…and quantificational opposites relating expressions of quantity or expressions of part/whole relations:
et (and) versus ni…ni (neither…nor)
aussi (also) versus non plus (neither [in the sense of “also not”])
What does it mean to be an “opposite”? Let’s look up opposite in a few dictionaries:
diametrically different (as in nature or character) <opposite meanings> (m-w.com, definition 2.b)
being the other of a pair that are corresponding or complementary in position, function, or nature <members of the opposite sex>(m-w.com, definition 4)
Beingtheother of twocomplementary or mutuallyexclusivethings(thefreedictionary.com, definition 3)
What strikes me about this is that the definitions all refer to things in the world. However, I don’t know of any way to define a binary relation of oppositeness in the world, as such. Rather, oppositeness is a property of words. It’s what we call in linguistics a lexical relation–a relationship between two words, per se. So, in English, or at least in American English, it makes some sense to say that up is the opposite of down (the link goes to the antonym entry for up in WordNet), or that bad is the opposite of good (again, the link is to WordNet). But, these are relationships between the word up and the word down, between the word good and the word bad–there isn’t any clear way to define a notion of opposite between things, as opposed to between words.
We’ve talked a fair amount about ontologies in this blog–models of the things in the world and the relationships between them. If you look at ontologies–you can find hundreds of them here, all specializing in the biomedical domain–you’ll see that these models of things and the relationships between them have no notion of oppositeness. If you want to find the idea of oppositeness encoded, you have to look at models not of things, but of the words of a language, such as the WordNet entries that are linked to above. It’s entirely relevant here that many ontologists insist vociferously that WordNet is not an ontology. (Why you would wax vociferous over the question of what is and isn’t an ontology, I don’t actually know–there seems to be a certain religious element to the field…)
People act as if they think that other people have mental models that include some notion of being an opposite of something else. You can see this in metalanguage–talking about language (all quotes from brainyquote.com):
The opposite of talking isn’t listening. The opposite of talking is waiting. –Fran Lebowitz
I have a very strong feeling that the opposite of love is not hate – it’s apathy. It’s not giving a damn. –Leo Buscaglia
The opposite of bravery is not cowardice but conformity. –Robert Anthony
It strikes me as significant that Lebowitz, Buscaglia, and Anthony all are aware of oppositeness–but, they see it as something that you could be wrong about. This strikes me as an implicit awareness that oppositeness is not a property of the world–not something that you can measure, not something that you can quantify, not something that is obvious. If it’s not about the world, then what is it? Ultimately, being an opposite is a fact about the language that we use to talk about the world. We can talk about whether language has a role in reinforcing how we think about the world–does the fact that English only has two words referring to genders have the effect of constructing a binary opposition where there are actually many genders? Does language play into supporting dichotomies like colonizer/colonized, male/female, capitalism/Communism? Maybe. That doesn’t change the essence of the fact that oppositeness isn’t a property of the world. A property of systems, quite possibly–indeed, it’s a fundamental notion of structuralism, not just in linguistics but in the many relatives and descendants of structuralism in anthropology, sociology, literary criticism, psychoanalysis–on and on. Certainly we talk about those systems with language. But, that doesn’t change the fact that the opposites exist in how we conceive of and talk about those things–not in the things themselves.
Translating the word opposite from English to French is a tough one. There are different corresponding words for things, locations, directions–I stumble over them fairly frequently. One option for saying that something is the opposite of something else is l’opposé de or à l’opposé de. I don’t know when you would use one or the other. Here are some examples of each from the linguee.fr web site:
In fact, I think that taking life is the opposite of reproductive health.
Je pense d’ailleurs que la suppression d’une vie est à l’opposé de la santé génésique. (europarl.europa.eu)
The result is an attitude which is the opposite of true supporters and allies.
Avec pour résultat une attitude à l’opposé des fidèles soutiens et alliés. (esisc.net)
Red is the opposite of green, blue is the opposite of yellow and white is the opposite of black.
Le rouge est l’opposé du vert, le bleu est l’opposé du jaune et le blanc est l’opposé du noir. (thinkfirst.ca)
A “terroir” wine is the opposite of a technological wine.
Un vin de terroir est à l’opposé d’un vin technologique. (cave-cleebourg.com)
This is the opposite of what many people are now used to in other environments. fdisk(8) does not warn before saving the changes…
C’est l’opposé de ce que beaucoup de genspeuvent voir sous d’autres environnements. fdisk(8) ne demandera aucune confirmation… (openbsd.gr)
In this situation, branches are the opposite of “land rich and cash poor”.
Dans cette situation, les filiales sont l’opposé de ”riches en terrain et pauvres en argent”. (legion.ca)
The color example is a good one: Red is the opposite of green, blue is the opposite of yellow and white is the opposite of black.Red clearly isn’t the opposite of green in any scientific sense. Cultural sense? Sure. Blue and yellow? Not that I know of. Not even white and black? No–black has the same relation to red, green, and blue as it does to any other color.
I memorized the Learn French Avec Moi post on opposites–it’s a very useful linguistic concept. Check it out!
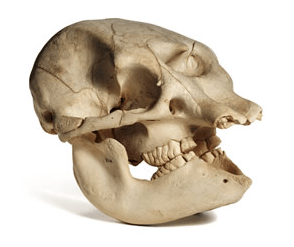
Two facts about chins: (1) Only humans have them. (2) No one knows why humans have them.
Two facts about chins: (1) Only humans have them. (2) No one knows why we have them.
The chin isn’t just specific to humans: it’s specific to modern humans. Earlier forms of us didn’t have them. I think it shows up around the time of Cro-Magnon Man, the earliest form of modern humans, about 45,000 years ago.
Homo erectus was around from about 1.9 million years ago until about 70,000 years ago. It’s probably an ancestral species to modern humans. No chin, though.
Neanderthals were around from maybe 250,000 years ago until about 40,000 years ago. I’m not clear on the arguments as to whether or not they’re ancestral to modern humans, but we probably inbred with them. No chin, in any case. (Note: I’m not a big fan of arguments that are only backed up by a single data point. For lots more pictures of Neanderthal skulls, go to Google Images. You still won’t find any chins.)
I’ve read that human infants don’t have chins, but rather they develop over the course of growth. From the skulls that I’ve looked at, this isn’t true–if you look at a human infant’s skull and the skull of any of a variety of apes, the human infant skull looks pretty distinct to me, in part because of the presence of a chin. A tiny, not-very-protuberant chin, sure–but, a chin nonetheless.
Do we really not know why modern humans have chins? We really don’t. Which is to say: a number of proposals have been advanced, but none of them is very convincing. Some of those proposals:
Chins protect the lower jaw from the mechanical stresses of mastication (chewing).
Chins protect the lower jaw from the mechanical stresses of speaking.
Chins are what is left behind after the rest of the face shortens over the course of human evolution. (Look at how far the adult chimp’s face sticks out in the series of drawings of human and chimp skull development; then compare the adult human face, which doesn’t stick out.)
Chins are meant to deflect blows to the face.
Chins come from unspecified “changes” related to reduction in testosterone levels over the course of human evolution.
None of these is a great explanation; some of them are very bad explanations; all of them are difficult to test. For some approaches to thinking about these various and sundry proposals, see any of these pages:
Some relevant French vocabulary for talking about the chin:
le menton: chin.
mentonnière: Although I can’t find this in the dictionary as an adjective, I think that it can be: Le mouvement volontaire de saillie mentonnière est assurée par l’extrémité de la sous-unité corporéale de l’os mandibulaire et par le muscle releveur du menton (aussi nommé houppe du menton ou incisif inférieur). “The voluntary movement of chin-projecting…” Can a native speaker verify this?
la mentonnière: chin-piece.
By the way: as MELewis has pointed out, if you want to have this discussion in any sort of detail, it’s important to have a definition of “chin.” In fact, depending on how you define it, you might want to say that elephants have independently involved a chin. Here are some pictures: an elephant skull, a mammoth skull, and a mastodon skull. All three of them show chin-like structures.
Parsing, data mining, and encryption are not going to get you. That pistol in your nightstand might, though.
Every once in a while an innocuous technical term suddenly enters public discourse with a bizarrely negative connotation. I first noticed the phenomenon some years ago, when I saw a Republican politician accusing Hillary Clinton of “parsing.” From the disgust with which he said it, he clearly seemed to feel that parsing was morally equivalent to puppy-drowning. It seemed quite odd to me, since I’d only ever heard the word “parse” used to refer to the computer analysis of sentence structures. The most recent word to suddenly find itself stigmatized by Republicans (yes, it does somehow always seem to be Republican politicians who are involved in this particular kind of linguistic bullshittery) is “encryption.” Apparently encryption is now right up there with dirty bombs in terms of things that terrorists are about to use to kill us all. (“All” might be an exaggeration. I find it interesting that the United States had 33,169 firearm deaths in 2013–roughly 11 times as many deaths as on 9/11–and yet, Republicans seem to think that it’s important that we make firearms as widely available as possible. I guess they just don’t like people very much.) As a moderately technical person, this strikes me as odd, since I’ve always thought of encryption as that nifty mathematical technique (I was about to say “algorithm,” but I think the Republicans are down on that one now, too) that keeps you from intercepting my text messages, me from reading your Ashley Madison profile, and so on.
In between the Republican outrage over parsing and the current panic over encryption, we had the sudden appearance in the public consciousness of data mining. As far as I knew up to that point, data mining was a bunch of statistical techniques for finding relationships between things. Suddenly it was showing up in scary news stories–Google the phrase “data mining is evil” (you have to put the quotes around it to search for the phrase, as opposed to the individual words) and you will get 1,400 hits as of the time of writing (May 2016).
Besides being bemused by this intrusion of American know-nothingness into public discourse, I have a personal stake in the issue, because people often refer to what I do for a living as text data mining. This is a misnomer–by its nature, data mining is not something that you can do with texts. Bear with me and I’ll explain why, and then we’ll look at some French vocabulary for talking about all of this.
Data mining is basically about databases. In a database, the statistical techniques of data mining can help you do things like discover that Republicans with HBO subscriptions are more likely to consider voting for Romney in a primary than Republicans who don’t have HBO subscriptions. (Real one, if I remember the facts correctly.) You can do that because you have a table in the database that tells who’s a Republican, a table that tells who has HBO subscriptions, and a table that tells you which members of a random sample told the interviewer that they would/wouldn’t consider voting for Romney in a primary. Data mining is the science/art of figuring out what things are related (HBO subscription/willingness to vote for Romney) and what things aren’t related (making one up here: having bought an Escalade and being willing/unwilling to vote for Romney in a primary)–this among probably thousands and thousands of variables. Doing data mining research requires things like knowing particular kinds of math, understanding how to sample a population, getting computers to do complicated calculations in a way that is time-efficient—stuff like that.
With data mining, you have that database, and you know what everything is. With “text mining,” or “text data mining,” as some people call it, you have texts, and you don’t know what anything is. (By “you,” I mean a computer program.) This is usually talked about as a difference between “structured” data (i.e., the database)–you know what everything “is”–what it “means”–in some sense, its semantics. Whoops–that sentence got a little out of control. “Unstructured” data: that’s typically how we would describe text. With text, you know what nothing is–you don’t know what anything means–in a very literal sense, you don’t know its semantics.
“Text mining” could be thought of as turning unstructured data into structured data. You’ve got a bunch of texts, and you want to use it to populate a database, perhaps. Maybe you have 23 million journal articles in the National Library of Medicine, and you want to find every statement that those 23 million articles make about which genes are affected by which drugs. Maybe you have a huge collection of French fairy tales, and you want (the computer) to find every time that a stepmother is mentioned and whether the portrayal of the stepmother is positive or negative. You could think of both of those as turning unstructured data into structured data–you’re taking that unstructured data and using it to build a database about drugs and proteins, or a database about stepmothers. You can see now why we tend to prefer the term “text mining” to “text data mining”–to the extent that “data mining” is about structured data, it doesn’t really make sense to talk about “data mining” with respect to language. Where the data mining person basically just needs to know math, the text mining person needs to know something about how people write about whatever it is that you’re interested in. I do a bit of text mining. People will have really specific requests–tell me whether or not the genes from some experiment show up in the cancer literature, say; tell me if this is a suicide note or not; read this doctor’s note and tell me if this kid is a candidate for epilepsy surgery; stuff like that. It’s not really linguistics, but it pays the bills, and it suits my need to do something that might actually make the world a better place.
A related field is natural language processing. Natural language means human language, as opposed to computer languages. Natural language processing is about building tools to handle specific linguistic tasks–parse a sentence, figure out parts of speech, stuff like that. You might use a combination of different language processing programs to do a text mining task. I find this more interesting, since the questions are less about some set of facts than they are about the language itself. Where the data mining person needs to know math and the text mining person needs to know how people write about genes and drugs, or stepmothers, or whatever, the natural language processing person needs to know something about language itself–what kinds of structures sentences can have, how word frequencies are distributed, how to build linguistic resources for letting a computer process things that can’t be directly observed (e.g. semantics). I do a lot of this kind of stuff. Recently I’ve been working on coreference resolution–how to get a computer to recognize that Obama, President Obama, and Barak Obama are all referring to the same thing in the world, while Mrs. Obama and Michelle Obama are referring to something else in the world. (Recognizing that those “things” in the world are people, as opposed to, say, locations, or the names of companies, is a whole different story.)
Yet another field is computational linguistics. This is about using computational models to test theories about language. This is my favorite, but it’s the hardest to pay the bills with. I do some of this, too. Nowadays a lot of my time goes into large-scale attempts to model the semantics of biomedical language. I’m trying to investigate differences in the semantic primitives of biomedical language versus “general” English by building a large set of data-driven semantic representations of predicates found in journal articles; I’ll then compare that resource to a similar resource built for general English and look for things like whether or not the semantic primitives seem to come from the same set, whether or not given verbs have different representations in the two types of language, etc. My hope is to get a sense of the range of types of semantic variability from this particular project. You could imagine using computational linguistics work to build natural language processing tools, and then using those to carry out practical text mining tasks. You could use the text “data” mining results to do actual data mining.
Mathematical representations of semantics can define how the gender binary gets manifested in English. This diagram transforms gendered word relationships into a map-like space. Pairs like girl/boy and aunt/uncle have the same “spatial” relationship. Picture source: http://www.offconvex.org/2015/12/12/word-embeddings-1/.
As you can tell from my examples, I’m very much in the world of biomedical language. There’s also a lot that you can do in the humanities with this kind of stuff. A hot topic in the future might be using mathematical representations of semantics to study things that are/are not thought of as binaries–gender, sexuality, race, political economy, whatever. However, I would not claim to do ANY of that–I can just barely explain it. For more on that kind of stuff, see this excellent post by Ben Schmidt.
In practice, even people in the field don’t always differentiate between these terms, or at least don’t draw sharp boundaries between them. My business card says that I’m the director of a text mining group, but I identify most strongly as a computational linguist. We figured that “text mining” makes more sense as a practical field of inquiry to have within a medical school (which is where I work), so that’s what we called the group when we formed it. If you go to the annual conference of the Association for Computational Linguistics, you will see almost no computational linguistics, but rather a ton of natural language processing. If you go to the annual Biomedical Natural Language Processing meeting, you’ll see a mix of text mining, natural language processing, and a bit of computational linguistics. Sometimes the distinctions really matter, though. This post started its life as a response to someone who asked me to be on a panel about data mining, to talk specifically about text data mining. When I responded that I don’t do data mining, they asked what the difference is–this blog post started out as my response.
As far as I can tell, the relevant community in France doesn’t make these distinctions in any kind of rigid fashion, either, despite the much-vaunted French penchant for categorization (see Nadeau and Barlow’s excellent book for a discussion of where it comes from). However, French does have technical vocabulary for all of these fields. Here it is:
fouiller: to excavate; to rummage through, to search (see also here)
la fouille de données: data mining
la fouille de texte(s): text mining
le traitement automatique des langues naturelles: natural language processing
la linguistique informatique: computational linguistics
La grande guerre, “The Great War,” the First World War, World War I, The War To End All Wars, was primarily fought in France. I can’t imagine how to talk about all of the ramifications of the effects of the First World War through French history, art, politics, even cuisine; certainly European history, and indeed, the history of much of the planet. It would be pretty fair to say that the European refugee/migrant crisis today is related to the fact that Germany is incredibly welcoming to refugees; that Germany is so incredibly welcoming to refugees today because it murdered millions of civilians during the Second World War; and that the Second World War came about in part due to the effects of the First World War. (You’ve probably heard it said that “the first shot of the Second World War was the Treaty of Versailles“–the codification of the German terms of surrender at the end of the First World War. The treaty contributed enormously to the German sense of humiliation that helped to build support for the next war in 1939.)
Military language has a very rich vocabulary of its own. It includes both technical language, and slang. The French military is one of the most highly developed in the world, and the French language has a rich military vocabulary. Here are some words that you would need to know in order to read about the First World War in French. Bear in mind that I have no idea how many of these are still in current use, or not. Can native speakers help? A couple of these are cavalry terms. France still had active cavalry units in the First World War, and Céline’s Bardamu in Voyage au bout de la nuitserves in a mounted unit.
la tranchée: trench.
le fourgon: ammo truck. In general French: a truck.
le dragon: A cavalryman. From the 8th edition of the Dictionnaire de l’Académie française: Il se dit aussi d’un Soldat d’un des corps de cavalerie de ligne.Il est dans les dragons.Régiment de dragons. Colonel, capitaine de dragons. Le casque d’un dragon. “It is also said of a soldier of a line cavalry corps.” I found this one as early as the first edition of the Dictionnaire de l’Académie française, published in 1694: On appelle, Dragons, Des arquebuziers a cheval, qui combattent tantost à pied, tantost à cheval.Les dragons d’une armée. une compagnie de dragons. Capitaine de dragons. “We call Dragons, mounted arquebus carriers, who fight sometimes on foot, sometimes mounted.” (Don’t you love that tantost, where current French has tantôt? See here for more from various and sundry historical dictionaries.)
le brigadier: a brigadier general. It can also indicate a corporal; I think this might be somewhat specific to the cavalry. Here’s part of the entry from the 6th edition of the Dictionnaire de l’Académie française, published in 1835: Il se dit maintenant Du militaire qui a, dans la cavalerie, le grade correspondant à celui de caporal dans l’infanterie.Brigadier de chasseurs, de dragons, etc. “It’s now said of the soldier who, in the cavalry, has the rangk corresponding to that of a corporal in the infantry.” Later, in Emile Littré’s Dictionnaire de la langue française, published between 1872 and 1877, we see this: Titre donné au soldat revêtu du grade le moins élevé dans la cavalerie. “Title given to the soldier decorated with the least elevated rank in the cavalry.” (See here for more from various and sundry historical dictionaries.)
I write about (or at least allude to) the statistical behavior of language quite a bit in this blog. After all, it takes its name from Zipf’s Law, which was originally an observation about the behavior of language. We’ve also talked a fair bit about the Poisson distribution and how we can use it to understand why some days a second language learner is going to feel like they have made no progress whatsoever.
In these discussions, I’ve pretty much always ignored a basic fact about language. It’s not always a bad thing to ignore this fact, and we can actually get computers to do quite a bit of fun/useful things with language even when we ignore it. However, it is a fact nonetheless. Most statistical models (not just of language, but of anything) assume that samples are independent: that is, that having made any one particular observation has nothing to do with any other observation. However, when you’re talking about words, this is probably never true. (I tend to avoid the words never and always when talking about language, but in this case, “never” might actually be appropriate.) Rather, the probability of any one word is typically related to the presence of other words. Let’s take an example: bark and dog. Both of these are words that are relatively infrequent in English, as compared to, say, the, or and. From a statistical point of view, they’re actually pretty rare. Intuitively, however: if you’ve already run into the word dog, then it’s not quite as surprising if you run into the word bark, and vice versa. The same doesn’t hold for avocado–running into the word dog (or bark) wouldn’t make it seem much more likely to run into avocado than if you hadn’t just seen the word dog or the word bark.
We can quantify this statistical relationship without too much difficulty. I’m going to take some liberties here, so my apologies to my language peeps out there.
Let’s look at the frequencies of some words in a big sample of the English language: a collection of just over 96,000,000 words of English called the British National Corpus.
The frequency of the word bark in this collection of English as a whole is 11.8/million words. That is to say: for every 1 million words in the collection as a whole, 11.8 of them are bark.
Now let’s take just the sentences that contain dog. (There are about 12,000 of them.) If we look at just the sentences that contain the word dog, the frequency of bark changes quite a bit: it is now 1,073 per million words. The frequency of bark is not independent of dog: if we don’t know anything about the surrounding words, the frequency of bark is 11.8/million words. On the other hand, if we know that the word dog is nearby, then the frequency of bark is 91 times higher–1,073 per million words, versus just 11.8/million words. We say that bark and dog are not conditionally independent. Rather, the frequency of bark is conditionally dependent on the presence (and probably absence, but I haven’t demonstrated that) of dog.
The thing is this: there is pretty much never conditional independence when you’re talking abut words. Rather, the probability of seeing any particular word is related to the words that occur around it. This is true on the level of sentences, and it’s also true on the level of situations–it’s not an accident that when I run into new French words, I tend to run into other new French words that are related by, say, subject matter.
All of this came up today when I found myself repeatedly looking up words in order to be able to read the morning’s emails, and found that many of them contained the French word merde, or “shit.” Somebody did something that they shouldn’t have, it pissed somebody else off, and soon the emails were flying fast and furious. Here are the shit-related words from my day’s email, plus some related words that I came across while looking them up. All examples are taken from my correspondence:
démerder: to figure out, to work out.
se démerder pour: to manage. Je le laisse se démerder. “I’ll leave him to figure it out.”
merdique: shitty; hopeless, useless. …leur responsabilité dans cette affaire merdique. “…their responsibility in this shitty business.”
There’s an implication here for how to study a language: the “structured vocabulary” approach that textbooks take, where you are introduced to a variety of words related to the same theme, works. When you get beyond the point where there are no textbooks for the level that you’ve achieved in a language, then other resources that bring together words on the same subject can be really useful to you. I like Mastering French Vocabulary: A Thematic Approach (Mastering Vocabulary Series), 2nd Edition, by Wolfgang Fischer and Anne-Marie Plouhinec. It separates the vocabulary of a domain into more central and more peripheral vocabulary, and also gives example sentences. However, there are many others. I am also a big fan of the Oxford-Duden pictorial dictionaries, and there’s a French-English bilingual one. They’re not quite as user-friendly as something like the Fischer and Plouhinec book–no verbs at all, and no examples of usage, and no indication of when words are ambiguous–but they are excellent for technical and obscure vocabulary.
I said above that words are probably never conditionally independent. I can think of one particular kind of language in which you might see something like conditional independence. This is the phenomenon of word salad.
Wikipedia defines word salad as a “confused or unintelligible mixture of seemingly random words and phrases.” Random is the key word for us here–if you are random, then there is no conditional dependence–that is, knowing that any particular word shows up tells you nothing about the probability of some other word showing up, just as picking up, say, a piece of lettuce when you’re eating a (tossed) salad doesn’t let you predict anything about what you’re going to pick up next. Here are some word salad examples from schizophrenics:
Yesterday, the neighbors arrived with a bushel of wheat. I can only hope that the children will receive their weekly bath. It seems to me that young Gracie has blue eyes. Snakes often have eyes. The grass is green as well. (http://pasadenavilla.com/2009/10/18/living-with-a-schizoprenic-patient-2/)
Back to the drama: the emails flew fast and furious for a while. Ultimately, the issue was decided by appeal to logic and the basic principle of égalité–equality. In this case, that meant that identical standards would be applied to everyone, which might sound obvious, but in a similar situation in the US, that would not necessarily be assumed to be the case, at all. (I say that after having seen similar situations in the US many, many, many times.) In France: you can get pretty far here by arguing for logic and consistency, as far as I can tell. Seems pretty sane to me…
What you get when you search for the lemma “dog” as a noun in the British National Corpus. “Lemma” means that it includes both the singular “dog” and the plural “dogs.” Picture source: screen shot by me.
Technical note: I got the initial frequencies for dog and bark through Sketch Engine. I saved all sentences containing dog in a Sketch Engine search as a text file. Then I counted the total words. I counted the number of lines containing bark, making the simplifying assumption of one token of bark per line. I then normalized the frequency to words per million.
Standard tourist question in Paris: is that Notre Dame? The short answer is usually no. One possible longer answer would be which Notre Dame? There are 37 churches in Paris called Notre Dame (Our Lady) of something or other. According the Wikipedia page listing religious buildings in Paris, there are 197 churches in Paris at the moment. That’s just in the 20 arrondissements of Paris proper. Even without bearing in mind the observation that French society can be aggressively anti-clerical, that’s a lot of churches.
Robert Cole’s explanation: as the year 1000 approached, everyone knew that the world was going to end. Prayer for the sparing of life was widespread, and when the world did not, in fact, end, gratitude was widespread as well. A spate of church-building was the result.
Should we buy this account? Clearly the churches of Paris are not generally anywhere near that old. Parts of Saint-Germain-des-prés go back 1000 years, and Saint-Julien-le-pauvre began construction in the 1100s, but most Parisian churches are at least a hundred years younger than that. So, you could call Cole’s explanation into question because of that. However, it’s also certainly the case that many Parisian churches are built on the sites of earlier churches, or are mostly additions to earlier churches, or are replacements for churches that burnt down, or exploded, or set on fire by Vikings (I’m not kidding about any of this), or what-have-you. So, there’s often some rationale for dating a church as being earlier than the current state of whatever you happen to see on the spot today. For example, the current Saint-Germain-des-prés is dated to 1014, but it replaced another church that went up on the same spot in 542. Saint-Julien-le-pauvre replaced another church built on the same spot in the 500s. Google oldest church in paris and it will suggest both Saint-Germain-des-prés and Saint-Julien-le-pauvre. It’s a difficult question. But, it’s not inconsistent with Cole’s story.
A personal digression: my very boring little residential neighborhood alone contains a Gallic Rite church–the somewhat-Celtic, somewhat Eastern Orthodox–and possibly somewhat Dark Ages French–Gallic Rite was abolished at some point (can anyone tell me when?), but later revived by Russian emigres in Paris in the early 20th century–and a wonderful Art Deco church. I always assumed that Art Deco was totally American–it turns out that Art Deco is short for Arts Décoratifs, and the style had its origin in France. Who knew? Personally, I don’t think that this list of the ten most unusual churches in Paris has anything on my little neighborhood.
For more information on millenialism in medieval France, see:
The typical stereotype of Paris is as a beautiful, majestically historical city that just oozes romance, and indeed, Paris is all that. But, visitors are often surprised to find that it is also a city with a sometimes astounding number of beggars on the street. The reasons behind this are many, and varied, and, I think, interesting.
In the pre-modern period, the vast majority of the French (like the vast majority of everyone else in the world) were farmers. Most children didn’t live to adulthood, and you needed a lot of hands to work the farm, so people had big families.
In the 1500s, the French death rate took a relatively sudden drop. People were still having those big families, so there were a relatively large number of people making it to adulthood. The inheritance laws of the time included primogeniture, i.e. inheritance of everything by the oldest son, so lots of those people wouldn’t have a farm of their own to work. Options were limited, and if they couldn’t find other employment, a lot of people hit the road. (There’s an excellent description of the mechanics of this phenomenon in Robert Darnton’s The Great Cat Massacre and other episodes in French cultural history.)
If you hit the road in France, you’re eventually going to end up in Paris, if for no other reason than that it’s the hub of the road system (and today, the rail system). If you can’t find other employment, your options come down to begging or stealing, and most people aren’t thieves. So: begging.
Begging actually has a very long and somewhat respectable history in Europe. As Robert Cole puts it: “In the middle ages, ‘Christian charity’ perceived the poor as God’s special children and therefore deserving of alms.” Begging can be a profession, really. (Old Eastern European Jewish joke: beggar hits a guy up for money. Guy gives him some helpful hints on improving his approach. Beggar responds: YOU’RE telling ME how to beg? This would make total sense in a French context: a métier (profession) is a métier, whether you’re a doctor, an engineer, or an elevator operator.)
If you’re gonna be a beggar, though, it helps to have a schtick. Physical lack of ability to work was a good one, and Parisian beggars were known for faking such a disability, leading to their squatting areas being known as Cours des miracles(“Courts of miracles”) for their recovery at the end of the working day. (There was one just to the north of what is now the Place des Vosges, I believe.) By the 1500s, begging wasn’t viewed quite as kindly. Robert Cole again:
In sixteenth-century Paris the poor were viewed as merely layabouts who preferred to live off public welfare. Meanwhile bad harvests, plagues, inflation and religious war increased their number dramatically. Public begging was outlawed in 1536, and in 1551 laws were enacted which limited eligibility for public assistance and forbad women to have their children in tow when selling candles outside churches. To do so, went the rationale, evoked sympathy from prospective customer, which proved that such women were really only begging. A traveller’s history of Paris.
So: there have been a lot of beggars in Paris for centuries. In 2007, the European Union was enlarged to include a couple countries with large Roma populations. There have always been Roma in France, but now a lot more came (the Roma rights group FNASAT says 12,000 currently, and that’s after 10,000 being expelled in 2009 and another 8,000 in 2011; other estimates range from 20,000 to 400,000), and they are a prominent part of the Parisian begging ecosystem. (There is, indeed, a Parisian begging ecosystem, and there are actually a number of distinct genres of begging in Paris–a subject in and of itself.)
To be clear: if you don’t give charity, your life is pointless. Let me point out that this is a teaching of at least Christianity, Judaism, Islam, and Hinduism, and–for my fellow secularists in France–Rousseau, the revolutionary Constituent Assembly, National Convention, and Directory, and modern French philosophers from Sartre to Alain Finkielkraut. (All of those links are to citations on the subject, not to their biographies.) The Buddhist view of charity is especially appealing to me, as a (really bad) student of judo:
Buddhism views charity as an act to reduce personal greed which is an unwholesome mental state which hinders spiritual progress. What Buddhists believe, Venerable K. Sri Dhammananda Maha Thera.
Judo’s view of the best human relationships is mutual welfare–we’re taught that human interactions should be mutually beneficial. So, if it’s the case that charity benefits both the giver and the receiver, then it’s very judo. Seriously, give charity–if for no other reason than that you’ll feel better about humanity if you take part in it being more humane.
le mendiant: beggar.
le gueux/la gueuse: beggar (literary). A number of other, more pejorative meanings–highwayman for men, whore for women, etc. Probably obsolete, but keep it mind for when you read Tartuffe.
le clochard: beggar; also bum. (Slang.)
le/la clodo: beggar; also homeless person, tramp, hobo.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}