Bring these medications to Ukraine when you come to volunteer and your contribution will be even bigger.
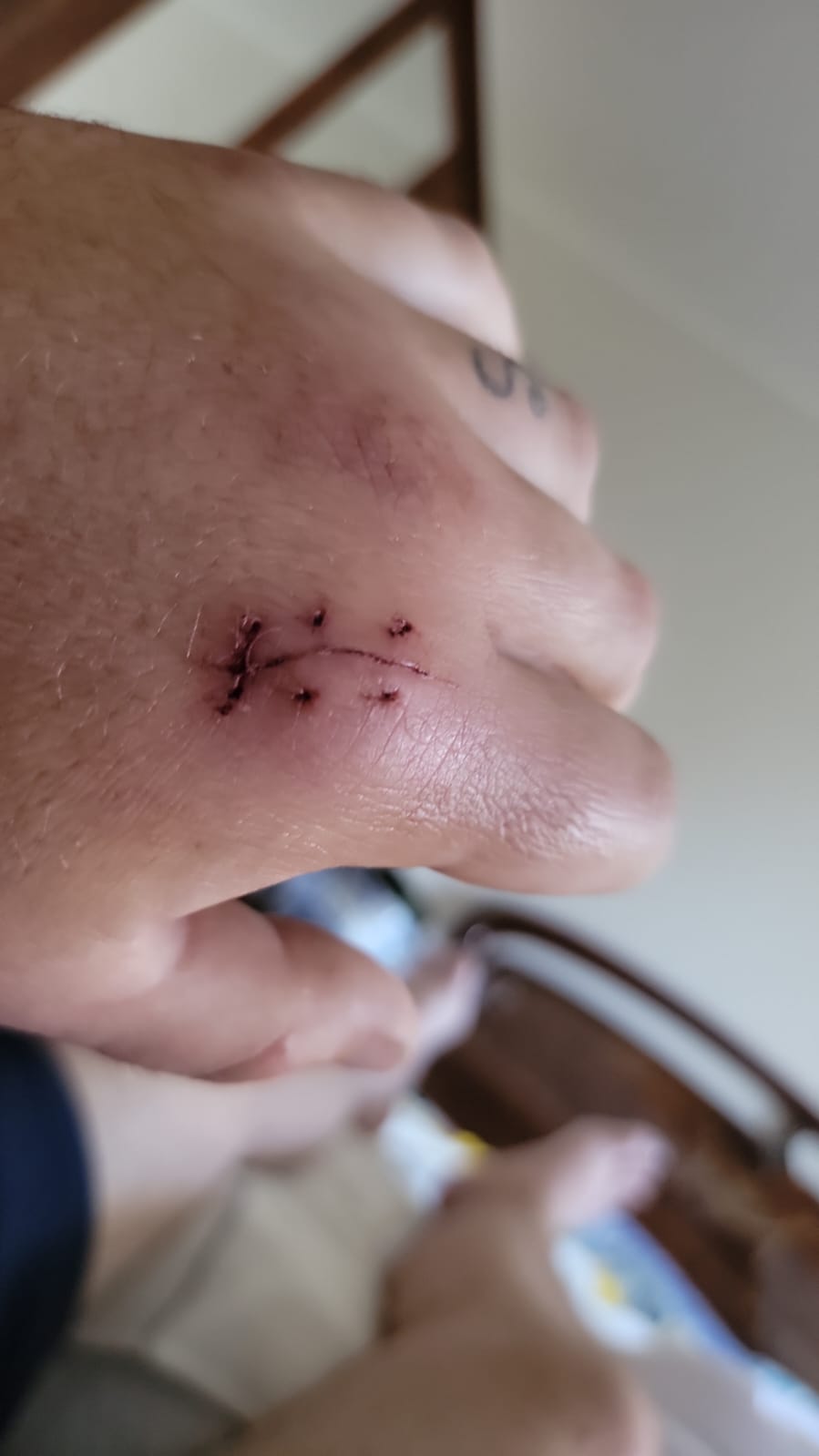
Moxifloxacin is what an American combat medic will give you if you have a penetrating wound. I have no idea how to find it in Ukraine, but your doctor can give you a prescription for it. I was very, very happy to have some with me here when a frightened cat sunk a fang very, very deep into my arm. (I was also very, very happy to have clear ballistic glasses with me when I was trying to get her out from under a bathtub while she was trying to scratch me to death, but that’s a topic for a post about ballistic glasses, right? Fang explained in the English notes at the end of the post.)
Do not bring aspirin or ibuprofen. US Department of Defense guidelines say not to take them for a week before entering a war zone. And, yes: since Putin deliberately targets civilian targets of no military value, all of Ukraine is a war zone.
Meloxicam is what an American combat medic will give you for any battlefield injury. See above regarding the situation in Ukraine.
Acetaminophen (sold in the US as Tylenol or in generic form) is the third thing that an American medic will give you if you are injured.
The antidiarrheal medication of your choice. You shouldn’t travel ANYWHERE without this anyway.
All medications that you normally take. Bring more than you think you will need. All problems in Ukraine are supply chain problems, so do not assume that you will be able to buy ANYTHING wherever it is that you happen to find yourself. Yes, I do understand that it is difficult to get more than your allotted quantity of prescription medications in the US, since your insurance company rations your health care.
Want to help the situation in Ukraine? Base UA/База ЮА is an excellent organization doing evacuation of civilians from the front lines (and a bunch of other stuff). I vouch for them completely. Send PayPal contributions to donate@baseua.org, and please mention that you found us through the Zipf’s Law blog.
fang: “A fang is a long, pointed tooth.” (Wikipedia) Fang often occurs with the verbs to bare and to sink into. Examples from Sketch Engine, purveyor of fine linguistic corpora and tools for searching them:
He sank his fangs into her shoulder.
Spike longed to sink his fangs into Xander’s hot flesh.
“Then you deserve this,” he said as he sunk his fangs into the man’s throat and drank hungrily.
Sink those fangs into one of our mini milk chocolate caskets.
How I used it in the post: A frightened cat sunk a fang very, very deep into my arm.
Volunteering in Ukraine? Choose your clothes carefully and your life will go smoother.
No English notes for this post, sorry… For those of you who read this blog to learn new English-language vocabulary, you will find links to the definitions of the words that I would have talked about if I had the time.
“Hot extractions:” rescuing civilians from the front line. This is a common job for foreign volunteers in Ukraine.
Don’t bring cammies unless you are pretty sure you will be joining a military unit. There is currently a regulation against wearing camouflage unless you are officially associated with the military. Also, if you are doing hot extractions, it scares the civilians who you most want to reassure.
Do bring obviously American t-shirts, a ballcap with an American flag or similar insignia, and whatever else you wear that marks you as obviously American. It is a big morale boost for the locals, and they will be very nice to you. (Note that many men wear a ballcap and a “tactical beard” here, so don’t rely on those alone to communicate to people that you are an American.)
Don’t bring 100% cotton t-shirts. You will be hanging up your clothes to dry, and 100% cotton t-shirts take way too long to dry.
Do bring kneepads. Whether you’re fighting, doing hot extractions, or teaching TCCC, you’re going to spend a lot of time kneeling on the ground. Elbow pads might be less necessary–depends on what you’re doing.
Do bring shower shoes–not for showering, but to wear in your living quarters. Ukrainians tend to be maniacal about keeping floors clean, and they don’t wear outdoor shoes inside except in public places. I have even seen guys wearing shower shoes in military headquarters! One US military veteran doing hot extractions here with me commented that he had never seen more Crocs in his life than in Ukraine–this is why. Shower shoes can be bought in Ukraine, but not necessarily in the areas where there’s fighting (most stores are closed there).
Do bring hearing protection. Disposable ear plugs will probably suffice. You might not wear them in the field, but if you find yourself on a firing range without them, you’ll wish you’d found room for a couple pairs…
Do bring a Camelbak or canteen. Bottles of water are currently easy to find except in the areas with the most active fighting, but they are hard to carry. Personally, I have never used my Camelbak because (a) I feel guilty having it when none of my Ukrainian buddies do, and (b) a lot of the time, there isn’t enough drinking water available to fill one anyway. But, my canteen does travel with me–it’s wearable, and small enough that I can usually fill it.
Fireproof/fire-resistant clothes are always a good idea… That said, I don’t know how to buy them without spending phenomenally large amounts of money, and I have exactly no fireproof clothing whatsoever… If you have some insight into this, please tell us about it in the Comments section.
Heavy gloves, tactical or otherwise. No matter what your job is, you’re likely to be moving large amounts of humanitarian aid, and if you are doing hot extractions, there will be rubble everywhere. Hand injuries are actually the thing that I have treated the most here–avoid them if you can.
Do bring tactical pants. You will want to carry some things on your person at all times, such as your passport. My 5.11 Defender jeans have held up OK here, but my tactical pants are definitely more practical.
Do bring shirts that you can wear comfortably under body armor. That means a pullover shirt with a smooth front and no pockets. Rationale: things on the front of your shirt can get pretty uncomfortable when your armor has been pressing on them for a few hours. Probably obvious to you younger kids, but definitely not to us old guys who grew up wearing Vietnam-era jungle fatigues with those four big, baggy pockets on the front.
Do invest in some merino wool clothing. See above regarding how long it takes for 100% cotton garments to dry here…
Do bring clear ballistic glasses. Everyone knows to bring ballistic sunglasses, but clear glasses are crucial in unlit buildings (there is highly unlikely to be electricity in buildings from which people need to be evacuated) and at night. Ophthalmological surgery materials are in short supply here… Much wiser to just wear your fucking eye protection.
Do bring your heavy-duty belt. We might need to drag you to safety by it… If you have a shooting belt with MOLLE attachments, it wouldn’t be a terrible idea to bring it–who ever has enough space on their plate carrier to clip gloves, ballistic glasses, a Leatherman, a magazine pouch full of snacks and cigarettes…?
Do bring full kit! Be careful about export restrictions, e.g. for night vision goggles. The Polish Customs officials are absolute assholes–they even confiscated a buddy’s IFAK (tactical first aid kit).
Do bring patches. People love to know that Americans support Ukraine, and of course soldiers will want to trade them.
Do bring a shemagh if you normally wear one. I often give mine away as a present, and then I miss it until I can find another one… If you don’t know what a shemagh is: you don’t need to bring one.
Do avoid bulk whenever possible. Depending on what your job is, you might spend a lot of time getting in and out of tight vehicles, spaces, etc.
Do bring a poncho/poncho liner.
Do inform yourself about the typical weather during the period when you will be incountry, but don’t assume that you know where you’ll be. Life is unpredictable here, and many foreign volunteers find themselves in multiple regions of the country even during a relatively short stay.
This feels less to me like a war of one country against another than of the Russian army versus a bunch of defenseless grandmothers…
This message from a friend who is volunteering as a medic in Ukraine showed up in my Inbox the other day…
Yes, I’ve been in Ukraine since the beginning of May. I’m a medic, as I was in the Navy. You asked about my safety. “Safe” is a very relative concept… When I’m not in the field, my morning routine consists of making a cup of coffee, grabbing a pack of cigarettes, and then sitting on the balcony to watch the morning rocket attack on my entirely residential neighborhood. I say “morning rocket attack” because there has been one almost every day since I got here. Probably sounds horrifying, but since the only people carrying guns around here are soldiers, I actually feel safer in the city than I do in the US. When I’m in the field, it’s a different story. I mostly do evacuations of civilians from the front. The Russians enthusiastically shell refugee collection points and clearly marked emergency vehicles, and evacuating civilians from the front means going to refugee collection points in clearly marked emergency vehicles. As it happens, I have a relatively high tolerance for danger, so although it’s certainly not “safe,” that’s fine. What’s not OK is that because the Russians hit those places and vehicles so hard, and by this point a large proportion of the people who have not yet left the front are old folks, this feels less to me like a war of one country against another than of the Russian army versus a bunch of defenseless grandmothers…
English notes
in the field: In a military context, this means being out doing whatever it is that you do. Examples:
Your service member is headed out into the field and it looks like the entire military gear issuing office is located in your living room. No matter what their training mission might be, they will want to prepare and pack a few things for the field that will make things a little bit easier while they are “work camping.” These are things that have been suggested by actual service members who have been in the field for countless hours, days, weeks, and even months. Source: 35 things every service member needs for the field, from the Daily Mom web site.
A good razor with a shave gel that protects throughout the day is key for a service member who is shaving in the field. Source: the Daily Mom web site.
/
The picture at the top of this post shows old women sheltering in the basement of the refugee collection point in Lysychansk, in the Donbass region, during an artillery strike. My friend spent the attack outside, listening to debris bounce off of his helmet with every hit. The Russians eventually flattened the collection point. The picture is a screen shot from this video by documentary filmmaker Marharyta Kurbanova, a member of my friend’s team.
I received this photo and the accompanying note from a friend who has been evacuating civilians in the Donbas region of Ukraine.
I’m not much of a picture-taker— pulling out a camera here feels sordid, and I’m not sure that I would want to remember anything about this experience anyway. But, this struck me. In a small town looking for a place to pee—there’s been no running water here for a long time, so it’s better to do your business outside—I came across a bunch of rusting barbed wire with vines grown around it. I saw those vines as a material reflection of just how many years the people in the region have been under attack: not since February 24th, but for eight years now.
It’s one thing to do something bad—we all fuck up sometimes. It’s another thing altogether to PERSIST in doing something bad. Eight years—that’s a lot of persistence in doing something bad.
Untreated anxiety in children is associated with all sorts of bad things later in life. The good news is, if you do treat it, it can usually clear up.
Untreated anxiety in children is associated with all sorts of bad things later in life–mood disorders, alcohol and drug abuse, suicidality, underachievement in school, and low earning potential. The good news is, if you do treat it, it can usually clear up.
It’s usually easier to prevent something than it is to treat it, so it would be great if we could predict which kids are likely to develop chronic problems with anxiety, and head it off at the pass. That might actually be plausible, since anxiety has a trajectory of development. As Strawn et al. put it, “…the adolescent with panic and generalized anxiety disorders was once a boy with separation anxiety disorder and…a toddler with extreme shyness…”
But, how would one do that prediction?
(If you’re mainly here to improve your English, you will find an explanation of head it off at the pass in the English notes at the end of this post.)
I am a happy practitioner of the write-about-what-you-don’t-know approach to scribbling. Right at this moment I am realizing that I don’t know very much about the development of anxiety in children and adolescents. So, I am reading the paper Research Review: Pediatric anxiety disorders–what have we learnt in the last 10 years?, by Jeffrey Strawn, John Walkup, and a bunch of other folks. It describes a number of risk factors for the development of a variety of anxiety disorders. The risk factors fall into categories of cognitive bias, behavioral tendencies, family environment, parental disorders, substance abuse, and environmental exposure.
When I’m trying to understand a new disease, I sometimes play this game: walk into a restaurant, look around, and pick out the person most likely to suffer from it. (At my advanced age, that is often me, but that’s another story.) For the kinds of risk factors that are related to pediatric and adolescent anxiety disorders, that’s not really an option, so instead, I’m trying something different: I’m writing about some kids who I would expect (based on my limited knowledge) to develop anxiety–or not. So, here’s what we’re gonna do today: we’ll look at my little vignettes, say for each one whether we think the kid is at high risk or low risk of developing an anxiety disorder, and then explain why. I have written these vignettes in the style of the notes that a physician (doctor) writes when they examine a patient. That’s why it sounds odd. (We’ll talk about some of those oddities in the English notes.) Ready? C’est parti.
John is a 5y3m-old male with an uneventful medical history. He is referred to the psychiatry clinic because of bursts of tears and screaming when dropped off at school, persisting into the third week of the school year. He is in his third foster home since his mother was hospitalized for anxiety and depression six months ago.
Reminder: this is not the story of a real child. I have made it up myself for educational purposes.
Likely outcome? John is at high risk of developing an anxiety disorder. His behavior at school–not wanting to be dropped off even after three weeks from the beginning of the academic year–is a kind of behavioral inhibition, and behavioral inhibition is a risk factor for later development of anxiety disorders. Childhood separation events are, too, and John has experienced these multiple times–first with the long and continuing hospitalization of his mother, and then due to repeated changes of foster care placements. Having a parent with an anxiety disorder or depression also increases a child’s risk of developing an anxiety disorder, and John’s mother has both of those–that’s why she’s been hospitalized for so long.
Mary is an 8 year old healthy-appearing female. She is referred to the environmental health clinic after routine screening at her school suggested a high probability of lead and mercury exposure.
Mary lives with her paternal grandmother since her mother was imprisoned for sale of controlled substances and child endangerment and her father died in an automobile accident soon after. The grandmother seems quite controlling, but reports that she has changed household routines in response to Mary’s fear of sleeping alone.
Reminder: this is not the story of a real child. I have made it up myself for educational purposes.
Probable outcome? Mary is at high risk of developing an anxiety disorder. Exposure to environmental contaminants increase a child’s likelihood of developing subsequent problems with anxiety. Like John, she has experienced multiple separation events, with her mother being sent to prison and her father dying soon after. Over-controlling parenting, such as she is getting from her grandmother, also increases the risk of developing an anxiety disorder. “Family accommodation,” or changes made to group behavior in response to a child’s early anxiety symptoms, also increase the likelihood of developing an anxiety disorder, so despite the use of “but” in the example, this is not a good thing for this kid.
Harry is a cheerful, outgoing adolescent who presents in the Emergency Department with exquisite point tenderness in the right femoral area after a fall experienced while practicing his newly-discovered passion for rock-climbing. His father died in Iraq when John was six months old. His mother remarried two years later, and she reports that John has been close to his stepfather ever since. He denies alcohol, drug, or tobacco use.
Reminder: this is not the story of a real child. I have made it up myself for educational purposes.
What does the future hold? Harry is at low risk of developing an anxiety disorder. He clearly does not have a fear of trying new things, and is not shy. Although he lost his father, it happened so early in his life that he probably did not experience it as a separation event–recall that his father was deployed to Iraq–and he has always had a close relationship with his stepfather. The lack of alcohol, drug, or tobacco use is relevant in that these kinds of substance abuse (and I say that as someone who cheerfully enjoys fine American tobacco products) are often associated with anxiety disorders.
English notes
To head something off at the pass:to take action in order to prevent something from happening. This is a cowboy thing: a pass is a narrow path at a low point in a mountain range that lets you get through the mountains without having to climb them. You can prevent someone from getting somewhere that they’re trying to go if they have to go through a pass to get there–they’re narrow, and therefore easy to block. Some examples of the use of this expression:
Dilbert tries to head off criticism of Trump at the pass by defining it as coming from some “other side.” (Source: Twitter)
The apologists for Trump & Trumpies sure managed to tone down his rhetoric & head off his bigotry at the pass, didn’t they. (Source: Twitter)
How I used it in the post: It’s usually easier to prevent something than it is to treat it, so it would be great if we could predict which kids are likely to develop chronic problems with anxiety, and head it off at the pass.
Now let’s look at some of the odd aspects of medical English:
to refer to: in this sense, to refer someone to a treatment facility is to send them to that facility for consultation by a specialist. Your insurance company will usually require you to have a referral from your primary care provider for this kind of thing. How I used it in the post:
He is referred to the psychiatry clinic because of bursts of tears and screaming when dropped off at school
She is referred to the environmental health clinic after routine screening at her school
to present with something: this expression is used to describe a patient’s state when first meeting with a health care provider. How I used it in the post:
Harry is a cheerful, outgoing adolescent who presents in the Emergency Department with exquisite point tenderness in the right femoral area after a fall experienced while practicing his newly-discovered passion for rock-climbing.
In which language displays interesting statistical properties, some people get fired, and I learn a few words about the Army.
Twenty-plus years ago, I got my first job as an actual, card-carrying linguist, working for a company that did things with big collections of linguistic data, using them to improve computer programs that did speech recognition, i.e. figuring out what words a person is saying.
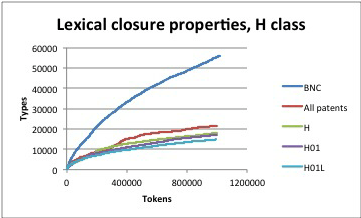
One fine day the people that gave us the vast majority of our income sent their big-collection-of-linguistic-data specialist to visit us. We demonstrated to him the computer program that we had built to answer the question how can you tell when a big collection oflinguistic data is big enough? We pointed out how to spot the tell-tale sign on a graph that means “it’s big enough.” “Oh, that just means that linguistic data is bursty.”
The blue line shows a big collection of linguistic data that is not nearly big enough. The other lines show big collections of linguistic data that are big enough. The telltale sign: a line that has gotten flat. Picture source: Irina Temnikova, Negacy Hailu, Galia Angelova, and K. Bretonnel Cohen. “Measuring closure properties of patent sublanguages.” In Proceedings of the International Conference Recent Advances in Natural Language Processing RANLP 2013, pp. 659-666. 2013.
What did he mean by “bursty?” We had a guess, but weren’t exactly sure, and given that his company paid us a lot of money and he was their expert, my boss thought it best not to push back. A few months later, they declined to renew our contract, and our owner laid everyone off and went away to do something else. Was it because we didn’t push back on the big-collection-of-linguistic-data expert’s dismissiveness? Probably not–our little company committed far bigger errors, and on a sadly regular basis. Whatever–the job market for computational linguists was not terrible in those days (it’s pretty wonderful now), and I found my second job as an actual, card-carrying linguist pretty quickly. But: burstiness is pretty important, and it continues to bump into my life today, in various and sundry ways, some of which will be of interest to readers of this blog.
What burstiness means: per Wikipedia,
In statistics, burstiness is the intermittent increases and decreases in activity or frequency of an event.
In plain English: burstiness is present when something doesn’t happen for long periods of time, but then happens a lot, and then goes back to not happening very often. Some things that have this characteristic: hurricanes, and pandemics. Statisticians care about burstiness because bursty things are difficult to characterize with normal statistics, so you have to come up with new techniques to work with them; people like disaster planners and public health experts care about those statistics because it is difficult to predict, and therefore to plan for, things that have weird statistical properties.
From a computational linguist’s perspective, burstiness is important because in big collections of language, you don’t see new words very often, but when you do, sometimes you see a lot of them at once. If you’re trying to do something like build a dictionary for a computer program, you typically do that by finding all of the words in a big collection of linguistic data. But, how do you know when your collection of linguistic data is big enough? See above; the problem is that if you kept growing the collection, you know that there will be bursts of new words, but you can’t keep growing your collection forever–at some point, you have to stop and work with what you have at hand.
Many of our dear fellow readers are engaged in learning a language that they don’t already speak. I am one of them–if you have been reading this blog for a few years, you have followed my feeble attempts to learn la langue de Molière, also known as “French.” By now I know the language well enough that I can pick up a book in it and not have to turn to a dictionary very often. But, when I do, it typically happens like this…
Right at this moment, I’m reading Paris brûle-t-il ?, “Is Paris burning?,” the work of reference on the liberation of Paris. I typically get through about three pages before I have to look up a word. But, then this morning, I’m reading about the French 2nd Armored Division rolling from Normandy to Paris when I come across this sentence. I had to look up all of the words in bold face:
Glissant en silence sur leurs six roues de caoutchouc, les automitrailleuses des spahis à calots rouges, “chiens de chasse” de la division, ouvraient la marche.
Dominique Lapierre and Larry Collins, Paris brûle-t-il ?, published by Robert Laffont in 1964.
l’automitrailleuse: a light armored vehicle.
le spahi: native cavalry trooper of the Maghreb.
le calot: garrison cap in English; when I was in the Navy, we called them “cunt caps.” A calot has no brim or visor, and therefore can be folded flat and tucked under the epaulet of a military jacket.
A Russian garrison cap, or calot in French, pilotka in Russian.
After that, it was back to my normal rate: about one word every three pages. That certainly counts as “not very often,” and is pretty good for a non-native speaker. To then jump to three words in a single sentence, and then go back to my base rate of one word every three pages, is a good example of burstiness. Once again, we see why one might right a blog like this one–a blog about the statistical properties of language and their implications for people who are trying to learn one. What happened to the dismissive big-collections-of-linguistic-data expert? I don’t know for a fact, but I do know that people who are dismissive of the opinions of others don’t typically have much professional success. Personally, I took what I learned from the experience of working at a failed software start-up to do a better job of being a computational linguist, and have had a wonderfully fun time with it. Want to try a career in computational linguistics yourself? Start here if you are not a graduate student, or here if you are, and I hope you have as much fun with it as I have!
French notes:
Despite what its name would lead one to think, an automitrailleuse does not necessarily carry a machine gun. Here some pictures of modern automitrailleuses. You’ll notice that some of them look a lot like tanks. The salient differences are that (1) they weigh less, and (2) they have wheels, not treads.
My first language is (American) English, but I speak French well enough that if I want French people to believe that I’m an American, I have to convince them of it. Comparing and contrasting French and American political appartenances helps, as does my ability to explain the difference between felonies and misdemeanors and how they affect the length of your prison sentence. Why it doesn’t occur to me to just speak English with them, I couldn’t tell you–I’ll have to try it some time…
My ability to speak French well doesn’t mean that I don’t make absolutely stupid mistakes, though. Case in point: propreté and propriété. One means “cleanliness” and one means “property,” but if I need to say either “cleanliness” or “property” in French, which of those two words propreté and propriété will come out of my mouth is pretty random. How random? I’d guess a 50/50 chance for either of them. So, how often do I say the right/wrong word? Let’s figure it out.
First, we have to make some assumptions. Assumption #1: the probability of me needing to say cleanliness and the probability of me needing to say property are equal. If we don’t make that assumption, then we have to adjust the calculation of how often I say the wrong word to account for how often each of those two words get said. By me. In French. Complicated? Yes. Hence: Assumption #1.
Assumption #2: the probability of me saying the right word and the wrong word are equal. Otherwise, we have to adjust our calculations of how often I say the wrong word to account for different probabilities for each. By me. In French. Complicated? Yes. Hence: Assumption #1, and Assumption #2.
With those assumptions in place, let’s figure out the possible outcomes in a situation where I need to say one of those words: “cleanliness:”
I need to say “cleanliness” and I say propreté (the right word)
I need to say “cleanliness” and I say propriété (the wrong word)
We have two possible outcomes (that’s the technical term), so the probability of either of them is 1/2, or 0.50, or 50%.
It works the same way if I need to say “property”–there are two outcomes:
I need to say “property” and I say propreté (the wrong word)
I need to say “property” and I say propriété (the right word)
Back to our original question: how often do I say the right/wrong word? Well… we need to change the question. To wit: to know how often I say the right/wrong word, we would need to know the probability of me saying every word that I say, and calculate the probabilities of me getting them right/wrong.
However: I don’t give a fuck about that. What seems funny to me about the fact that I am equally as likely to fuck up the words cleanliness and property is that they’re so fucking…common. I mean, I don’t have a problem with the vocabulary for talking about, say, why we have the Electoral College or why Beaux Arts Victorian houses aren’t built any more, but I can’t talk about the fact that if my little corner of New Orleans gets flooded in the next couple days, I am going to have some hot, sweaty, bug-infested work ahead of me as soon as I can get a plane ticket back there. Yes, friends and family: I am safe and sound in Colorado.
Note to self: propreté is pretty close to propre, “clean”–maybe that can help me remember? And for practice (just in case writing this blog post wasn’t enough), here are some sentences to practice with, courtesy of the Sketch Engine web site, your home for fine linguistic corpora and the tools for searching them. Scroll down for the answers:
Je suis en train de vendre ma ______.
Il y a des efforts à faire concernant la ______ de la piscine.
Comment conserver la ______ d’une salle de bain ?
Dans les années 60, on a étudié les ______ de trous noirs.
La couleur blanche est rattachée généralement à la pureté et à la ______ .
Balai vapeur hyper polyvalent – pour plus de ______ dans la maison !
Ton corps même n’est pas ta ______ ; comment pourrais-tu posséder le Tao ? (See Taoist scripture for an explanation.)
Les jeux vidéo ne sont pas la ______ exclusivede ces hommes blancs cishétéros.
Les oreilles : vérifiez régulièrement la ______ des oreilles de votre chien.
Actuellement la ______ appartientà la commune.
Tous les jeux flash présent sur le site restentla ______ de leurs auteurs respectifs.
Votre langue, cher monsieur Walder, est révélatrice de l’état de ______ du sexe de votre femme, point barre.
Les sanitaires sont d’une ______ immaculée et il y a même des machines à laver.
…les métaphores qui transposent certaines ______ d’une catégorie à une autre : “l’homme est un loup pour l’homme”…
Entretien des trottoirs : Chaque Soiséen est responsable de l’état de ______ du trottoir qui borde sa______.
Nettoyage: Les frais de nettoyage (50,00 Euros) vous seront rendus à la fin de votre séjour selon l’état de ______ de la ______.
Un matériau aux multiples ______ – résistance, ultra______ – et qui s’adaptent aux dimensions de vos projets.
Il n’a cependant pas les ______ ou la ______ du biométhane naturel.
Il y a des efforts à faire concernant la propreté de la piscine.
Comment conserver la propreté d’une salle de bain ?
Dans les années 60, on a étudié les propriétés de trous noirs.
La couleur blanche est rattachée généralement à la pureté et à la propreté .
Balai vapeur hyper polyvalent – pour plus de propreté dans la maison !
Ton corps même n’est pas ta propriété ; comment pourrais-tu posséder le Tao ? (See Taoist scripture for an explanation.)
Les jeux vidéo ne sont pas la propriété exclusivede ces hommes blancs cishétéros.
Les oreilles : vérifiez régulièrement la propreté des oreilles de votre chien.
Actuellement la propriété appartient à la commune.
Tous les jeux flash présent sur le site restent la propriété de leurs auteurs respectifs.
Votre langue, cher monsieur Walder, est révélatrice de l’état de propreté du sexe de votre femme, point barre.
Les sanitaires sont d’une propreté immaculée et il y a même des machines à laver.
…les métaphores qui transposent certaines propriétés d’une catégorie à une autre : “l’homme est un loup pour l’homme”…
Entretien des trottoirs : Chaque Soiséen est responsable de l’état de propreté du trottoir qui borde sa propriété.
Nettoyage: Les frais de nettoyage (50,00 Euros) vous seront rendus à la fin de votre séjour selon l’état de propreté de la propriété.
Un matériau aux multiples propriétés – résistance, ultrapropreté – et qui s’adaptent aux dimensions de vos projets.
Il n’a cependant pas les propriétés ou la propreté du biométhane naturel.
English notes: In my defense, a big part of my problem, I would guess, comes from the fact that English has the word propriety. The Merriam-Webster web site gives these synonyms for it: decency, decorum, form. Examples:
Zipf, I’m not sure about the propriety of that example about the cleanliness of Mr. Walder’s tongue.
President Obama was the very *model* of propriety. Never once did he say or do anything to make America ashamed of him. (Source: Twitter)
Even inside the nation’s prominent law firms preparing to help President Trump wage a legal war challenging the results of the election, concerns are intensifying about the propriety and wisdom of working for Trump, the New York Times reports. (Source: a tweet from the San Francisco Chronicle)
Computational linguistics takes on the infected swamp that the World-Wide Web has become
In the late 1990s, I worked at a start-up. At the time, it was one of the 25 largest web sites in the world.
Why “largest web site,” and not “biggest web site?” English tends to use “big” to refer to physical objects, and “large” to refer to abstract concepts. Note that I said “tends to”–this is a statistical tendency, not an absolute.
Like a lot of people working for internet-related businesses or causes, we thought that we were making the world a better place. The World-Wide Web was going to democratize so much–access to information, democratization of everyone’s ability to communicate their message to a broader world.
20+ years later, we all realize that everyone includes a lot of assholes. From a former president of the United States to random evil-doers in the former Soviet Union, there are people who use the technologies that so many of us well-intentioned people worked so hard on to spread hate, to attack democracy, to spread lies.
Misinformation: things that are not true. Disinformation: deliberately created untrue things. Unlike a simple mistake, misinformation is widely spread about. Unlike a lie, disinformation is widely spread about, too. “Diffused,” if you prefer a technical term. “Propagated.”
People like me who had a hand in developing the kinds of technologies that assholes use to propagate misinformation and disinformation have–belatedly, I would say–begun to try to address the kinds of problems that we helped create. One of these is a shared task on detecting online misinformation. A “shared task” involves a bunch of computer-sciencey-types getting together to define a task–say, finding emails that would be relevant to a court case. They come to an agreement about the definition of the task, about the right contents for a shared data set on which to evaluation performance on that task, and a metric for evaluating performance on it. You put together a schedule, everybody goes off and builds a computer system for doing the task, you distribute the data, and on some agreed-upon date, everybody submits their systems’ output to the people who organized the task. Then everyone gets together for a workshop in which we compare systems, compare outputs, and see what we can learn from those comparisons.
A day or two ago, an email appeared in my inbox about just such a shared task. Its goal is to deal with misinformation on the Internet. That’s a pretty goddamn big thing to take on, though, isn’t it? So, the participants agreed on a subpart of the misinformation problem that is a bit more tractable:
The TREC Health Misinformation track fosters research on retrieval methods that promote reliable and correct information over misinformation for health-related decision making tasks.
Right away, we know some of the ways that the organizers have defined their hopefully-tractable task definition:
The word retrieval suggests that participants will be given a set of documents, and that their output should be documents from that set. This mimics the basic structure of the World-Wide Web: a set of documents (on a loose definition of the term “document”) that users search in order to find information.
The word health-related suggests that participants will not need to be able to deal with every possible kind of misinformation–only health-related misinformation. This makes the task considerably more (potentially) achievable, and given the amount of misinformation that has recently been spread on health-related issues such as the current global COVID19 pandemic, there is potential benefit to the world as a whole if it can be accomplished. (Notice how I snuck in there the inference that health-related is a word, not a something…more than a word? I don’t actually think that–just showing you how discourse works.)
Promote reliable and correct information over misinformation refers to a common aspect of any “retrieval” task (see #1 above): your system is expected to present not just a set of documents, but a ranked list of those documents. Think about it like the page of results that Google gives you when you do a search: you want the most relevant web page to be at the top of the page, not at the bottom, right? So, that’s what the shared task organizers are asking your system to do: rank correct information over misinformation. Of course, if all of the web pages that your system presents to the user are correct, then that is wonderful. (Normally only the top results are considered in terms of scoring your system’s performance.)
Want more details? See the TREC Health Misinformation Track web page. Note that all opinions expressed in this post are mine, and they especially do not represent those of TREC, the Text Retrieval Conference, an organization that has run shared tasks for…over twenty years now, wow… And if you feel like slapping a computational person of my advanced age for having helped to create the stinking swamp that the World-Wide Web has become: go for it. But, also recognize that computational linguists are trying to do something to…wait for it…drain that swamp.
The picture at the top of this post is from an article published by the New York Times on April 13th, 2020.
…and after all of that, now we can conjugate both consonant-initial AND vowel-initial intransitive verbs IN THE FIRST PERSON SINGULAR PRESENT TENSE ONLY. Persistence, persistence!
Want to learn how to conjugate verbs in French? No problem–you can look them up lots of places on line, you can buy a book on the topic at pretty much any train station in France, and the French Verb Forms app will give you many happy hours of practice. (Seriously, I use it often.)
Want to learn to conjugate verbs in a less-commonly-studied language? Good fucking luck. You have two basic options:
Get a “FLAS.” Foreign Language Area Studies fellowships fund students to do intensive courses in languages that the US has a national interest in having Americans know how to speak. (Seriously, it’s not a coincidence that they used to be called National Defense Foreign Language fellowships.) You either have the wonderful luck to be at a university that offers courses in your (relatively) obscure language of choice, or you snag a $2,500 summer grant to go take an intensive course somewhere. (Indiana University Bloomington is currently offering FLAS language courses in Akan, Bosnian, Czech, Dari, Estonian, Finnish, Georgian, Hungarian… You get the picture.)
Figure it all out for yourself.
Option #2, “figure it all out for yourself,” is the one that you pick if you are a bald old fat fuck such as myself who is not going to be getting a FLAS summer fellowship any time soon. Option #2 begins with figuring out what the characteristics of verbs are in your language of choice, such that those characteristics might affect how you go about learning to conjugate them. We worked our way through this in a previous post. I’ll sum up the outcome like this:
The main things that differentiate amongst verbs in Kaqchikel are…
Whether they are transitive, or intransitive
Whether they began with a consonant, or with a vowel
Last time we worked on consonant-initial intransitive verbs. This time, we’ll move on to vowel-initial intransitive verbs. First thing we need: a list of such verbs. To put one together, we’ll go through the glossary at the end of the only English-based Kaqchikel textbook that I know of: ¿La Ütz Awäch?, by R. McKenna Brown, Judith M. Maxwell, Walter E. Little, and Angelika Bauer.
I am simplifying the Kaqchikel transitivity situation quite a bit. This will not shock Americanists (linguists who work on the indigenous languages of the Americas).
-achik’
to dream
-ach’ixïn
to sneeze
-ajan
to brush, to sculpt
-ajilan
to count
-ajin
to be Ving (a progressive)
-ak’walan
to procreate
-aläx pe
to be born, to sprout
-animäj
to run from, to flee
-animajin
to escape, to flee
-anin
to run
-apon
to arrive there
-aq’ab’an
to rise before dawn
All of these verbs begin with -a because I started at the beginning of the glossary, and it happens to be in alphabetical order. But, the observant reader will also have noted that many of these verbs end with n. Is this significant? Probably, but I don’t yet know why.
Want to know how to pronounce these verbs? See this post on my adventures in learning the pronunciation of Kaqchikel consonants.
OK, we’ve got some vowel-initial verbs, and we did consonant-initial ones last time, so let’s compare them. We’ll start with the first person singular of the present tense. Last time we learned theprefix yi- for consonant-initial vowels; for vowel-initial ones, we instead use yin-. Let’s look at examples of them side by side, and then we’ll practice the vowel-initial variant using the same technique that we learned last time. Remember that you will look at the example, then cover the second column of the table and work your way down it row by row, doing whatever the example showed you to do.
…and after all of that, now we can conjugate both consonant-initial AND vowel-initial intransitive verbs IN THE FIRST PERSON SINGULAR PRESENT TENSE ONLY. Persistence, persistence!
The picture at the top of this page is of a Kaqchikel singer I like a lot named Sara Curruchich. You can buy her stuff on Apple Music, and I’m sure elsewhere, as well. Picture source: https://assembly.malala.org/stories/kaqchikel-artist-guatemala. No English or French notes today, but here is one of her songs–I’ll post the words in Kaqchikel and in Spanish below.
With commonly-studied languages, you can find books with page after page of verb conjugations. But, if you are trying to learn a less-commonly-studied language, you will need to put those together yourself.
Learning verb conjugations in any language requires memorization, practice, and more memorization. With commonly-studied languages, you can find books with page after page of verb conjugations; but, if you are trying to learn a less-commonly-studied language, you will need to put those together yourself. The process of practicing those conjugations is the same, though. I will show you a system here that I picked up from the textbook Português Contemporaneo, by Maria Abreu and Cléo Rameh.
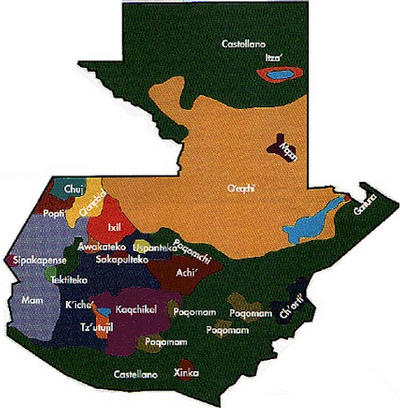
Kaqchikel is spoken in Guatemala, in the purple-colored region at the lower left of the map. Map source: online Kaqchikel Dictionary Project.
Being a big believer in writing about what you don’t know, I will illustrate the process with Kaqchikel, a Mayan language spoken by 400,00–500,000 people in the western highlands of Guatemala. There is an excellent textbook on Kaqchikel, called ¿La ütz awäch?, by R. McKenna Brown, Judith Maxwell, Walter Little, and Angelika Bauer. Other didactic materials are hard to come by outside of Guatemala, though–and in particular, there is no 501 Kaqchikel Verbs. (Fat old fucks such as myself grew up using books of verb conjugations with the standard title X01 [language name] verbs, where X is typically a 2 or a 5–for example, 501 French Verbs. They were published by a company called Barron’s. Still are, although I wouldn’t swear that they sell very many copies these days.) Hence: this post. Ready? Let’s do this!
Step One: Figure out what categories of verbs exist.
In Kaqchikel, that will be the following (at least to a first approximation):
Transitive verbs versus intransitive verbs
Verbs that start with consonants versus verbs that start with vowels
This is a very language-specific thing. Autrement dit: you have to do this for every language. In Spanish, the classes would be different:
Verbs that end with -ar in the infinitive, versus ones that end with -er and ones that end with -ir
Verbs that are regular in the tense that you’re learning, versus verbs that are irregular in that tense
In French, there would be so many categories that if a student working on an undescribed language told me that “their” language worked that way, I would tell them to go away and come back when they could prove it, ’cause languages like French just are not all that plausible. (The only similar one that I can think of is Dinka–1.3 million speakers in Sudan and South Sudan.)
Back to Kaqchikel… We’ll start with the intransitive verbs. (Left to my own devices, I prefer to start with transitive verbs, but the textbook that I’m using starts with the intransitives, and I’m gonna bet that the people who wrote the textbook known a hell of a lot more about how to learn Kaqchikel than I do.) The other thing that matters to us today is whether the verb starts with a consonant or with a vowel, and here I genuinely have no preferences, so we’ll start with the verbs that begin with consonants, just like the textbook does.)
Step Two: Pick a “person.”
I’m gonna start with the first person singular, i.e. “I,” because I know that that’s what my teacher will ask me about first. I am actually a fan of the third-person singular, i.e. “he/she/it,” when (trying to) learn a language where that’s a regular one. (The third person singular is not necessarily regular in any commonly understood sense of that word. It’s not difficult to find languages with over a dozen forms for the third person singular. Swahili (50-100 million speakers in East Africa–Swahili is so widely used as a lingua franca that it is difficult to know who to count as a speaker) is a common one, and has about 15, plus some more for plurals.)
So, the first-person singular of consonant-initial intransitive verbs: the marker is the prefix yi-. To practice it, I will put together a table like the following. The first row gives an example of what I need to do. You read it like this: when prompted with the verb wär, which means ‘sleep,’ add rïn yi- to it to make rïn yiwär, ‘I sleep.’ Then I have six repetitions. For each one, I cover up the answer, then do the thing, then uncover the answer to check whether I got it write. (Ummmm: right. Damn homophones…) Ready? Let’s do this shit!
Example: wär (sleep)
rïn yiwär
xajon (dance)
rïn yixajon
b’e (go)
rïn yib’e
tz’iban (write)
rïn yitz’iban
tzijon (to talk)
rïn yitzijon
käm (to die)
rïn yikäm
k’ask’o’ (to recover from an illness)
rïn yik’ask’o’
You see the system? Now I’ll try the second-person singular, i.e. “you.” This time, we’re going to add ratya-.
Example: wär
rat yawär
xajon
rat yaxajon
b’e
rat yab’e
tz’iban
rat yatz’iban
tzijon
rat yatzijon
käm
rat yakäm
k’ask’o’
rat yak’ask’o’
Second person singular present tense, vowel-initial intransitive verbs
Now it’s time to mix the two together:
rïn/wär
rïn yiwär
rïn/b’e (go)
rïn yi’b’e
rat/b’e (go)
rat ya’b’e
rïn/tzijon (talk)
rïn yitzijon
rat/tz’ib’an (write)
rat yatz’ib’an
rïn/käm (die)
rïn yikäm
rat/k’ask’o’ (recover from an illness)
rat yak’ask’o’
…and, then we add in the third-person singular, and we’re done for the day–plurals can wait until tomorrow. If you don’t want to slog through those with me, I’ll just point you towards these videos on the conjugation of intransitive verbs in Kaqchikel–if you do want to do some slogging, page down past the video links!
Videos about intransitive verb conjugation in Kaqchikel:
Videos about intransitive verb conjugation in Kaqchikel:
The picture at the top of this post shows eight Kaqchikel women from the village of San Marcos La Laguna, in the Lake Atitlán region. They were recipients of a micro-loan that enabled them to go into business selling the fabric that they make at home. Their clothes are the everyday wear of Kaqchikel women in that area. Picture source: here.