’ll at least need to look at the types of people involved. (For an example of the latter: the PI might say that they would hire, say, a statistician, without specifying who it would be.) An informatics project that’s likely to be successful is going to have the right mix of researchers and technical people. At the risk of being redundant: a frequent problem that you’ll see is a researcher being tasked with implementing a super-complex computational platform that requires professional software development and testing experience more so than research abilities. Look for plausibility of software development goals given the number of people on the budget–an enormous project is not going to be built with just one software developer, but that may be all that you’ll find on the budget. Look for adequate software testing; look for requirements for special expertise, both in developing requirements, in developing software, and in testing software.
Another point on the entire group of people: if there is already evidence that they can work productively together, you should count that as a strength. Look for papers published together, previous grants involving the same group, etc. Conversely, if you are reviewing a big, complicated proposal with lots of dependencies between groups and potentials for lack of communication and the like, and the people have no history of ever having worked together before, then you should consider pointing that out.
UI design issues can be a big issue. Many people say that they plan to build a user interface, but don’t seem to think about how they will design the interface, or how they will evaluate it. In particular, people often don’t seem to plan ahead to involve users in the interface design and evaluation process. Having developers design user interfaces typically doesn’t work out well, and not involving users in this is a very legitimate weakness.
What counts as success, and how will you know if it’s been achieved? You don’t have to agree with the way that the investigators think that this question should be answered, but the investigators should at least tell you how they think it should be answered. Beware of statements like we will build a system that predicts protein subcellular localization that aren’t followed by some implicit definition of what build and predict mean.How will the program officer know whether or not the protein-subcellular-localization system has, in fact, been built? When the investigators go back for a renewal of the grant, how will the reviewers of the new proposal know whether or not this is something that was accomplished? How will the investigators themselves even know when they’re done? If I write a Python script with a predictProteinSubcellularLocalization() function that works for exactly one hard-coded protein, have I accomplished the aim? What if I build a beautifully engineered system with a user interface so intuitive that 5th-graders are now predicting subcellular localization just for fun from the comfort of their living rooms–but the predictions are never, ever right? What if I build a localization system, but it can only predict a subcellular localization once before the code auto-deletes? What if I build a system that has 2,000,000 users three weeks after I release it and quickly leads to the discovery of cures for every existing type of cancer, but I never publish a paper about it? Does that count? The investigators don’t have to define success the same way that you would, but they should be specific about what they’re going to produce.
The discussion session
There’s a rhythm to discussions of grants. The typical NIH routine is that:
Reviewer 1 presents a synopsis of the proposal, including the goal, the approach, and the main strong and weak points.
Reviewer 2 does not present a synopsis, and typically doesn’t repeat Reviewer 1’s points, although they may begin by saying something like I agree with Reviewer 1’s description of the proposal. Reviewer 2 then usually adds any additional things that they think need to be pointed out.
Reviewer 3 writes up only a short review, and doesn’t typically say much during the discussion, beyond adding any additional things that they think weren’t addressed by Reviewers 1 and 2.
When you’re Reviewer 1, be true to your analysis, but be as humble as you always are (or should be), and give as much real consideration to other peoples’ analyses as you always do (or should). (See this post for information about how to use a lack of humility and the failure to consider that other people might have valid analyses, too, to fully exercise your unemployment benefits.)
Learn from the experience
As with as anything else, you want to learn from the experience of reviewing grants. What you’re going to learn: how to write better grant proposals yourself. Thinking seriously about the critiques that you get on your own proposals is an excellent way to improve them–paying close attention to the issues that an entire room full of reviewers raise about proposals on a wide variety of topics is even more efficient.
People often sidle up to me at conferences, lab retreats, or receptions at the boss’s house. “I’m thinking about leaving academia and going into industry/Big Pharma/law school. What will that be like?” Here’s a response to that question, not from me, but from a colleague who went from an academic career in astrophysics to a job as a research associate in a biomedical informatics department. Here’s what that experience was like, both for him and for his spouse. Since he wrote this, he’s moved into a faculty position. His wife has gone into the private sector. French vocabulary at the bottom of the post, as usual.
As far as the transition from astrophysics, I’m terrible at giving advice, but I’ll tell you the experience of my wife and I. My wife was a liberal arts college professor and I was on my second postdoc. Both of us were working on high-profile cosmology experiments. Solving the 2-body problem and the stresses of starting a new family were coming into conflict with our careers, and so we realized we had to make a change. We had been doing astrophysics so long we literally had to mourn the loss of our future careers in the field – like we literally went through stages of grief. Part of it was thinking about all the time we had invested and all the connections we had made, part of it was that we couldn’t imagine doing anything else, and part of it was that we were doubtful we had the skill set to compete with statisticians, data analysts and computer scientists who had been doing what they were doing since they were freshmen in college.
Eventually, we realized that the time in physics and in academia wasn’t wasted, that we had learned a lot about how people and organizations function, and how to get things done. We also found that the physics data analysis methods and ways of approaching data were actually refreshing to people outside the field. We further realized that people with statistics degrees know a lot about logistic regression, sample size calculations, statistical tests, .. but they are more clerics – they approach problems from the point of view of “I’ve spent years learning tests, which test best fits the problem?”. This is in contrast to the approach of physicists who are expected to think of things from first principles and build things from scratch – scouring the literature for ways to solve problems, downloading random bits of code in whatever language and modifying it, … This is a huge advantage, because people think we are brilliant when really we are just not doing what the usual statistician would do. As far as computer science, yeah, we realized we weren’t programmers (my wife knows more about programming than anyone I know, but she’d probably have a hard time getting a job as a programmer at Amazon). Further, in talking to people, we found that software certifications, in some circles, are actually taken as a joke. So depending on where you’re applying, they may be more valuable, or less. Obviously, it was good to show we had some knowledge of programming. My only bit of advice: learn R – it is used everywhere. It will literally take you 20 minutes and you can put it on your resume. Eric Feigelson has some nice tutorials (e.g., https://www.google.com/?gws_rd=ssl#q=eric+feigelson+r+tutorial ). Also, Hadoop and Spark are pretty much industry standards, so you might think about learning something about them.
We also found many jobs BUT NOT ALL require you take ‘tests’ – almost like entrance exams filled with brain teasers and data science questions. I could never do them… but almost all of the interviews required us to give talks (an advantage, given our backgrounds in academia).
Anyway, I eventually obtained a job in bioinformatics analyzing language and speech production of patients with mental illness at a teaching hospital, and my wife eventually landed in a company doing consumer data analysis. The challenges are so absorbing, the only time I think about astrophysics is when my boss asks me about some new astronomical discovery.
We were also worried about things like time-flexibility, especially since we have kids– like having to work a standard set of hours and put in for time off, but (1) a huge number of work places now allow you to spend a lot of time working from home (it’s almost expected in some industries), (2) many work places have flexible times when you can come and go, and (3) putting in for vacation has enormous advantages. In astrophysics, I always felt like I had to be ‘on’ even during time off. Vacation is a way of telling everyone, “I’m gone don’t bother me” and they are forced to respect it. Also, speaking of the workplace, a lot of tech companies are still doing this ‘open office’ concept with no walls or anything. It’s annoying and counter-productive, but they often compensate by having spaces where you can hide, and often allow you to work from home much of the time.
We were also worried that we would be working in a place that looked like the movie “Office Space” – with people with ties speaking in cliché BS bureau-speak. There’s some of that (and it can be hilarious), but chances are you’re going to be working with other smart people who see through that stuff.
On a more superficial note, we also found that the word ‘astrophysicist’ carries a lot of weight. I have had Harvard-trained neurologists (the super-brilliant nerds of the clinical world!) who always introduce me as “an astrophysicist” as if I were a brain surgeon.
Anyway, the bottom line is, we realized we were way more valuable than we thought we were. Also, we realized we were looking for employers who were willing to take a chance with a person on a non-traditional background – i.e., non-cookie cutter companies run by people who understood that there would be a learning curve and respected our backgrounds. We discovered that they are few in number, but very much exist.
la science des données ou la science de données: data science.
les mégadonnées: “Big Data.” Le big data, littéralement « grosses données », ou mégadonnées (recommandé3), parfois appelées données massives4, désignent des ensembles de données qui deviennent tellement volumineux qu’ils en deviennent difficiles à travailler avec des outils classiques de gestion de base de données ou de gestion de l’information. (Source: Wikipedia.)
…and quantificational opposites relating expressions of quantity or expressions of part/whole relations:
et (and) versus ni…ni (neither…nor)
aussi (also) versus non plus (neither [in the sense of “also not”])
What does it mean to be an “opposite”? Let’s look up opposite in a few dictionaries:
diametrically different (as in nature or character) <opposite meanings> (m-w.com, definition 2.b)
being the other of a pair that are corresponding or complementary in position, function, or nature <members of the opposite sex>(m-w.com, definition 4)
Beingtheother of twocomplementary or mutuallyexclusivethings(thefreedictionary.com, definition 3)
What strikes me about this is that the definitions all refer to things in the world. However, I don’t know of any way to define a binary relation of oppositeness in the world, as such. Rather, oppositeness is a property of words. It’s what we call in linguistics a lexical relation–a relationship between two words, per se. So, in English, or at least in American English, it makes some sense to say that up is the opposite of down (the link goes to the antonym entry for up in WordNet), or that bad is the opposite of good (again, the link is to WordNet). But, these are relationships between the word up and the word down, between the word good and the word bad–there isn’t any clear way to define a notion of opposite between things, as opposed to between words.
We’ve talked a fair amount about ontologies in this blog–models of the things in the world and the relationships between them. If you look at ontologies–you can find hundreds of them here, all specializing in the biomedical domain–you’ll see that these models of things and the relationships between them have no notion of oppositeness. If you want to find the idea of oppositeness encoded, you have to look at models not of things, but of the words of a language, such as the WordNet entries that are linked to above. It’s entirely relevant here that many ontologists insist vociferously that WordNet is not an ontology. (Why you would wax vociferous over the question of what is and isn’t an ontology, I don’t actually know–there seems to be a certain religious element to the field…)
People act as if they think that other people have mental models that include some notion of being an opposite of something else. You can see this in metalanguage–talking about language (all quotes from brainyquote.com):
The opposite of talking isn’t listening. The opposite of talking is waiting. –Fran Lebowitz
I have a very strong feeling that the opposite of love is not hate – it’s apathy. It’s not giving a damn. –Leo Buscaglia
The opposite of bravery is not cowardice but conformity. –Robert Anthony
It strikes me as significant that Lebowitz, Buscaglia, and Anthony all are aware of oppositeness–but, they see it as something that you could be wrong about. This strikes me as an implicit awareness that oppositeness is not a property of the world–not something that you can measure, not something that you can quantify, not something that is obvious. If it’s not about the world, then what is it? Ultimately, being an opposite is a fact about the language that we use to talk about the world. We can talk about whether language has a role in reinforcing how we think about the world–does the fact that English only has two words referring to genders have the effect of constructing a binary opposition where there are actually many genders? Does language play into supporting dichotomies like colonizer/colonized, male/female, capitalism/Communism? Maybe. That doesn’t change the essence of the fact that oppositeness isn’t a property of the world. A property of systems, quite possibly–indeed, it’s a fundamental notion of structuralism, not just in linguistics but in the many relatives and descendants of structuralism in anthropology, sociology, literary criticism, psychoanalysis–on and on. Certainly we talk about those systems with language. But, that doesn’t change the fact that the opposites exist in how we conceive of and talk about those things–not in the things themselves.
Translating the word opposite from English to French is a tough one. There are different corresponding words for things, locations, directions–I stumble over them fairly frequently. One option for saying that something is the opposite of something else is l’opposé de or à l’opposé de. I don’t know when you would use one or the other. Here are some examples of each from the linguee.fr web site:
In fact, I think that taking life is the opposite of reproductive health.
Je pense d’ailleurs que la suppression d’une vie est à l’opposé de la santé génésique. (europarl.europa.eu)
The result is an attitude which is the opposite of true supporters and allies.
Avec pour résultat une attitude à l’opposé des fidèles soutiens et alliés. (esisc.net)
Red is the opposite of green, blue is the opposite of yellow and white is the opposite of black.
Le rouge est l’opposé du vert, le bleu est l’opposé du jaune et le blanc est l’opposé du noir. (thinkfirst.ca)
A “terroir” wine is the opposite of a technological wine.
Un vin de terroir est à l’opposé d’un vin technologique. (cave-cleebourg.com)
This is the opposite of what many people are now used to in other environments. fdisk(8) does not warn before saving the changes…
C’est l’opposé de ce que beaucoup de genspeuvent voir sous d’autres environnements. fdisk(8) ne demandera aucune confirmation… (openbsd.gr)
In this situation, branches are the opposite of “land rich and cash poor”.
Dans cette situation, les filiales sont l’opposé de ”riches en terrain et pauvres en argent”. (legion.ca)
The color example is a good one: Red is the opposite of green, blue is the opposite of yellow and white is the opposite of black.Red clearly isn’t the opposite of green in any scientific sense. Cultural sense? Sure. Blue and yellow? Not that I know of. Not even white and black? No–black has the same relation to red, green, and blue as it does to any other color.
I memorized the Learn French Avec Moi post on opposites–it’s a very useful linguistic concept. Check it out!
Two facts about chins: (1) Only humans have them. (2) No one knows why humans have them.
Two facts about chins: (1) Only humans have them. (2) No one knows why we have them.
The chin isn’t just specific to humans: it’s specific to modern humans. Earlier forms of us didn’t have them. I think it shows up around the time of Cro-Magnon Man, the earliest form of modern humans, about 45,000 years ago.
Homo erectus was around from about 1.9 million years ago until about 70,000 years ago. It’s probably an ancestral species to modern humans. No chin, though.
Neanderthals were around from maybe 250,000 years ago until about 40,000 years ago. I’m not clear on the arguments as to whether or not they’re ancestral to modern humans, but we probably inbred with them. No chin, in any case. (Note: I’m not a big fan of arguments that are only backed up by a single data point. For lots more pictures of Neanderthal skulls, go to Google Images. You still won’t find any chins.)
I’ve read that human infants don’t have chins, but rather they develop over the course of growth. From the skulls that I’ve looked at, this isn’t true–if you look at a human infant’s skull and the skull of any of a variety of apes, the human infant skull looks pretty distinct to me, in part because of the presence of a chin. A tiny, not-very-protuberant chin, sure–but, a chin nonetheless.
Do we really not know why modern humans have chins? We really don’t. Which is to say: a number of proposals have been advanced, but none of them is very convincing. Some of those proposals:
Chins protect the lower jaw from the mechanical stresses of mastication (chewing).
Chins protect the lower jaw from the mechanical stresses of speaking.
Chins are what is left behind after the rest of the face shortens over the course of human evolution. (Look at how far the adult chimp’s face sticks out in the series of drawings of human and chimp skull development; then compare the adult human face, which doesn’t stick out.)
Chins are meant to deflect blows to the face.
Chins come from unspecified “changes” related to reduction in testosterone levels over the course of human evolution.
None of these is a great explanation; some of them are very bad explanations; all of them are difficult to test. For some approaches to thinking about these various and sundry proposals, see any of these pages:
Some relevant French vocabulary for talking about the chin:
le menton: chin.
mentonnière: Although I can’t find this in the dictionary as an adjective, I think that it can be: Le mouvement volontaire de saillie mentonnière est assurée par l’extrémité de la sous-unité corporéale de l’os mandibulaire et par le muscle releveur du menton (aussi nommé houppe du menton ou incisif inférieur). “The voluntary movement of chin-projecting…” Can a native speaker verify this?
la mentonnière: chin-piece.
By the way: as MELewis has pointed out, if you want to have this discussion in any sort of detail, it’s important to have a definition of “chin.” In fact, depending on how you define it, you might want to say that elephants have independently involved a chin. Here are some pictures: an elephant skull, a mammoth skull, and a mastodon skull. All three of them show chin-like structures.
Parsing, data mining, and encryption are not going to get you. That pistol in your nightstand might, though.
Every once in a while an innocuous technical term suddenly enters public discourse with a bizarrely negative connotation. I first noticed the phenomenon some years ago, when I saw a Republican politician accusing Hillary Clinton of “parsing.” From the disgust with which he said it, he clearly seemed to feel that parsing was morally equivalent to puppy-drowning. It seemed quite odd to me, since I’d only ever heard the word “parse” used to refer to the computer analysis of sentence structures. The most recent word to suddenly find itself stigmatized by Republicans (yes, it does somehow always seem to be Republican politicians who are involved in this particular kind of linguistic bullshittery) is “encryption.” Apparently encryption is now right up there with dirty bombs in terms of things that terrorists are about to use to kill us all. (“All” might be an exaggeration. I find it interesting that the United States had 33,169 firearm deaths in 2013–roughly 11 times as many deaths as on 9/11–and yet, Republicans seem to think that it’s important that we make firearms as widely available as possible. I guess they just don’t like people very much.) As a moderately technical person, this strikes me as odd, since I’ve always thought of encryption as that nifty mathematical technique (I was about to say “algorithm,” but I think the Republicans are down on that one now, too) that keeps you from intercepting my text messages, me from reading your Ashley Madison profile, and so on.
In between the Republican outrage over parsing and the current panic over encryption, we had the sudden appearance in the public consciousness of data mining. As far as I knew up to that point, data mining was a bunch of statistical techniques for finding relationships between things. Suddenly it was showing up in scary news stories–Google the phrase “data mining is evil” (you have to put the quotes around it to search for the phrase, as opposed to the individual words) and you will get 1,400 hits as of the time of writing (May 2016).
Besides being bemused by this intrusion of American know-nothingness into public discourse, I have a personal stake in the issue, because people often refer to what I do for a living as text data mining. This is a misnomer–by its nature, data mining is not something that you can do with texts. Bear with me and I’ll explain why, and then we’ll look at some French vocabulary for talking about all of this.
Data mining is basically about databases. In a database, the statistical techniques of data mining can help you do things like discover that Republicans with HBO subscriptions are more likely to consider voting for Romney in a primary than Republicans who don’t have HBO subscriptions. (Real one, if I remember the facts correctly.) You can do that because you have a table in the database that tells who’s a Republican, a table that tells who has HBO subscriptions, and a table that tells you which members of a random sample told the interviewer that they would/wouldn’t consider voting for Romney in a primary. Data mining is the science/art of figuring out what things are related (HBO subscription/willingness to vote for Romney) and what things aren’t related (making one up here: having bought an Escalade and being willing/unwilling to vote for Romney in a primary)–this among probably thousands and thousands of variables. Doing data mining research requires things like knowing particular kinds of math, understanding how to sample a population, getting computers to do complicated calculations in a way that is time-efficient—stuff like that.
With data mining, you have that database, and you know what everything is. With “text mining,” or “text data mining,” as some people call it, you have texts, and you don’t know what anything is. (By “you,” I mean a computer program.) This is usually talked about as a difference between “structured” data (i.e., the database)–you know what everything “is”–what it “means”–in some sense, its semantics. Whoops–that sentence got a little out of control. “Unstructured” data: that’s typically how we would describe text. With text, you know what nothing is–you don’t know what anything means–in a very literal sense, you don’t know its semantics.
“Text mining” could be thought of as turning unstructured data into structured data. You’ve got a bunch of texts, and you want to use it to populate a database, perhaps. Maybe you have 23 million journal articles in the National Library of Medicine, and you want to find every statement that those 23 million articles make about which genes are affected by which drugs. Maybe you have a huge collection of French fairy tales, and you want (the computer) to find every time that a stepmother is mentioned and whether the portrayal of the stepmother is positive or negative. You could think of both of those as turning unstructured data into structured data–you’re taking that unstructured data and using it to build a database about drugs and proteins, or a database about stepmothers. You can see now why we tend to prefer the term “text mining” to “text data mining”–to the extent that “data mining” is about structured data, it doesn’t really make sense to talk about “data mining” with respect to language. Where the data mining person basically just needs to know math, the text mining person needs to know something about how people write about whatever it is that you’re interested in. I do a bit of text mining. People will have really specific requests–tell me whether or not the genes from some experiment show up in the cancer literature, say; tell me if this is a suicide note or not; read this doctor’s note and tell me if this kid is a candidate for epilepsy surgery; stuff like that. It’s not really linguistics, but it pays the bills, and it suits my need to do something that might actually make the world a better place.
A related field is natural language processing. Natural language means human language, as opposed to computer languages. Natural language processing is about building tools to handle specific linguistic tasks–parse a sentence, figure out parts of speech, stuff like that. You might use a combination of different language processing programs to do a text mining task. I find this more interesting, since the questions are less about some set of facts than they are about the language itself. Where the data mining person needs to know math and the text mining person needs to know how people write about genes and drugs, or stepmothers, or whatever, the natural language processing person needs to know something about language itself–what kinds of structures sentences can have, how word frequencies are distributed, how to build linguistic resources for letting a computer process things that can’t be directly observed (e.g. semantics). I do a lot of this kind of stuff. Recently I’ve been working on coreference resolution–how to get a computer to recognize that Obama, President Obama, and Barak Obama are all referring to the same thing in the world, while Mrs. Obama and Michelle Obama are referring to something else in the world. (Recognizing that those “things” in the world are people, as opposed to, say, locations, or the names of companies, is a whole different story.)
Yet another field is computational linguistics. This is about using computational models to test theories about language. This is my favorite, but it’s the hardest to pay the bills with. I do some of this, too. Nowadays a lot of my time goes into large-scale attempts to model the semantics of biomedical language. I’m trying to investigate differences in the semantic primitives of biomedical language versus “general” English by building a large set of data-driven semantic representations of predicates found in journal articles; I’ll then compare that resource to a similar resource built for general English and look for things like whether or not the semantic primitives seem to come from the same set, whether or not given verbs have different representations in the two types of language, etc. My hope is to get a sense of the range of types of semantic variability from this particular project. You could imagine using computational linguistics work to build natural language processing tools, and then using those to carry out practical text mining tasks. You could use the text “data” mining results to do actual data mining.
Mathematical representations of semantics can define how the gender binary gets manifested in English. This diagram transforms gendered word relationships into a map-like space. Pairs like girl/boy and aunt/uncle have the same “spatial” relationship. Picture source: http://www.offconvex.org/2015/12/12/word-embeddings-1/.
As you can tell from my examples, I’m very much in the world of biomedical language. There’s also a lot that you can do in the humanities with this kind of stuff. A hot topic in the future might be using mathematical representations of semantics to study things that are/are not thought of as binaries–gender, sexuality, race, political economy, whatever. However, I would not claim to do ANY of that–I can just barely explain it. For more on that kind of stuff, see this excellent post by Ben Schmidt.
In practice, even people in the field don’t always differentiate between these terms, or at least don’t draw sharp boundaries between them. My business card says that I’m the director of a text mining group, but I identify most strongly as a computational linguist. We figured that “text mining” makes more sense as a practical field of inquiry to have within a medical school (which is where I work), so that’s what we called the group when we formed it. If you go to the annual conference of the Association for Computational Linguistics, you will see almost no computational linguistics, but rather a ton of natural language processing. If you go to the annual Biomedical Natural Language Processing meeting, you’ll see a mix of text mining, natural language processing, and a bit of computational linguistics. Sometimes the distinctions really matter, though. This post started its life as a response to someone who asked me to be on a panel about data mining, to talk specifically about text data mining. When I responded that I don’t do data mining, they asked what the difference is–this blog post started out as my response.
As far as I can tell, the relevant community in France doesn’t make these distinctions in any kind of rigid fashion, either, despite the much-vaunted French penchant for categorization (see Nadeau and Barlow’s excellent book for a discussion of where it comes from). However, French does have technical vocabulary for all of these fields. Here it is:
fouiller: to excavate; to rummage through, to search (see also here)
la fouille de données: data mining
la fouille de texte(s): text mining
le traitement automatique des langues naturelles: natural language processing
la linguistique informatique: computational linguistics
La grande guerre, “The Great War,” the First World War, World War I, The War To End All Wars, was primarily fought in France. I can’t imagine how to talk about all of the ramifications of the effects of the First World War through French history, art, politics, even cuisine; certainly European history, and indeed, the history of much of the planet. It would be pretty fair to say that the European refugee/migrant crisis today is related to the fact that Germany is incredibly welcoming to refugees; that Germany is so incredibly welcoming to refugees today because it murdered millions of civilians during the Second World War; and that the Second World War came about in part due to the effects of the First World War. (You’ve probably heard it said that “the first shot of the Second World War was the Treaty of Versailles“–the codification of the German terms of surrender at the end of the First World War. The treaty contributed enormously to the German sense of humiliation that helped to build support for the next war in 1939.)
Military language has a very rich vocabulary of its own. It includes both technical language, and slang. The French military is one of the most highly developed in the world, and the French language has a rich military vocabulary. Here are some words that you would need to know in order to read about the First World War in French. Bear in mind that I have no idea how many of these are still in current use, or not. Can native speakers help? A couple of these are cavalry terms. France still had active cavalry units in the First World War, and Céline’s Bardamu in Voyage au bout de la nuitserves in a mounted unit.
la tranchée: trench.
le fourgon: ammo truck. In general French: a truck.
le dragon: A cavalryman. From the 8th edition of the Dictionnaire de l’Académie française: Il se dit aussi d’un Soldat d’un des corps de cavalerie de ligne.Il est dans les dragons.Régiment de dragons. Colonel, capitaine de dragons. Le casque d’un dragon. “It is also said of a soldier of a line cavalry corps.” I found this one as early as the first edition of the Dictionnaire de l’Académie française, published in 1694: On appelle, Dragons, Des arquebuziers a cheval, qui combattent tantost à pied, tantost à cheval.Les dragons d’une armée. une compagnie de dragons. Capitaine de dragons. “We call Dragons, mounted arquebus carriers, who fight sometimes on foot, sometimes mounted.” (Don’t you love that tantost, where current French has tantôt? See here for more from various and sundry historical dictionaries.)
le brigadier: a brigadier general. It can also indicate a corporal; I think this might be somewhat specific to the cavalry. Here’s part of the entry from the 6th edition of the Dictionnaire de l’Académie française, published in 1835: Il se dit maintenant Du militaire qui a, dans la cavalerie, le grade correspondant à celui de caporal dans l’infanterie.Brigadier de chasseurs, de dragons, etc. “It’s now said of the soldier who, in the cavalry, has the rangk corresponding to that of a corporal in the infantry.” Later, in Emile Littré’s Dictionnaire de la langue française, published between 1872 and 1877, we see this: Titre donné au soldat revêtu du grade le moins élevé dans la cavalerie. “Title given to the soldier decorated with the least elevated rank in the cavalry.” (See here for more from various and sundry historical dictionaries.)


























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}